SIMPSON’S PARADOX EXPLAINED
Imagine a treatment with the following properties:
| The treatment is good for men |
(E1) |
| The treatment is good for women |
(E2) |
| The treatment bad overall |
(E3) |
That’s the essence of Simpson’s paradox. But there is no such treatment. Statements (E1), (E2) and (E3) cannot all be true simultaneously.
Simpson’s paradox occurs when people equate three probabilistic statements (P1), (P2), (P3) described below, with the statements (E1), (E2), (E3) above. It turns out that (P1), (P2), (P3) can all be true. But, to repeat: (E1), (E2), (E3) cannot all be true.
The paradox is NOT that (P1), (P2), (P3) are all true. The paradox only occurs if you mistakenly equate (P1-P3) with (E1-E3).
1. Details
Throughout this post I’ll assume we have essentially an infinite sample size. The confusion about Simpson’s paradox is about population quantities so we needn’t focus on sampling error.
Assume that  is binary. The key probability statements are:
is binary. The key probability statements are:
Here, is the outcome ( means success,
means success, 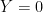 means failure),
means failure),  is treatment (
is treatment (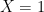 means treated,
means treated, 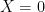 means not-treated) and
means not-treated) and  is sex (
is sex (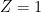 means male,
means male, 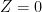 means female).
means female).
It is easy to construct numerical examples where (P1), (P2) and (P3) are all true. The confusion arises if we equate the three probability statements (P1-P3) with the English sentences (E1-E3).
To summarize: it is possible for (P1), (P2), (P3) to all be true. It is NOT possible for (E1), (E2), (E3) to all be true. The error is in equating (P1-P3) with (E1-E3).
To capture the English statements above, we need causal language, either counterfactuals or causal directed graphs. Either will do. I’ll use counterfactuals. (For an equivalent explanation using causal graphs, see Pearl 2000). Thus, we introduce 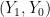 where
where 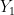 is your outcome if treated and
is your outcome if treated and  is your outcome if not treated. We observe
is your outcome if not treated. We observe

In other words, if we observe and if we observe . We never observe both and on any person. The correct translation of (E1), (E2) and (E3) is:
These three statements cannot simultaneously be true. Indeed, if the first two statements hold then
![\displaystyle \begin{array}{rcl} P(Y_1=1) - P(Y_0=1) &=& \sum_{z=0}^1 [P(Y_1=1|Z=z) - P(Y_0=1|Z=z)] P(z)\\ & > & 0. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+-+P%28Y_0%3D1%29+%26%3D%26+%5Csum_%7Bz%3D0%7D%5E1+%5BP%28Y_1%3D1%7CZ%3Dz%29+-+P%28Y_0%3D1%7CZ%3Dz%29%5D+P%28z%29%5C%5C+%26+%3E+%26+0.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Thus, (C1)+(C2) implies (not C3). If the treatment is good for mean and good for women then of course it is good overall.
To summarize, in general we have
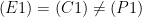


and, moreover (E3) cannot hold if both (E1) and (E2) hold.
The key is that, in general,
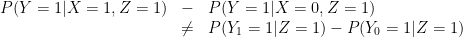
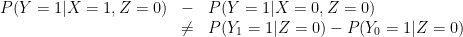
and
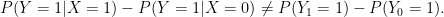
In other words, correlation (left hand side) is not equal to causation (right hand side).
Now, if treatment is randomly assigned, then is independent of 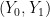 and
and

and so we will not observe the reversal, even for the correlation statements. That is, when is randomly assigned, (P1-P3) cannot all hold.
In the non-randomized case, we can only recover the causal effect by conditioning on all possible confounding variables  . (Recall a confounding variable is a variable that affects both and .) This is because is independent of conditional on (that’s what it means to control for confounders) and we have
. (Recall a confounding variable is a variable that affects both and .) This is because is independent of conditional on (that’s what it means to control for confounders) and we have

and similarly,  and so
and so
![\displaystyle \begin{array}{rcl} P(Y_1=1) &-& P(Y_0=1)\\ & = & \sum_w [P(Y=1|X=1,W=w) - P(Y=1|X=0,W=w) ] P(W=w) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+%26-%26+P%28Y_0%3D1%29%5C%5C+%26+%3D+%26+%5Csum_w+%5BP%28Y%3D1%7CX%3D1%2CW%3Dw%29+-+P%28Y%3D1%7CX%3D0%2CW%3Dw%29+%5D+P%28W%3Dw%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
which reduces the causal effect into a formula involving only observables. This is usually called the adjusted treatment effect. Now, if it should happen that there is only one confounding variable and it happens to be our variable then
![\displaystyle \begin{array}{rcl} P(Y_1=1) &-& P(Y_0=1)\\ &=& \sum_w [P(Y=1|X=1,Z=z) - P(Y=1|X=0,Z=z) ] P(Z=z). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+%26-%26+P%28Y_0%3D1%29%5C%5C+%26%3D%26+%5Csum_w+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29+-+P%28Y%3D1%7CX%3D0%2CZ%3Dz%29+%5D+P%28Z%3Dz%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
In this case we get the correct causal conclusion by conditioning on . That’s why people usually call the conditional answer correct and the unconditional statement misleading. But this is only true if is a confounding variable and, in fact, is the only confounding variable.
2. What’s the Right Answer?
Some texts make it seem as if the conditional answers (P2) and (P3) are correct and (P1) is wrong. This is not necessarily true. There are several possibilities:
- is a confounder and is the only confounder. Then (P3) is misleading and (P1) and (P2) are correct causal statements.
- There is no confounder. Moreover, conditioning on causes confounding. Yes, contrary to popular belief, conditioning on a non-confounder can sometimes cause confounding. (I discuss this more below.) In this case, (P3) is correct and (P1) and (P2) are misleading.
- is a confounder but there are other unobserved confounders. In this case, none of (P1), (P2) or (P3) are causally meaningful.
Without causal language— counterfactuals or causal graphs— it is impossible to describe Simpson’s paradox correctly. For example, Lindley and Novick (1981) tried to explain Simpson’s paradox using exchangeability. It doesn’t work. This is not meant to impugn Lindley or Novick— known for their important and influential work— but just to point out that you need the right language to correctly resolve a paradox. In this case, you need the language of causation.
3. Conditioning on Nonconfounders
I mentioned that conditioning on a non-confounder can actually create confounding. Pearl calls this  -bias. (For those familar with causal graphs, this is bascially the fact that conditioning on a collider creates dependence.)
-bias. (For those familar with causal graphs, this is bascially the fact that conditioning on a collider creates dependence.)
To elaborate, suppose I want to estimate the causal effect

If is a confounder (and is the only confounder) then we have the identity
![\displaystyle \theta = \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29+&bg=ffffff&fg=000000&s=0&c=20201002)
that is, the causal effect is equal to the adjusted treatment effect. Let us write
![\displaystyle \theta = g[ p(y|x,z),p(z)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+g%5B+p%28y%7Cx%2Cz%29%2Cp%28z%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
to indicate that the formula for  is a function of the distributions
is a function of the distributions  and
and 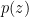 .
.
But, if is not a confounder, does the equality still hold? To simplify the discussion assume that there are no other confounders. Either is a confounder or there are no confounders. What is the correct identity for ? Is it

or
![\displaystyle \theta = \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z)?](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29%3F+&bg=ffffff&fg=000000&s=0&c=20201002)
The answer (under these assumptions) is this: if is not a confounder then the first identity is correct and if is a confounder then the second identity is correct. In the first case ![{\theta = g[p(y|x)]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%3D+g%5Bp%28y%7Cx%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Now, when there are no confounders, the first identity is correct. But is the second actually incorrect or will it give the same answer as the first? The answer is: sometimes they gave the same answer but it is possible to construct situations where
![\displaystyle \theta \neq \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%5Cneq+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
(This is something that Judea Pearl has often pointed out.) In these cases, the correct formula for the causal effect is the first one and it does not involve conditioning on . Put simply, conditioning on a non-confounder can (in certain situations) actually cause confounding.
4. Continuous Version
A continuous version of Simpson’s paradox, sometimes called the ecological fallacy, looks like this:

Here we see that increasing doses of drug lead to poorer outcomes (left plot). But when we separate the data by sex () the drug shows better outcomes for higher doses for both males and females.
5. A Blog Argument Resolved?
We saw that in some cases is a function of but in other cases it is only a function of 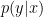 . This fact led to an interesting exchange between Andrew Gelman and Judea Pearl and, later, Pearl’s student Elias Bareinboim. See, for example, here and here and here.
. This fact led to an interesting exchange between Andrew Gelman and Judea Pearl and, later, Pearl’s student Elias Bareinboim. See, for example, here and here and here.
As I recall (Warning! my memory could be wrong), Pearl and Bareinboim were arguing that in some cases, the correct formula for the causal effect was the first one above which does not involve conditioning on . Andrew was arguing that conditioning was a good thing to do. This led to a heated exchange.
But I think they were talking past each other. When they said that one should not condition, they meant that the formula for the causal effect does not involve the conditional distribution . Andrew was talking about conditioning as a tool in data analysis. They were each using the word conditioning but they were referring to two different things. At least, that’s how it appeared to me.
6. References
For numerical examples of Simpson’s paradox, see the Wikipedia article.
Lindley, Dennis V and Novick, Melvin R. (1981). The role of exchangeability in inference. The Annals of Statistics, 9, 45-58.
Pearl, J. (2000). Causality: models, reasoning and inference, {Cambridge Univ Press}.










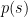
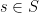


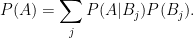

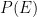
![\displaystyle \Bigl[\inf_j P(E|B_j),\ \sup_j P(E|B_j)\Bigr].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CBigl%5B%5Cinf_j+P%28E%7CB_j%29%2C%5C+%5Csup_j+P%28E%7CB_j%29%5CBigr%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)








 between a treated group and untreated group is not, in general, equal to the causal effect
between a treated group and untreated group is not, in general, equal to the causal effect  . This is easily proved using either the directed graph approach to causation or the counterfactual approach: see
. This is easily proved using either the directed graph approach to causation or the counterfactual approach: see  and
and  and you want to test
and you want to test  versus
versus  , you can get an exact, distribution-free test by using the permutation method. See
, you can get an exact, distribution-free test by using the permutation method. See  .)
.)

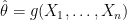 ,
,  and
and  is a sample from the empirical distribution. But the distribution
is a sample from the empirical distribution. But the distribution  is intractable. Instead, we approximate it by repeatedly sampling from the empirical distribution function. This makes otherwise intractable confidence intervals trivial to compute.
is intractable. Instead, we approximate it by repeatedly sampling from the empirical distribution function. This makes otherwise intractable confidence intervals trivial to compute. -means++. Minimizing the objective function in
-means++. Minimizing the objective function in 
You must be logged in to post a comment.