Richard Lockhart, Jonathan Taylor, Ryan Tibshirani and Rob Tibshirani have an interesting paper about significance tests for the lasso. The paper will appear in The Annals of Statistics. I was asked to write a discussion about the paper. Here is my discussion. (I suggest your read their paper before reading my discussion.)
Assumption-Free High-Dimensional Inference:
Discussion of LTTT
Larry Wasserman
The paper by Lockhart, Taylor, Tibshirani and Tibshirani (LTTT) is an important advancement in our understanding of inference for high-dimensional regression. The paper is a tour de force, bringing together an impressive array of results, culminating in a set of very satisfying convergence results. The fact that the test statistic automatically balances the effect of shrinkage and the effect of adaptive variable selection is remarkable.
The authors make very strong assumptions. This is quite reasonable: to make significant theoretical advances in our understanding of complex procedures, one has to begin with strong assumptions. The following question then arises: what can we do without these assumptions?
1. The Assumptions
The assumptions in this paper — and in most theoretical papers on high dimensional regression — have several components. These include:
- The linear model is correct.
- The variance is constant.
- The errors have a Normal distribution.
- The parameter vector is sparse.
- The design matrix has very weak collinearity. This is usually stated in the form of incoherence, eigenvalue restrictions or incompatibility assumptions.
To the best of my knowledge, these assumptions are not testable when 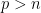 . They are certainly a good starting place for theoretical investigations but they are indeed very strong. The regression function
. They are certainly a good starting place for theoretical investigations but they are indeed very strong. The regression function 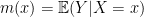 can be any function. There is no reason to think it will be close to linear. Design assumptions are also highly suspect. High collinearity is the rule rather than the exception especially in high-dimensional problems. An exception is signal processing, in particular compressed sensing, where the user gets to construct the design matrix. In this case, if the design matrix is filled with independent random Normals, the design matrix will be incoherent with high probability. But this is a rather special situation.
can be any function. There is no reason to think it will be close to linear. Design assumptions are also highly suspect. High collinearity is the rule rather than the exception especially in high-dimensional problems. An exception is signal processing, in particular compressed sensing, where the user gets to construct the design matrix. In this case, if the design matrix is filled with independent random Normals, the design matrix will be incoherent with high probability. But this is a rather special situation.
None of this is meant as a criticism of the paper. Rather, I am trying to motivate interest in the question I asked earlier, namely: what can we do without these assumptions?
Remark 1 It is also worth mentioning that even in low dimensional models and even if the model is correct, model selection raises troubling issues that we all tend to ignore. In particular, variable selection makes the minimax risk explode (Leeb and Potscher 2008 and Leeb and Potscher 2005). This is not some sort of pathological risk explosion, rather, the risk is large in a neighborhood of 0, which is a part of the parameter space we care about.
2. The Assumption-Free Lasso
To begin it is worth pointing out that the lasso has a very nice assumption-free interpretation.
Suppose we observe 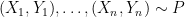 where
where 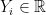 and
and 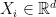 . The regression function is some unknown, arbitrary function. We have no hope to estimate
. The regression function is some unknown, arbitrary function. We have no hope to estimate 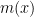 nor do we have licence to impose assumptions on
nor do we have licence to impose assumptions on  .
.
But there is sound theory to justify the lasso that makes virtually no assumptions. In particular, I refer to Greenshtein and Ritov (2004) and Juditsky and Nemirovski (2000).
Let  be the set of linear predictors. For a given
be the set of linear predictors. For a given  , define the predictive risk
, define the predictive risk

where 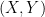 is a new pair. Let us define the best, sparse, linear predictor
is a new pair. Let us define the best, sparse, linear predictor 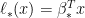 (in the
(in the 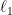 sense) where
sense) where 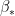 minimizes
minimizes 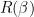 over the set
over the set 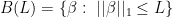 . The lasso estimator
. The lasso estimator  minimizes the empirical risk
minimizes the empirical risk 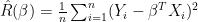 over
over  . For simplicity, I’ll assume that all the variables are bounded by
. For simplicity, I’ll assume that all the variables are bounded by  (but this is not really needed). We make no other assumptions: no linearity, no design assumptions, and no models. It is now easily shown that
(but this is not really needed). We make no other assumptions: no linearity, no design assumptions, and no models. It is now easily shown that

except on a set of probability at most  .
.
This shows that the predictive risk of the lasso comes close to the risk of the best sparse linear predictor. In my opinion, this explains why the lasso “works.” The lasso gives us a predictor with a desirable property — sparsity — while being computationally tractable and it comes close to the risk of the best sparse linear predictor.
3. Interlude: Weak Versus Strong Modeling
When developing new methodology, I think it is useful to consider three different stages of development:
- Constructing the method.
- Interpreting the output of the method.
- Studying the properties of the method.
I also think it is useful to distinguish two types of modeling. In strong modeling, the model is assumed to be true in all three stages. In weak modeling, the model is assumed to be true for stage 1 but not for stages 2 and 3. In other words, one can use a model to help construct a method. But one does not have to assume the model is true when it comes to interpretation or when studying the theoretical properties of the method. My discussion is guided by my preference for weak modeling.
4. Assumption Free Inference: The HARNESS
Here I would like to discuss an approach I have been developing with Ryan Tibshirani. We call this: High-dimensional Agnostic Regresson Not Employing Structure or Sparsity, or, the HARNESS. The method is a variant of the idea proposed in Wasserman and Roeder (2009).
The idea is to split the data into two halves.  and
and 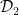 . For simplicity, assume that
. For simplicity, assume that  is even so that each half has size
is even so that each half has size 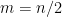 . From the first half we select a subset of variables
. From the first half we select a subset of variables  . The method is agnostic about how the variable selection is done. It could be forward stepwise, lasso, elastic net, or anything else. The output of the first part of the analysis is the subset of predictors and an estimator
. The method is agnostic about how the variable selection is done. It could be forward stepwise, lasso, elastic net, or anything else. The output of the first part of the analysis is the subset of predictors and an estimator  . The second half of the data is used to provide distribution free inferences for the following questions:
. The second half of the data is used to provide distribution free inferences for the following questions:
- What is the predictive risk of ?
- How much does each variable in contribute to the predictive risk?
- What is the best linear predictor using the variables in ?
All the inferences from are interpreted as being conditional on . (A variation is to use only to produce and then construct the coefficients of the predictor from . For the purposes of this discussion, we use from .)
In more detail, let
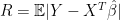
where the randomness is over the new pair ; we are conditioning on . Note that in this section I have changed the definition of  to be on the absolute scale which is more interpretable. In the above equation, it is understood that
to be on the absolute scale which is more interpretable. In the above equation, it is understood that 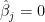 when
when 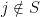 . The first question refers to producing a estimate and confidence interval for (conditional on ). The second question refers to inferring
. The first question refers to producing a estimate and confidence interval for (conditional on ). The second question refers to inferring
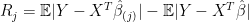
for each 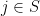 , where
, where 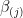 is equal to except that
is equal to except that 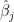 is set to 0. Thus,
is set to 0. Thus, 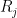 is the risk inflation by excluding
is the risk inflation by excluding  . The third question refers to inferring
. The third question refers to inferring
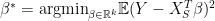
the coefficient of the best linear predictor for the chosen model. We call 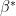 the projected parameter. Hence,
the projected parameter. Hence, 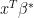 is the best linear approximation to on the linear space spanned by the selected variables.
is the best linear approximation to on the linear space spanned by the selected variables.
A consistent estimate of is
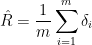
where the sum is over , and  . An approximate
. An approximate 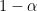 confidence interval for is
confidence interval for is  where
where  is the standard deviation of the
is the standard deviation of the 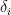 ‘s.
‘s.
The validity of this confidence interval is essentially distribution free. In fact, if want to be purely distribution free and avoid asymptotics, we could instead define to be the median of the law of 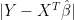 . Then the order statistics of the ‘s can be used in the usual way to get a finite sample, distribution free confidence interval for .
. Then the order statistics of the ‘s can be used in the usual way to get a finite sample, distribution free confidence interval for .
Estimates and confidence intervals for can be obtained from 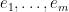 where
where

Estimates and confidence intervals for can be obtained by standard least squares procedures based on . The steps are summarized here:
The HARNESS
Input: data  .
.
- Randomly split the data into two halves and .
- Use to select a subset of variables . This can be forward stepwise, the lasso, or any other method.
- Let
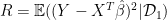 be the predictive risk of the selected model on a future pair , conditional on .
be the predictive risk of the selected model on a future pair , conditional on .
- Using construct point estimates and confidence intervals for ,
 and .
and .
The HARNESS bears some similarity to POSI (Berk et al 2013) which is another inference method for model selection. They both eschew any assumption that the linear model is correct. But POSI attempts to make inferences that are valid over all possible selected models while the HARNESS restricts attention to the selected model. Also, the HARNESS emphasizes predictive inferential statement.
Here is an example using the wine dataset. (Thanks to the authors for providing the data.) Using the first half of the data we applied forward stepwise selection and used  to select a model. The selected variables are Alcohol, Volatile-Acidity, Sulphates, Total-Sulfur-Dioxide and pH. A 95 percent confidence interval for the predictive risk of the null model is (0.65,0.70). For the selected model, the confidence interval for is (0.46,0.53). The (Bonferroni-corrected) 95 percent confidence intervals for the ‘s are shown in the first plot below. The (Bonferroni-corrected) 95 percent confidence intervals for the parameters of the projected model are shown in the second plot below.
to select a model. The selected variables are Alcohol, Volatile-Acidity, Sulphates, Total-Sulfur-Dioxide and pH. A 95 percent confidence interval for the predictive risk of the null model is (0.65,0.70). For the selected model, the confidence interval for is (0.46,0.53). The (Bonferroni-corrected) 95 percent confidence intervals for the ‘s are shown in the first plot below. The (Bonferroni-corrected) 95 percent confidence intervals for the parameters of the projected model are shown in the second plot below.


5. The Value of Data-Splitting
Some statisticians are uncomfortable with data-splitting. There are two common objections. The first is that the inferences are random: if we repeat the procedure we will get different answers. The second is that it is wasteful.
The first objection can be dealt with by doing many splits and combining the information appropriately. This can be done but is somewhat involved and will be described elsewhere. The second objection is, in my view, incorrect. The value of data splitting is that leads to simple, assumption free inference. There is nothing wasteful about this. Both halves of the data are being put to use. Admittedly, the splitting leads to a loss of power compared to ordinary methods if the model were correct. But this is a false comparison since we are trying to get inferences without assuming the model is correct. It’s a bit like saying that nonparametric function estimators have slower rates of convergence than parametric estimators. But that is only because the parametric estimators invoke stronger assumptions.
6. Conformal Prediction
Since I am focusing my discussion on regression methods that make weak assumptions, I would also like to briefly mention Vladimir Vovk’s theory of conformal inference. This is a completely distribution free, finite sample method for predictive regression. The method is described in Vovk, Gammerman and Shafer (2005) and Vovk, Nouretdinov and Gammerman (2009). Unfortunately, most statisticians seem to be unaware of this work which is a shame. The statistical properties (such as minimax properties) of conformal prediction were investigated in Lei, Robins, and Wasserman (2012) and Lei and Wasserman (2013).
A full explanation of the method is beyond the scope of this discussion but I do want to give the general idea and say why it is related the current paper. Given data  suppose we observe a new
suppose we observe a new  and want to predict
and want to predict  . Let
. Let 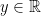 be an arbitrary real number. Think of
be an arbitrary real number. Think of  as a tentative guess at . Form the augmented data set
as a tentative guess at . Form the augmented data set
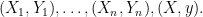
Now we fit a linear model to the augmented data and compute residuals 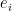 for each of the
for each of the  observations. Now we test
observations. Now we test 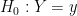 . Under
. Under  , the residuals are invariant under permutations and so
, the residuals are invariant under permutations and so
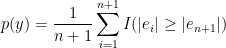
is a distribution-free p-value for .
Next we invert the test: let 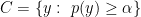 . It is easy to show that
. It is easy to show that
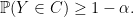
Thus is distribution-free, finite-sample prediction interval for . Like the HARNESS, the validity of the method does not depend on the linear model being correct. The set has the desired coverage probability no matter what the true model is. Both the HARNESS and conformal prediction use the linear model as a device for generating predictions but neither requires the linear model to be true for the inferences to be valid. (In fact, in the conformal approach, any method of generating residuals can be used. It does not have to be a linear model. See Lei and Wasserman 2013.)
One can also look at how the prediction interval changes as different variables are removed. This gives another assumption free method to explore the effects of predictors in regression. Minimizing the length of the interval over the lasso path can also be used as a distribution-free method for choosing the regularization parameter of the lasso.
On a related note, we might also be interested in assumption-free methods for the related task of inferring graphical models. For a modest attempt at this, see Wasserman, Kolar and Rinaldo (2013).
7. Causation
LTTT do not discuss causation. But in any discussion of the assumptions underlying regression, causation is lurking just below the surface. Indeed, there is a tendency to conflate causation and inference. To be clear: prediction, inference and causation are three separate ideas.
Even if the linear model is correct, we have to be careful how we interpret the parameters. Many articles and textbooks describe 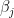 as the change in if is changed, holding the other covariates fixed. This is incorrect. In fact, is the change in our prediction of if is changed. This may seem like nit picking but this is the very difference between association and causation.
as the change in if is changed, holding the other covariates fixed. This is incorrect. In fact, is the change in our prediction of if is changed. This may seem like nit picking but this is the very difference between association and causation.
Causation refers to the change in as is changed. Association (prediction) refers to the change in our prediction of as is changed. Put another way, prediction is about 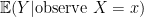 while causation is about
while causation is about  . If is randomly assigned, they are the same. Otherwise they are different. To make the causal claim, we have to include in the model, every possible confounding variable that could affect both and . This complete causal model has the form
. If is randomly assigned, they are the same. Otherwise they are different. To make the causal claim, we have to include in the model, every possible confounding variable that could affect both and . This complete causal model has the form
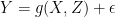
where 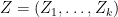 represents all confounding variables in the world. The relationship between and alone is described as
represents all confounding variables in the world. The relationship between and alone is described as
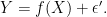
The causal effect — the change in as is changed — is given by 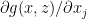 . The association (prediction) — the change in our prediction of as is changed — is given by
. The association (prediction) — the change in our prediction of as is changed — is given by  . If there are any omitted confounding variables then these will be different.
. If there are any omitted confounding variables then these will be different.
Which brings me back to the paper. Even if the linear model is correct, we still have to exercise great caution in interpreting the coefficients. Most users of our methods are non-statisticians and are likely to interpret causally no matter how many warnings we give.
8. Conclusion
LTTT have produced a fascinating paper that significantly advances our understanding of high dimensional regression. I expect there will be a flurry of new research inspired by this paper.
My discussion has focused on the role of assumptions. In low dimensional models, it is relatively easy to create methods that make few assumptions. In high dimensional models, low-assumption inference is much more challenging.
I hope I have convinced the authors that the low assumption world is worth exploring. In the meantime, I congratulate the authors on an important and stimulating paper.
Acknowledgements
Thanks to Rob Kass, Rob Tibshirani and Ryan Tibshirani for helpful comments.
References
Berk, Richard and Brown, Lawrence and Buja, Andreas and Zhang, Kai and Zhao, Linda. (2013). Valid post-selection inference. The Annals of Statistics, 41, 802-837.
Greenshtein, Eitan and Ritov, Ya’cov. (2004). Persistence in high-dimensional linear predictor selection and the virtue of overparametrization. Bernoulli, 10, 971-988.
Juditsky, A. and Nemirovski, A. (2000). Functional aggregation for nonparametric regression. Ann. Statist., 28, 681-712.
Leeb, Hannes and Potscher, Benedikt M. (2008). Sparse estimators and the oracle property, or the return of Hodges’ estimator. Journal of Econometrics, 142, 201-211.
Leeb, Hannes and Potscher, Benedikt M. (2005). Model selection and inference: Facts and fiction. Econometric Theory, 21, 21-59.
Lei, Robins, and Wasserman (2012). Efficient nonparametric conformal prediction regions. Journal of the American Statistical Association.
Lei, Jing and Wasserman, Larry. (2013). Distribution free prediction bands. J. of the Royal Statistical Society Ser. B.
Vovk, V., Gammerman, A., and Shafer, G. (2005). Algorithmic Learning in a Random World. Springer.
Vovk, V., Nouretdinov, I., and Gammerman, A. (2009). On-line predictive linear regression. The Annals of Statistics, 37, 1566-1590.
Wasserman, L., Kolar, M. and Rinaldo, A. (2013). Estimating Undirected Graphs Under Weak Assumptions. arXiv:1309.6933.
Wasserman, Larry and Roeder, Kathryn. (2009). High dimensional variable selection. Annals of statistics, 37, p 2178.
 of some random variable
of some random variable 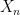 is close to Normal. What makes Stein’s method so powerful is that it can be used in a variety of situations (including cases with dependence) and it tells you how far
is close to Normal. What makes Stein’s method so powerful is that it can be used in a variety of situations (including cases with dependence) and it tells you how far 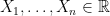 be iid with mean 0 and variance 1. Let
be iid with mean 0 and variance 1. Let 
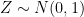 . We want to bound
. We want to bound 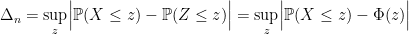
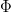 is the cdf of a standard Normal. For simplicity, we will assume here
is the cdf of a standard Normal. For simplicity, we will assume here 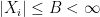
![\displaystyle \mathbb{E}[Y f(Y)] = \mathbb{E}[f'(Y)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathbb%7BE%7D%5BY+f%28Y%29%5D+%3D+%5Cmathbb%7BE%7D%5Bf%27%28Y%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 if and only if
if and only if 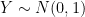 . This suggests the following idea: if we can show that
. This suggests the following idea: if we can show that ![{\mathbb{E}[Y f(Y)-f'(Y)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5BY+f%28Y%29-f%27%28Y%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is close to 0, then
is close to 0, then  be any function such that
be any function such that 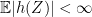 . The Stein function
. The Stein function ![\displaystyle f'(x) - x f(x) = h(x) - \mathbb{E}[h(Z)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f%27%28x%29+-+x+f%28x%29+%3D+h%28x%29+-+%5Cmathbb%7BE%7D%5Bh%28Z%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathbb{E}[h(X)] - \mathbb{E}[h(Z)]= \mathbb{E}[f'(X) - Xf(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathbb%7BE%7D%5Bh%28X%29%5D+-+%5Cmathbb%7BE%7D%5Bh%28Z%29%5D%3D+%5Cmathbb%7BE%7D%5Bf%27%28X%29+-+Xf%28X%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathbb{E}[f'(X) - Xf(X)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5Bf%27%28X%29+-+Xf%28X%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is small.
is small.![{\mu = \mathbb{E}[h(Z)]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu+%3D+%5Cmathbb%7BE%7D%5Bh%28Z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , the Stein function is
, the Stein function is ![\displaystyle f(x) =f_h(x)= e^{x^2/2}\int_{-\infty}^x[ h(y) - \mu] e^{-y^2/2} dy. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f%28x%29+%3Df_h%28x%29%3D+e%5E%7Bx%5E2%2F2%7D%5Cint_%7B-%5Cinfty%7D%5Ex%5B+h%28y%29+-+%5Cmu%5D+e%5E%7B-y%5E2%2F2%7D+dy.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
 is the unique solution to the above equation subject to the side condition
is the unique solution to the above equation subject to the side condition  .
.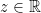 and let
and let  . Let
. Let 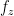 denote the Stein function for
denote the Stein function for 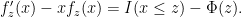
![\displaystyle f(x)\equiv f_z(x) = \begin{cases} \sqrt{2\pi}e^{x^2/2}\Phi(x)[1-\Phi(z)] & x\leq z\\ \sqrt{2\pi}e^{x^2/2}\Phi(z)[1-\Phi(x)] & x> z. \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f%28x%29%5Cequiv+f_z%28x%29+%3D+%5Cbegin%7Bcases%7D+%5Csqrt%7B2%5Cpi%7De%5E%7Bx%5E2%2F2%7D%5CPhi%28x%29%5B1-%5CPhi%28z%29%5D+%26+x%5Cleq+z%5C%5C+%5Csqrt%7B2%5Cpi%7De%5E%7Bx%5E2%2F2%7D%5CPhi%28z%29%5B1-%5CPhi%28x%29%5D+%26+x%3E+z.+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

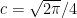 . Also,
. Also, 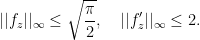
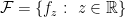 . From the equation
. From the equation ![{f'(x) - x f(x) = h(x) - \mathbb{E}[h(Z)]}](https://s0.wp.com/latex.php?latex=%7Bf%27%28x%29+-+x+f%28x%29+%3D+h%28x%29+-+%5Cmathbb%7BE%7D%5Bh%28Z%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) it follows that
it follows that ![\displaystyle \mathbb{P}(X \leq z) - \mathbb{P}(Y \leq z) = \mathbb{E}[f'(X) - Xf(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathbb%7BP%7D%28X+%5Cleq+z%29+-+%5Cmathbb%7BP%7D%28Y+%5Cleq+z%29+%3D+%5Cmathbb%7BE%7D%5Bf%27%28X%29+-+Xf%28X%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \Delta_n = \sup_z \Bigl| \mathbb{P}(X \leq z) - \mathbb{P}( Z \leq z)\Bigr| \leq \sup_{f\in {\cal F}} \Bigl| \mathbb{E}[ f'(X) - X f(X)]\Bigr|.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CDelta_n+%3D+%5Csup_z+%5CBigl%7C+%5Cmathbb%7BP%7D%28X+%5Cleq+z%29+-+%5Cmathbb%7BP%7D%28+Z+%5Cleq+z%29%5CBigr%7C+%5Cleq+%5Csup_%7Bf%5Cin+%7B%5Ccal+F%7D%7D+%5CBigl%7C+%5Cmathbb%7BE%7D%5B+f%27%28X%29+-+X+f%28X%29%5D%5CBigr%7C.+&bg=ffffff&fg=000000&s=0&c=20201002)
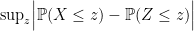 to the problem of bounding
to the problem of bounding ![{\sup_{f\in {\cal F}} \Bigl| \mathbb{E}[ f'(X) - X f(X)]\Bigr|}](https://s0.wp.com/latex.php?latex=%7B%5Csup_%7Bf%5Cin+%7B%5Ccal+F%7D%7D+%5CBigl%7C+%5Cmathbb%7BE%7D%5B+f%27%28X%29+-+X+f%28X%29%5D%5CBigr%7C%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![{\mu_3 = \mathbb{E}[|X_i|^3]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu_3+%3D+%5Cmathbb%7BE%7D%5B%7CX_i%7C%5E3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Recall that
. Recall that 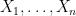 are iid, mean 0, variance 1. Let
are iid, mean 0, variance 1. Let 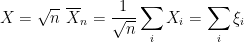
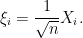
 define the leave-one-out quantity
define the leave-one-out quantity 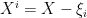
 is independent of
is independent of  . We also make use of the following simple fact: for any
. We also make use of the following simple fact: for any  ,
, 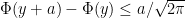 since the density of the Normal is bounded above by
since the density of the Normal is bounded above by 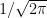 .
.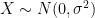 if and only if
if and only if ![\displaystyle \sigma^2 \mathbb{E}[f'(X)] = \mathbb{E}[X f(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma%5E2+%5Cmathbb%7BE%7D%5Bf%27%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5BX+f%28X%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 . Say that
. Say that 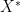 has the
has the ![\displaystyle \sigma^2 \mathbb{E} [f'(X^*)] = \mathbb{E}[X f(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma%5E2+%5Cmathbb%7BE%7D+%5Bf%27%28X%5E%2A%29%5D+%3D+%5Cmathbb%7BE%7D%5BX+f%28X%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 . Zero-biasing is a transform that maps one random variable
. Zero-biasing is a transform that maps one random variable ![\displaystyle \sigma^2 \mathbb{E}[f'(X^*)] = \mathbb{E}[X f(X)]. \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma%5E2+%5Cmathbb%7BE%7D%5Bf%27%28X%5E%2A%29%5D+%3D+%5Cmathbb%7BE%7D%5BX+f%28X%29%5D.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle p^*(x) = \frac{\mathbb{E}[ X I(X>x)]}{\sigma^2} = -\frac{\mathbb{E}[ X I(X\leq x)]}{\sigma^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++p%5E%2A%28x%29+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5B+X+I%28X%3Ex%29%5D%7D%7B%5Csigma%5E2%7D+%3D+-%5Cfrac%7B%5Cmathbb%7BE%7D%5B+X+I%28X%5Cleq+x%29%5D%7D%7B%5Csigma%5E2%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
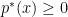 and integrates to 1. Let us verify that (
and integrates to 1. Let us verify that (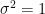 . Given an absolutely continuous
. Given an absolutely continuous  such that
such that 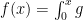 . Then
. Then ![\displaystyle \begin{array}{rcl} \int_0^\infty f'(u)\ p^*(u) du &=& \int_0^\infty f'(u)\ \mathbb{E}[X I(X>u)] du = \int_0^\infty g(u)\ \mathbb{E}[X I(X>u)] du\\ &=& \mathbb{E}\left[X \int_0^\infty g(u) I(X>u) du \right]= \mathbb{E}\left[X \int_{0}^{X\vee 0} g(u) du \right]= \mathbb{E}[X f(X)I(X\geq 0)]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cint_0%5E%5Cinfty+f%27%28u%29%5C+p%5E%2A%28u%29+du+%26%3D%26+%5Cint_0%5E%5Cinfty+f%27%28u%29%5C+%5Cmathbb%7BE%7D%5BX+I%28X%3Eu%29%5D+du+%3D+%5Cint_0%5E%5Cinfty+g%28u%29%5C+%5Cmathbb%7BE%7D%5BX+I%28X%3Eu%29%5D+du%5C%5C+%26%3D%26+%5Cmathbb%7BE%7D%5Cleft%5BX+%5Cint_0%5E%5Cinfty+g%28u%29+I%28X%3Eu%29+du+%5Cright%5D%3D+%5Cmathbb%7BE%7D%5Cleft%5BX+%5Cint_%7B0%7D%5E%7BX%5Cvee+0%7D+g%28u%29+du+%5Cright%5D%3D+%5Cmathbb%7BE%7D%5BX+f%28X%29I%28X%5Cgeq+0%29%5D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![{\int_{-\infty}^0 f'(u)\ p^*(u) du =\mathbb{E}[X f(X)I(X\geq 0)].}](https://s0.wp.com/latex.php?latex=%7B%5Cint_%7B-%5Cinfty%7D%5E0+f%27%28u%29%5C+p%5E%2A%28u%29+du+%3D%5Cmathbb%7BE%7D%5BX+f%28X%29I%28X%5Cgeq+0%29%5D.%7D&bg=ffffff&fg=000000&s=0&c=20201002)

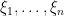 be independent, mean 0 random variables and let
be independent, mean 0 random variables and let 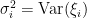 . Let
. Let  . Let
. Let 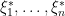 be independent and zero-bias. Define
be independent and zero-bias. Define 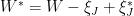
 . Then
. Then  has the
has the  -zero bias distribution. In particular, suppose that
-zero bias distribution. In particular, suppose that  have mean 0 common variance and let
have mean 0 common variance and let 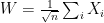 . Let
. Let  be a random integer from 1 to
be a random integer from 1 to 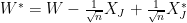 has the
has the 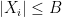 . Let
. Let 
 be independent random variables where
be independent random variables where 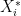 is zero-bias for
is zero-bias for  and let
and let 
![\displaystyle \mathbb{E}[ X f(X)] = \mathbb{E}[f'(X^*)] \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathbb%7BE%7D%5B+X+f%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5Bf%27%28X%5E%2A%29%5D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)

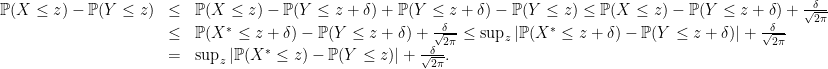
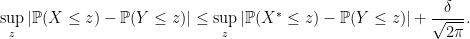
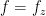 . From the properties of the Stein function given earlier we have
. From the properties of the Stein function given earlier we have ![\displaystyle \begin{array}{rcl} \sup_z |\mathbb{P}(X^* \leq z) - \mathbb{P}(Y \leq z)| &\leq & \sup_{f\in {\cal F}}\Big|\mathbb{E}[ f'(X^*) - X^* f(X^*)]\Bigr|= \sup_{f\in {\cal F}}\Big|\mathbb{E}[ X f(X) - X^* f(X^*)]\Bigr|\\ &\leq & \mathbb{E}\left[ \left( |X| + \frac{2\pi}{4}\right)\ |X^* - X| \right]\leq \delta \left(1 + \frac{2\pi}{4}\right). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Csup_z+%7C%5Cmathbb%7BP%7D%28X%5E%2A+%5Cleq+z%29+-+%5Cmathbb%7BP%7D%28Y+%5Cleq+z%29%7C+%26%5Cleq+%26+%5Csup_%7Bf%5Cin+%7B%5Ccal+F%7D%7D%5CBig%7C%5Cmathbb%7BE%7D%5B+f%27%28X%5E%2A%29+-+X%5E%2A+f%28X%5E%2A%29%5D%5CBigr%7C%3D+%5Csup_%7Bf%5Cin+%7B%5Ccal+F%7D%7D%5CBig%7C%5Cmathbb%7BE%7D%5B+X+f%28X%29+-+X%5E%2A+f%28X%5E%2A%29%5D%5CBigr%7C%5C%5C+%26%5Cleq+%26+%5Cmathbb%7BE%7D%5Cleft%5B+%5Cleft%28+%7CX%7C+%2B+%5Cfrac%7B2%5Cpi%7D%7B4%7D%5Cright%29%5C+%7CX%5E%2A+-+X%7C+%5Cright%5D%5Cleq+%5Cdelta+%5Cleft%281+%2B+%5Cfrac%7B2%5Cpi%7D%7B4%7D%5Cright%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
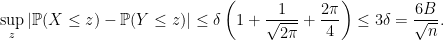



 from random vectors
from random vectors 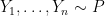 . Here, each
. Here, each 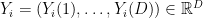 is a vector with
is a vector with  coordinates, or features.
coordinates, or features. and
and  if the partial correlation
if the partial correlation 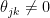 . The partial correlation
. The partial correlation 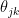 is
is 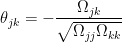
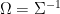 and
and  is the
is the 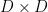 covariance matrix for
covariance matrix for 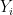 .
.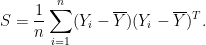
 with
with  . We can then use the bootstrap to get confidence intervals for each
. We can then use the bootstrap to get confidence intervals for each 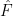 to the true distribution
to the true distribution  of
of 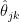 ? Our paper provides a finite sample bound on
? Our paper provides a finite sample bound on 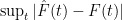 . Not surprisingly, the bounds are reasonable when
. Not surprisingly, the bounds are reasonable when 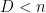 .
. ? In that case, estimating the distribution of
? In that case, estimating the distribution of 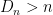 . Instead, we take an atavistic approach: we first perform some sort of dimension reduction followed by the bootstrap. We basically give up on the original graph and instead estimate the graph for a dimension-reduced version of the problem.
. Instead, we take an atavistic approach: we first perform some sort of dimension reduction followed by the bootstrap. We basically give up on the original graph and instead estimate the graph for a dimension-reduced version of the problem.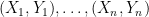 where
where 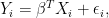
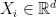 and
and 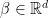 . Let
. Let 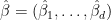 be an estimator of
be an estimator of  .
.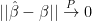
 .
.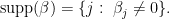
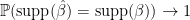
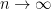 .
.
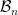 be some set of
be some set of 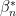 be the best
be the best 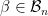 . Then
. Then 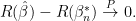
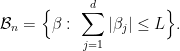
 is allowed to depend on
is allowed to depend on 
You must be logged in to post a comment.