Today, we have a guest post by Sivaraman Balakrishnan. Siva is a graduate student in the School of Computer Science. The topic of his post is an algorithm for clustering. The algorithm finds the connected components of the level sets of an estimate of the density. The algorithm — due to Kamalika Chaudhuri and Sanjoy DasGupta— is very simple and comes armed with strong theoretical guarantees.
Aside: Siva’s post mentions John Hartigan. John is a living legend in the field of statistics. He’s done fundamental work on clustering, Bayesian inference, large sample theory, subsampling and many other topics. It’s well worth doing a Google search and reading some of his papers.
Before getting to Siva’s post, here is a picture of a density and some of its level set clusters. The algorithm Siva will describe finds the clusters at all levels (which then form a tree).

THE DENSITY CLUSTER TREE
by
SIVARAMAN BALAKRISHNAN
1. Introduction
Clustering is widely considered challenging both practically and theoretically. One of the main reasons for this is that often the true goals of clustering are not clear and this makes clustering seem poorly defined.
One of the most concrete and intuitive ways to define clusters when data are drawn from a density 


form the clusters at level
However, we usually do not have access to
This post is about the notion of consistency, the CD estimator, and its analysis.
2. Evaluating an estimator: Hartigan’s consistency
The first notion of consistency for an estimated cluster tree was introduced by J.A. Hartigan in his paper: Consistency of single linkage for high-density clusters (JASA, 1981).
Given some estimator 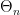
For any sets 
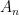


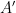
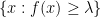
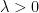



Essentially, we want that if we have two separated clusters at some level
To give finite sample bounds, CD introduced a notion of saliently separated clusters and showed that these clusters can be identified using a small number of samples (as a by-product their results also imply Hartigan consistency for their estimators). Informally, clusters are saliently separated if they satisfy two conditions.
- Separation in
: We would expect that clusters that are two close cannot be identified in a finite sample.
- Separation in the density
3. An algorithm
The CD estimator is based on the following algorithm:
- INPUT:
- For
, discard all points with
where
is the distance to the
nearest neighbor of
. Connect
if
, to form
.
- OUTPUT: Return connected components of
CD show that their estimator is consistent (and give finite sample rates for saliently separated clusters) if we select 
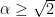
It is actually true that any density estimate that is uniformly close to the true density can be used to construct a Hartigan consistent estimator. However, this involves finding the connected components of the level sets of the estimator, which can be hard. The nice thing about the CD estimator is that it is completely algorithmic.
3.1. Detour 1: Single linkage
Single linkage is a popular linkage clustering algorithm, and essentially corresponds to the case of 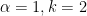
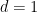
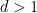
The main issue is an effect called “chaining” which causes single linkage to merge clusters before fully connecting up the clusters within themselves. The reason for this is that single-linkage is not sufficiently sensitive to the density separation, i.e. even if there is a region of low density between two clusters single linkage might form a “chain” across it because it is mostly oblivious to the density of the sample.
Returning to the CD estimator: one intuitive way to understand the estimator is to observe that for a fixed 

4. Analysis
So how does one analyze the CD estimator? We essentially need to show that for any two saliently separated clusters at a level
- We do not clean out any points in the clusters.
- The clusters are internally connected at the radius
.
- The clusters are mutually separated at this radius.
To establish each of these we will first need to understand how the
4.1. Detour 2: Uniform large deviation inequalities
As before we are given 
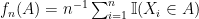



A standard way to answer these questions quantitatively is using a large deviation inequality like Hoeffding’s inequality. Often we have multiple sets 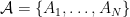
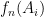
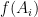
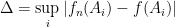
and quantitative estimates of 
One surprising fact is that even for infinite collections of sets 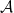
To conclude this detour here is an example of this in action. Let 


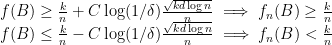
The inequalities above are uniform convergence inequalities over the sets of all balls in 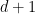
In the context of the CD estimator what this detour assures us is that
References.
Chaudhuri, K. and DasGupta, S. (2010). Rates of convergence for the cluster tree. Advances in Neural Information Processing Systems, 23, 343–351.
Hartigan, J. (1981). Consistency of single linkage for high-density clusters. Journal of the American Statistical Association, 76, 388-394.

4 Comments
This is nice and well explained. A problem with this kind of consistency result, though, is that “k needs to increase as d log n” doesn’t tell us much about how to choose k in a real situation with n and d fixed. I suspect this choice may make quite some difference to the result. Are there recommendations (and a sound rationale for making them)?
I think that’s a very good question. I don’t think there is a conclusive answer yet but here are some half-baked ideas from Larry, Aarti (http://www.cs.cmu.edu/~aarti/), Alessandro (http://www.stat.cmu.edu/~arinaldo/) and others:
1. Something like a Lepski-type method: Here is a paper by Singh, Scott, Nowak where they show minimizing a criterion with a BIC-like complexity penalty works (in theory) for bin width selection for histograms with Hausdorff loss. There is a similar criterion to minimize for k-NN estimators, for a fixed level set, which preserves the consistency results for that level set
Click to access 0908.3593v1.pdf
2. In practice one could try to bootstrap the sample and pick a value of k for which the clustering is stable across the various subsamples. I think you have to have a good way to compare trees across the subsamples. There are some heuristics including kernels on trees for that.
3. Just like drawing a tree gets around the problem of having to choose a level set, you can also get around having to pick k by varying it (from 0 to n). This is no longer a tree so visualizing it is challenging, but it might be possible to develop some notion of persistent (across various values of k) clusters and just try to visualize those.
Nice in it’s simplicity. It seems to be connected with the manifold learning named previously in this blog ¿isn’t it? (drawing balls over each remaining data point), and just these days I think I’m beginning to understand some of the usefulness of (in some cases) infering manifolds rather than response functions.
Yes, I think you’re right and that is a good point. In some sense the (Haudorff/homology) manifold estimation problem is like estimating the support of the density (when there is no noise) and here you’re trying to estimate all level sets but with a different loss function.
One Trackback
[…] few months ago Siva Balakrishnan wrote a nice post on Larry Wasserman’s blog about the Chaudhuri-Dasgupta algorithm for estimating a density […]