Minimax theory is the best thing in statistical machine learning—or the worst— depending on your point of view.
1. The Basics of Minimaxity
Let 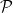
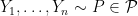
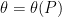

![\displaystyle R_n = \inf_{\hat \theta}\sup_{P\in {\cal P}} \mathbb{E}_P [ d(\hat\theta,\theta(P))]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R_n+%3D+%5Cinf_%7B%5Chat+%5Ctheta%7D%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7D+%5Cmathbb%7BE%7D_P+%5B+d%28%5Chat%5Ctheta%2C%5Ctheta%28P%29%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where the infimum is over all estimators 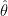
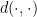
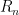
The challenge is to compute (or approximate) the minimax risk
![\displaystyle \sup_{P\in {\cal P}} \mathbb{E}_P [ d(\hat\theta,\theta(P))]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7D+%5Cmathbb%7BE%7D_P+%5B+d%28%5Chat%5Ctheta%2C%5Ctheta%28P%29%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
is equal to
Here is a famous example. Let 





Here is a more sophisticated example: density estimation. Let 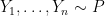


where 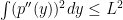
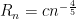


achieves this rate of convergence (for appropriate 

Now consider a set of spaces 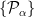

2. Technical Digresson
To find 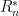

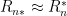
To find an upper bound, pick any estimator
![\displaystyle R_n \leq \sup_{P\in {\cal P}} \mathbb{E}_P [ d(\hat\theta,\theta(P))] \equiv R_n^*.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R_n+%5Cleq+%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7D+%5Cmathbb%7BE%7D_P+%5B+d%28%5Chat%5Ctheta%2C%5Ctheta%28P%29%29%5D+%5Cequiv+R_n%5E%2A.+&bg=ffffff&fg=000000&s=0&c=20201002)
Finding a lower bound is trickier. Typically one uses an information-theoretic inequality like Fano’s inequality. In particular, we pick a finite set of distributions 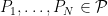

where

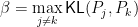
and 
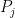
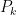
Choosing 
3. In Favor Of Minimaxity
The purpose of minimax analysis is to understand the difficulty of a problem. Here is a small sample of the types of questions that minimax theory has cast light on recently:
- How hard is it to find the non-zero variables in a high-dimensional regression?
- How hard is it to estimate an undirected graph?
- How hard is it to estimate the homology of a manifold?
- How hard is it to test a hypothesis about a high-dimensional Normal mean?
- How hard is it to estimate a sparse signal from compressed measurements?
The virtue of minimax theory is that it gives a precise notion of the intrinsic difficulty of a problem. And it allows you to evaluate an estimator against a benchmark: if your estimator is not minimax then you can search for a better estimator.
4. Against Minimaxity
There are some valid criticisms of minimax theory. You have to specify a loss function. You have to specify a class of distributions
Having to specify a loss and a class
The claim that minimax theory is driven by the worst case is a more substantial criticism. I happen to think worst case analysis is a good thing. I want an estimator that does reasonably well under any circumstances.
And for nonparametric problems, where
Think of it this way: if I buy a car, and I know that the car was tested and found to perform well even under extremely difficult circumstances, then I’ll feel better about buying the car.
Having said that, there are plenty of people who are uncomfortable with the worst case nature of minimax theory.
5. Minimaxity Gets the Last Word?
Minimax theory was important in statistics for a while then it sort of faded. But it had a revival, partly due to the work of Donoho et al.
But what is really interesting is that I see more and more minimax analyses in ML outlets such as NIPS, JMLR etc. So perhaps the marketplace of ideas is telling us that minimax theory is gaining in importance?
6. References
Donoho, D.L., Johnstone, I.M., Kerkyacharian, G. and Picard, D. (1995). Wavelet shrinkage: asymptopia?. Journal of the Royal Statistical Society. Series B. 301–369.
Tsybakov, A.B. (2009). Introduction to Nonparametric Estimation.
Wasserman, L. (2006). All of Nonparametric Statistics.
Wolfowitz, J. (1950). Minimax estimates of the mean of a normal distribution with known variance. The Annals of Mathematical Statistics, 21, 218-230.
—Larry Wasserman

12 Comments
” if I buy a car, and I know that the car was tested and found to perform well even under extremely difficult circumstances, then I’ll feel better about buying the car.” Yes, but if the tests are maximally stringent, you might have to conclude it’s “unsafe at any speed”.
Indeed.
 matters.
matters.
This emphasizes that the choice of
In simple situations for which we know good low risk estimators, how much higher does the risk of the minimax estimator tend to be?
Sorry, I’m talking about Bayes risk here. How much worse is the Bayes risk of the minimax estimator than the Bayes estimator typically? If there were a result, for instance, that under certain regular models the minimax estimator is not too far from the Bayes estimator, that would be very strong support for using minimax.
Thanks for ths clear and briefs expositions of statistical theory.
Just yesterday I was going to meet with my statistics professor to ask him some doubts, we couldn’t so forgive me if I pose here the doubt related to minimax estimators:
¿How do you deal with the dependence with respect to irrelevant variables?, in the words of Chernoff (“Rational selection of decision functions”):
“In some example the minimax regret criterion may select a strategy [estimator] d3 among the availables strategies d1, d2, d3, d4. […] if for some reason d4 is made unavailable, the minimax regret criterion will select d2 among d1, d2 and d3.”
It puzzles me how this incoherence arises (or else how not to see this as an incoherence).
By the way, in reference to the Bayes risk, may I mention that it suposses a prior distribution of the parameter in question, in that context minimax risk can be understood as the Bayes risk for the worst-case prior. (this last comment may be wrong, I’m not sure).
Nice (and helpful) posts : )
Yes. You are absolutely correct. The minimax rule
is a Bayes rule under a least favorable prior.
(I don’t remember enough to answer your first question)
Why is the minimax regret criterion ‘incoherent’? Because it requires simultaneous optimization with respect to multiple objectives. … Not such a great answer, but maybe it’s a start?
Do you have a reference or further clarification for the d1, d2, d3, d4 comment?
I remember the opposite in informal decision making – amongst d1, d2, d3 – I prefer d2.
Ok, but did you know you could also choose d4?
No, in that case I prefer d3.
(Explanation is that d4 brought other information to mind that led to the change in preference.)
@O’ Rourke: I suppose this answer comes way too late, but
yes there is a reference: Chernoff’s “Rational selection of decision functions”, a 1954 econometrica paper
you can find it as the first hit in google for the author and the title (http://dido.econ.yale.edu/P/cp/p00b/p0091.pdf)
@Paul: thanks for the humble start, just have to see where it takes me : )
As to Larry’s mentioning that
“The claim that minimax theory is driven by the worst case is a more substantial criticism. I happen to think worst case analysis is a good thing. I want an estimator that does reasonably well under any circumstances.”
and Zach’s remark ‘how much higher does the risk of a Bayes estimator tend to be?’
I think it’s important to mention the following: in some settings, whether or not minimax theory is useful (and the worst-case tends not to be too far from ‘most’ average cases) depends on whether one adopts the right loss function for the problem.
For example, in the individual-sequence prediction setting, on which Larry posted two weeks ago, if one looks for the algorithm that achieves the minimax *standard loss* (eg absolute loss as in Larry’s example, or log loss), one ends up with a trivial algorithm that predicts 1/2 no matter what happened in the past.
The prior- expected performance of a Bayesian algorithm will almost always be substantially better.
If one looks for the algorithm that achieves the minimax *regret* (the regret is itself a meta-loss function), one gets something very interesting – some learning algorithms have small minimax regret in the worst-case over all sequences; and in many circumstances the expected regret of a Bayesian predictor, assuming the Bayesian’s prior is correct, will be only slightly smaller than the minimax regret.
Think about data-compression: the worst-case optimal data compressor of binary sequences simply encodes 0 as 0 and 1 as 1, and will never achieve any compression. Algorithms like gzip try to minimize the compression *regret* (additional rather than absolute number of bits) compared to the best finite state predictor. These algorithms have worst-case guarantees and they work well in practice (we all use them).
Great response, thanks.
That’s a great point Peter. When writing my post, I had in mind nonparametric regresson etc (in batch mode) with standard loss functions.
The setting (and the loss function) really do matter.
–LW
One Trackback
[…] First, if we look at the maximum risk rather than the pointwise risk then we see that the mle is optimal. Indeed, is the unique estimator that is minimax for all bowl-shaped estimators. See my earlier post on this. […]