The Steep Price of Sparsity
We all love sparse estimators these days. I am referring to things like the lasso and related variable selection methods.
But there is a dark side to sparsity. It’s what Hannes Leeb and Benedikt Potscher call the “return of the Hodges’ estimator.” Basically, any estimator that is capable of producing sparse estimators has infinitely bad minimax risk.
1. Hodges Estimator
Let’s start by recalling Hodges famous example.
Suppose that 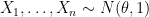
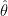




If 
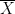

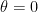


This seems like a good thing. This is what we want whenever we do model selection. We want to discover that some coefficients are 0. That’s the nature of using sparse methods.
But there is a price to pay for sparsity. The Hodges estimator has the unfortunate property that the maximum risk is terrible. Indeed,
![\displaystyle \sup_\theta \mathbb{E}_\theta [n (\hat\theta-\theta)^2] \rightarrow \infty.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Ctheta+%5Cmathbb%7BE%7D_%5Ctheta+%5Bn+%28%5Chat%5Ctheta-%5Ctheta%29%5E2%5D+%5Crightarrow+%5Cinfty.+&bg=ffffff&fg=000000&s=0&c=20201002)
Contrast this will the sample mean:
![\displaystyle \sup_\theta \mathbb{E}_\theta [n (\overline{X}-\theta)^2] =1.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Ctheta+%5Cmathbb%7BE%7D_%5Ctheta+%5Bn+%28%5Coverline%7BX%7D-%5Ctheta%29%5E2%5D+%3D1.+&bg=ffffff&fg=000000&s=0&c=20201002)
The reason for the poor behavior of the Hodges estimator — or any sparse estimator — is that there is a zone near 0 where the estimator will be very unstable. The estimator has to decide when to switch from
I plotted the risk function of the Hodges estimator here. The risk of the mle is flat. The large peaks in the risk function of the Hodges estimator are very clear (and very disturbing).
2. The Steep Price of Sparsity
Leeb and Potscher (2008) proved that this poor behavior holds for all sparse estimators and all loss functions. Suppose that

here, 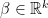



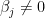




as 
Leeb and Potscher (2008) showed that if
![\displaystyle \sup_\beta E[ n\, ||\hat\beta-\beta||^2]\rightarrow \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Cbeta+E%5B+n%5C%2C+%7C%7C%5Chat%5Cbeta-%5Cbeta%7C%7C%5E2%5D%5Crightarrow+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002)
as 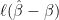
![\displaystyle \sup_\beta E[ \ell(n^{1/2}(\hat\beta -\beta))]\rightarrow \sup_\beta \ell(\beta).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Cbeta+E%5B+%5Cell%28n%5E%7B1%2F2%7D%28%5Chat%5Cbeta+-%5Cbeta%29%29%5D%5Crightarrow+%5Csup_%5Cbeta+%5Cell%28%5Cbeta%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
3. How Should We Interpret This Result?
One might object that the maximum risk is too conservative and includes extreme cases. But in this case, that is not true. The high values of the risk occur in a small neighborhood of 0. (Recall the picture of the risk of the Hodges estimator.) This is far from pathological.
Another objection is that the proof assumes 
I am not suggesting we should give up variable selection. I use variable selection all the time. But we should keep in mind that there is a steep price to pay for sparsistency.
References
Leeb, Hannes and Potscher, Benedikt M. (2008). Sparse estimators and the oracle property, or the return of Hodges’ estimator. Journal of Econometrics, 142, 201-211.
Leeb, Hannes and Potscher, Benedikt M. (2005). Model selection and inference: Facts and fiction. Econometric Theory, 21, 21-59.
 is multivariate Normal with mean vector
is multivariate Normal with mean vector  . Now suppose that we want to infer
. Now suppose that we want to infer  . The resulting posterior for
. The resulting posterior for  is a disaster. The coverage of the Bayesian
is a disaster. The coverage of the Bayesian 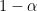 posterior interval can be close to 0.
posterior interval can be close to 0. is somehow noninformative for
is somehow noninformative for 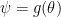 where
where 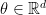 and
and  .
.