Yesterday we were fortunate to have Brad Efron visit our department and gave a seminar.
Brad is one of the most famous statisticians in the world and his contributions to the field of statistics are too numerous to list. Probably he is best known for: inventing the bootstrap, for starting the field of the geometry of statistical models, for least angle regression (an extension of the lasso he developed with Trevor Hastie, Iain Johnstone and Rob Tibshirani), for his work on empirical Bayes, large-scale multiple testing, and many other things.
He has won virtually every possible award including The MacArthur Award and The National Medal of Science.
So, as you can imagine, his visit was a big deal.
He spoke on Frequentist Accuracy of Bayesian Estimates. The key point in the talk was a simple formula for computing the frequentist standard error of a Bayes estimator. Suppose 
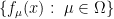
and we want the standard error of the Bayes estimator 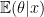
The formula is
![\displaystyle se = \left[ cov(t(\mu),\lambda\,|\,x)^T \, V \, cov(t(\mu),\lambda\,|\,x)\right]^{1/2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++se+%3D+%5Cleft%5B+cov%28t%28%5Cmu%29%2C%5Clambda%5C%2C%7C%5C%2Cx%29%5ET+%5C%2C+V+%5C%2C+cov%28t%28%5Cmu%29%2C%5Clambda%5C%2C%7C%5C%2Cx%29%5Cright%5D%5E%7B1%2F2%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
where
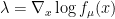
and
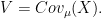
In addition, one can compute the Bayes estimator (in some cases) by using a re-weighted parametric bootstrap. This is much easier than the usual approach based on Monte Carlo Markov Chain. The latter leads to difficult questions about convergence that are completely avoided by using the re-weighted bootstrap.
See the link to his talk for details and examples.
Now you might ask: why would we want the frequentist standard error of a Bayesian estimator? There are (at least) two reasons.
First, the frequentist can view Bayes as a way to generate estimators. And, like any estimator, we would want to estimate its standard error.
Second, the Bayesian who is not completely certain of his prior (which I guess is every Bayesian) might be interested in doing a sensitivity analysis. One way to do such a sensitivity analysis is to ask: how much would my estimator change if I changed the data? The standard error provides one way to answer that question. Brad called this Shaking the Bayesian Machine. Great phrase.
Following the seminar we had a great dinner. I fully participated in copious reminiscing among senior faculty, while my young colleague Ryan Tibshirani wondered what we were talking about. I’m definitely one of the old experienced guys in the department now.
I asked Brad if he’d like to write a guest post for this blog. He didn’t say yes but he didn’t say no either. Let’s keep our fingers crossed. (I’m happy to report that my colleague Steve Fienberg did commit to writing one.)
Bottom line: Brad is doing lots of cool stuff. Check out his web page.

17 Comments
Yes, Brad’s always leading the way with the next cool thing. If I’d known he was visiting CMU, I would have come down from NY. I first met him when he gave a paper “Why Not Everyone is a Bayesian” (or close to that) at Virginia Tech, partly organized by I.J. Good long ago. Lindley was there, and gave him a hard time.
Did not find anything on the using a re-weighted parametric bootstrap.
(Guessing thats re-weighting a sample drawn from the prior to get the posterior)
Do you have references for that?
Thanks in advance
it’s on Brad’s website
Although google does the job, the link is to wikipedia.
Slide #14 is about that; it cited a reference, Efron (2012), listed on the last slide.
Thanks, for some reason my slide viewer was only showing me odd slides and the search for bootstrap also failed.
Finding the frequentist standard error of a subjective-prior Bayesian estimate isn’t much good if the prior is “wrong” and causes a lot of bias.
Yes, Brad pointed that out in the question period after his talk.
Right. If someone uses a horrendously “wrong” prior like N(mean=0, sigma=weight of a M1 Main Battle Tank) for the weight of a human being, then the Bayesain estimates for my weight will be horrendously wrong as well. Oh wait; in this case the results will be identical (out to about 10 significant figures or something) as the elementary Frequentist text book estimates and Confidence Intervals.
It must be a never ending source of mystery to Frequentists why, with all their guarantees and objectivity, 95% CI’s in the wild don’t have anything like 95% coverage, and Bayesian intervals, with their subjective “impossible to interpret” priors consisting of nothing but hopes and wishful thinking, perform no worse and possible better. Could it be that those priors actually do encapsulate objectively true information, but that it’s being done in a way different from what Frequentists find palatable? If so, it would be important to understand what and how that happens so that you can judge Bayesian estimates using a meaningful criterion.
Results like Efron’s are almost always turn out to be important and useful, although usually for reasons different than those given initial. So by all means study the math in detail, but if you really endorse the claim that priors “wrong” according to Frequentist criterion lead to bad estimates, then you’re being lead down rabbit holes by your philosophy of statistics.
Entsophy: If you have not already you may wish to read Rubin’s The Bayesian Bootstrap. 1981.
(Footnote 1 raises questions about the justification of the bootstrap proceedure as it _implies_ the use of a horrendously wrong prior)
Tangentially and serendipitously, I read a paper* today by David Freedman making the same point in regards to the Huber sandwich estimator as a method for getting standard errors robust to model misspecification, i.e., if the model specification error causes bias, there’s little point in getting “robust” standard errors.
* On The So-Called “Huber Sandwich Estimator” and “Robust Standard Errors”. The American Statistician (2006) 60: 299-302. Reprinted in Statistical Models and Causal Inference: A Dialogue with the Social Sciences.
“In the wild,” both i’s in “iid” are typically questionable, a much more fundamental issue than in the Bayesian/frequentist debate. That said, many of us still object to the injection of personal bias.
I agree. The violations of assumptions swamps the other concerns.
Larry
Corey; even when the specification of the mean is wrong, the estimates are estimating *something* – typically a trend. So long as the independence assumption holds, in large samples, the robust standard errors can be turned into confidence intervals for this trend, and these can be useful.
For a more detailed critique of Freedman’s 2006 arguments, and some of his related concerns, this paper by Winston Lim is great.
Its also the situation of (almost) any anaylisis of non-randomised studies – much effort on getting standard errors of comparisons that have unknown biases.
“Second, the Bayesian who is not completely certain of his prior (which I guess is every Bayesian) might be interested in doing a sensitivity analysis. One way to do such a sensitivity analysis is to ask: how much would my estimator change if I changed the data?”
I’ve been thinking about this for a while, and it doesn’t make any sense from a (well, my) Bayesian point of view. As a pragmatic Bayesian, I don’t care about what I would have inferred in the case of data I didn’t actually observe. I only care about checking whether my inferences are robust to different reasonable ways I can translate the prior information into a prior distribution and model.
I’ve tried to think of models for which the frequentist standard error would be large but the posterior standard deviation would be small. This sort of situation would put sharpen the above point. So far, every scenario I’ve thought of has an obvious ancillary or near-ancillary statistic that makes (frequentist) conditional inference the best way to go. (And then the frequentist conditional standard error agrees more-or-less with the posterior standard deviation.)
Dear Normal,
We had the pleasure of hosting a symposium in Brad’s honor in 2011. His presentation at CMU and our symposium sound like perfect compliments.
here is the link to his presentation:http://www.youtube.com/watch?v=FX6huSm2xU4&feature=youtu.be. It can be found via our news page http://www.s-3.com/news as well. Enjoy!