FLAT PRIORS IN FLATLAND: STONE’S PARADOX
Mervyn Stone is Emeritus Professor at University College London. He is famous for his work on Bayesian inference as well as pioneering work on cross-validation, coordinate-free multivariate analysis, as well as many other topics.
Today I want to discuss a famous example of his, described in Stone (1970, 1976, 1982). In technical jargon, he shows that “a finitely additive measure on the free group with two generators is nonconglomerable.” In English: even for a simple problem with a discrete parameters space, flat priors can lead to surprises. Fortunately, you don’t need to know anything about free groups to understand this example.
1. Hunting For a Treasure In Flatland
I wonder randomly in a two dimensional grid-world. I drag an elastic string with me. The string is taut: if I back up, the string leaves no slack. I can only move in four directions: North, South, West, East.
I wander around for a while then I stop and bury a treasure. Call the path  . Here is an example:
. Here is an example:

Now I take one more random step. Each direction has equal probability. Call the final path  . So it might look like this:
. So it might look like this:

Two people, Bob (a Bayesian) and Carla (a classical statistician) want to find the treasure. There are only four possible paths that could have yielded , namely:

Let us call these four paths N, S, W, E. The likelihood is the same for each of these. That is, 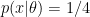 for
for 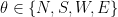 . Suppose Bob uses a flat prior. Since the likelihood is also flat, his posterior is
. Suppose Bob uses a flat prior. Since the likelihood is also flat, his posterior is
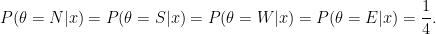
Let  be the three paths that extend . In this example,
be the three paths that extend . In this example,  . Then
. Then  .
.
Now Carla is very confident and selects a confidence set with only one path, namely, the path that shortens . In other words, Carla’s confidence set is 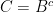 .
.
Notice the following strange thing: no matter what is, Carla gets the treasure with probability 3/4 while Bob gets the treasure with probability 1/4. That is, but the coverage of is 1/4. In other words,  for every . On the other hand, the coverage of
for every . On the other hand, the coverage of  is 3/4:
is 3/4:  for every .
for every .
Here is quote from Stone (1976): (except that I changed his B and C to Bob and Carla):
“ … it is clear that when Bob and Carla repeatedly engage in this treasure hunt, Bob will find that his posterior probability assignment becomes increasingly discrepant with his proportion of wins and that Carla is, somehow, doing better than [s]he ought. However, there is no message … that will allow Bob to escape from his Promethean situation; he cannot learn from his experience because each hunt is independent of the other.”
2. More Trouble For Bob
Let  be the event that the final step reduces the length of the string. Using his posterior distribution, Bob finds that
be the event that the final step reduces the length of the string. Using his posterior distribution, Bob finds that  for each . Since this holds for each , Bob deduces that
for each . Since this holds for each , Bob deduces that  .
.
On the other hand, Bob notes that  for every . Hence,
for every . Hence,  .
.
Bob has just proved that  .
.
3. The Source of The Problem
The apparent contradiction stems from the fact that the prior is improper. Technically this is an example of the non-conglomerability of finitely additive measures. For a rigorous explanation of why this happens you should read Stone’s papers. Here is an abbreviated explanation, from Kass and Wasserman (1996, Section 4.2.1).
Let  denotes Bob’s improper flat prior and let
denotes Bob’s improper flat prior and let 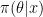 denote his posterior distribution. Let
denote his posterior distribution. Let 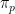 denote the prior that is uniform on the set of all paths of length
denote the prior that is uniform on the set of all paths of length  . This is of course a proper prior. For any fixed ,
. This is of course a proper prior. For any fixed ,  as
as 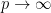 . So Bob can claim that his posterior distribution is a limit of well-defined posterior distributions. However, we need to look at this more closely. Let
. So Bob can claim that his posterior distribution is a limit of well-defined posterior distributions. However, we need to look at this more closely. Let 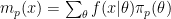 be the marginal of induced by . Let
be the marginal of induced by . Let 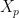 denote all ‘s of length or
denote all ‘s of length or  . When
. When  ,
,  is a poor approximation to since the former is concentrated on a single point while the latter is concentrated on four points. In fact, the total variation distance between and is 3/4 for . (Recall that the total variation distance between two probability measures
is a poor approximation to since the former is concentrated on a single point while the latter is concentrated on four points. In fact, the total variation distance between and is 3/4 for . (Recall that the total variation distance between two probability measures  and
and  is
is 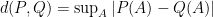 .) Furthermore, is a set with high probability:
.) Furthermore, is a set with high probability:  as .
as .
While converges to as  for any fixed , they are not close with high probability.
for any fixed , they are not close with high probability.
This problem disappears if you use a proper prior.
4. The Four Sided Die
Here is another description of the problem. Consider a four sided die whose sides are labeled with the symbols 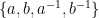 . We roll the die several times and we record the label on the lowermost face (there is a no uppermost face on a four-sided die). A typical outcome might look like this string of symbols:
. We roll the die several times and we record the label on the lowermost face (there is a no uppermost face on a four-sided die). A typical outcome might look like this string of symbols:

Now we apply an annihilation rule. If  and
and 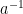 appear next to each other, we eliminate these two symbols. Similarly, if
appear next to each other, we eliminate these two symbols. Similarly, if  and
and  appear next to each other, we eliminate those two symbols. So the sequence above gets reduced to:
appear next to each other, we eliminate those two symbols. So the sequence above gets reduced to:
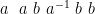
Let us denote the resulting string of symbols, after removing annihilations, by . Now we toss the die one more time. We add this last symbol to and we apply the annihilation rule once more. This results in a string which we will denote by .
You get to see and you want to infer .
Having observed , there are four possible values of and each has the same likelihood. For example, suppose 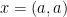 . Then has to be one of the following:
. Then has to be one of the following:

The likelihood function is constant over these four values.
Suppose we use a flat prior on . Then the posterior is uniform on these four possibilities. Let  denote the three values of that are longer than . Then the posterior satisfies
denote the three values of that are longer than . Then the posterior satisfies

Thus  is a 75 percent posterior confidence set.
is a 75 percent posterior confidence set.
However, the frequentist coverage of is 1/4. To see this, fix any . Now note that contains if and only if concatenated with is smaller than . This happens only if the last symbol is annihilated, which occurs with probability 1/4.
5. Likelihood
Another consequence of Stone’s example is that, in my opinion, it shows that the Likelihood Principle is bogus. According to the likelihood principle, the observed likelihood function contains all the useful information in the data. In this example, the likelihood does not distinguish the four possible parameter values.
But the direction of the string from the current position — which does not affect the likelihood — clearly has lots of information.
6. Proper Priors
If you want to have some fun, try coming up with proper priors on the set of paths. Then simulate the example, find the posterior and try to find the treasure.
Better yet, have a friend simulate the a path. Then you choose a prior, compute the posterior and guess where the treaure is. Repeat the game many times. Your friend generates a different path every time. If you try this, I’d be interested to hear about the simulation results.
Another question this example raises is: should we ever use improper priors? Flat priors that do not have mass can be interpreted as finitely additive priors. The father of Bayesian inference, Bruno DeFinetti, was adamant in rejecting the axiom of countable additivity. He thought flat priors like Bob’s were fine.
It seems to me that in modern Bayesian inference, there is not universal agreement on whether flat priors are evil or not. In some cases they work fine in others they don’t. For example, poorly chosen improper priors in random effects models can lead to improper (non-integrable) posteriors. But other improper priors don’t cause this problem.
In Stone’s example I think that most statisticians would reject Bob’s flat prior-based Bayesian inference.
7. Conclusion
I have always found this example to be interesting because it seems very simple and, at least at first, one doesn’t expect there to be a problem with using a flat prior. Technically the problems arise because there is group structure and the group is not amenable. Hidden beneath this seemingly simple example is some rather deep group theory.
Many of Stone’s papers are gems. They are not easy reading (with the exception of the 1976 paper) but they are worth the effort.
8. References
Stone, M. (1970). Necessary and sufficient condition for convergence in probability to invariant posterior distributions. The Annals of Mathematical Statistics, 41, 1349-1353,
Stone, M. (1976). Strong inconsistency from uniform priors. Journal of the American Statistical Association, 71, 114-116.
Stone, M. (1982). Review and analysis of some inconsistencies related to improper priors and finite additivity. Studies in Logic and the Foundations of Mathematics, 104, 413-426.
Kass, R.E. and Wasserman, L. (1996). The selection of prior distributions by formal rules. Journal of the American Statistical Association, 91, 1343-1370.

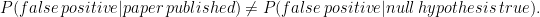
 and the alternative
and the alternative 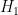 . In some fraction
. In some fraction  . Assume further that every test has the same power
. Assume further that every test has the same power 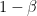 . Then the fraction of published studies with false findings is
. Then the fraction of published studies with false findings is 
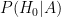 can be quite different from
can be quite different from 
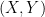 , with
, with  , the optimal classifier is to guess that
, the optimal classifier is to guess that  when
when  and to guess that
and to guess that 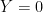 when
when  . This is often called the Bayes rule. This is confusing for many reasons. Since this rule is a sort of gold standard how about:
. This is often called the Bayes rule. This is confusing for many reasons. Since this rule is a sort of gold standard how about: people and
people and  gene expression measurements. The people are divided into two groups:
gene expression measurements. The people are divided into two groups:  are healthy, and
are healthy, and  null genes (in which there is actually no underlying difference between healthy and sick patients), and
null genes (in which there is actually no underlying difference between healthy and sick patients), and  non-nulls (in which there actually is a difference). All measurements are independent.
non-nulls (in which there actually is a difference). All measurements are independent.  -statistic
-statistic 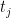 for each gene
for each gene 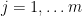 . We want to call some genes significant, by thresholding these
. We want to call some genes significant, by thresholding these ![\displaystyle \mathrm{FDR} = \mathop{\mathbb E}\left[\frac{number\ of\ null\ genes\ called\ significant}{number\ of\ genes\ called\ significant}\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BFDR%7D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B%5Cfrac%7Bnumber%5C++of%5C++null%5C++genes%5C++called%5C++significant%7D%7Bnumber%5C+of%5C++genes%5C++called%5C++significant%7D%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 from
from  , respectively. We first sort the
, respectively. We first sort the  ; then, given a level
; then, given a level  , we find the largest
, we find the largest  such that
such that 
 (and the corresponding genes) significant. It helps to think of this as a rule which rejects all
(and the corresponding genes) significant. It helps to think of this as a rule which rejects all  , for the cutoff
, for the cutoff  . The BH estimate for the FDR of this rule is simply
. The BH estimate for the FDR of this rule is simply  denote the
denote the  th permuted data set. Now consider the rule that rejects all
th permuted data set. Now consider the rule that rejects all 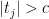 for some cutoff
for some cutoff  . The permutation estimate for the FDR of this rule is
. The permutation estimate for the FDR of this rule is 
 patients and
patients and  genes,
genes,  of which are null. The gene expression measurements are all drawn independently from a standard normal distribution with mean zero, except for the non-null genes, where the mean was chosen to be -1 or 1 (with equal probability) for the sick patients. The plot below shows the estimates as we vary the cutoff
of which are null. The gene expression measurements are all drawn independently from a standard normal distribution with mean zero, except for the non-null genes, where the mean was chosen to be -1 or 1 (with equal probability) for the sick patients. The plot below shows the estimates as we vary the cutoff 



You must be logged in to post a comment.