Hunting For Manifolds
Larry Wasserman
In this post I’ll describe one aspect of the problem of estimating a manifold, or manifold learning, as it is called.
Suppose we have data 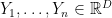

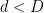
The first goal is to use the fact that the data lie near the manifold as a way of doing dimension reduction. The popular methods for solving this problem include isomap, local linear embedding, diffusion maps, and Laplacian eigenmaps among others.
The second goal is to actually estimate the manifold
I have had the good fortune to work with two groups of people on this problem. With the first group (Chris Genovese, Marco Perone-Pacifico, Isa Verdinelli and me) we have focused mostly on certain geometric aspects of the problem. With the second group (Sivaraman Balakrishnan, Don Sheehy, Aarti Singh, Alessandro Rinaldo and me) we have focused on topology.
It is this geometric problem (my work with the first group) that I will discuss here. In particular, I will focus on these two papers: here and here.
1. Statistical Model
To make some progress, we introduce a statistical model for the data. Here are two models.
Model I (Clutter Noise): With probability 
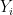

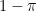

![{K = [0,1]^D}](https://s0.wp.com/latex.php?latex=%7BK+%3D+%5B0%2C1%5D%5ED%7D&bg=ffffff&fg=000000&s=0&c=20201002)

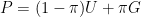
where 
![{[0,1]^D}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5ED%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Model II (Additive Noise): We draw 
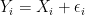
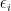



where 

where 

There are some interesting complications. First, note that 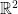

Our goal is to construct an estimate 
2. Hausdorff Distance
We will compare 

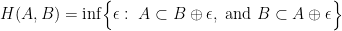
where

and 


Let’s decode what this means. Imagine we start to grow the set 

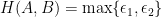

There is another way to think of the Hausdorff distance. If 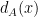
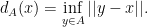
We call 
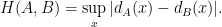
Using 
![\displaystyle R_n = \inf_{\hat M}\sup_{P\in {\cal P}} \mathbb{E}_P [ H(\hat M,M)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R_n+%3D+%5Cinf_%7B%5Chat+M%7D%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7D+%5Cmathbb%7BE%7D_P+%5B+H%28%5Chat+M%2CM%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where the infimum is over all estimators 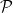
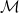
3. Reach
We will consider all 
The reach is 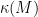
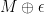
Consider a circle 

A plane has infinite reach. A line with corner has 0 reach. Here is a example of a curve


Requiring
The set of manifolds we are interested in is the set of 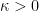

4. The Results
Recall that that the minimax risk is
![\displaystyle R_n = \inf_{\hat M}\sup_{P\in {\cal P}} \mathbb{E}_P [ H(\hat M,M)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R_n+%3D+%5Cinf_%7B%5Chat+M%7D%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7D+%5Cmathbb%7BE%7D_P+%5B+H%28%5Chat+M%2CM%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
In the case of clutter noise it turns out that
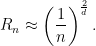
Note that the rate depends on
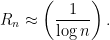
The latter result says that 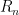
We can explain this by analogy with another problem. Suppose you want to estimate 
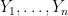

which is a nice, healthy, polynomial rate. But if we add some Gaussian noise to each observation, the minimax rate of convergence for estimating
Is there a way out of this? Yes. Instead of estimating 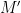
We are finishing a paper on this idea and I’ll write a post about it when we are done.
5. Conclusion
Estimating a manifold is a difficult statistical problem. With additive Gaussian noise, it is nearly impossible. And notice that I assumed that the dimension
However, none of these problems are insurmountable as long as we chnage the goal from “estimating
6. References
Fan, J. (1991). On the optimal rates of convergence for nonparametric deconvolution problems. Ann. Statist. 19 1257-1272.
Federer, H. (1959). Curvature measures. Trans. Amer. Math. Soc. 93 418-491.
Genovese, C., Perone-Pacifico, M., Verdinelli, I. and Wasserman, L. (2012). Minimax Manifold Estimation. Journal of Machine Learning Research, 13, 1263–1291.
Genovese, C., Perone-Pacifico, M., Verdinelli, I. and Wasserman, L. (2012). Manifold estimation and singular deconvolution under Hausdorff loss. The Annals of Statistics, 49, 941-963.

11 Comments
Just wanted to let you know that I really enjoy your blog.
Thanks!
Agreed! The blog has been mostly digestible by ordinary tech people (at least with one example to go off of). I had an easier time thinking of the stuff above in terms of dilation and erosion (like in computer vision), but since I was thinking of stuff as “growing” had to flip the definition of reach in my head (maximum \epsilon such that points do not have a unique projection).
Thanks!
How does an approach such as given in M. Soltanolkotabi and E. J. Candès. A geometric analysis of subspace clustering with outliers. compare with the approaches here?
If I remember correctly, they are looking for clusters
around linear subspaces.
(But I would need to check)
Larry, closely related two-dimensional problem was considered in the paper “Estimating trajectories” by Y. Chow in Annals of Statistics in 1986…
Thanks for the reference
LW
…just wondering if those slow rates have anything to do with the metric…I mean, Hausdorff is a good guy but it seems Wasserstein is gaining momentum…
–Pierp
Yes I think you are right.
The rate in Wasserstein would probably be faster.
LW
I’m wondering if you can provide a reference for your “errors in variables” comment on adding Gaussian noise to covariates. Thanks.
Fan and Truong (1993)
Annals of Statistics
p 1900-1925
http://projecteuclid.org/DPubS?service=UI&version=1.0&verb=Display&handle=euclid.aos/1176349402
2 Trackbacks
[…] Hunting for Manifolds – Normal Deviate […]
[…] Wasserman writes on Hunting for Manifolds. Given data that are close to some manifold, how do we estimate the underlying […]