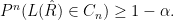Steve Marron is a statistician at UNC. In his younger days he was well known for his work on nonparametric theory. These days he works on a number of interesting things including analysis of structured objects (like tree-structured data) and high dimensional theory.
Steve sent me a thoughtful email the other day about “Big Data” and, with his permission, I am posting it here.
I agree with pretty much everything he says. I especially like these two gems: First, “a better funded statistical community would be a more efficient way to get such things done without all this highly funded re-discovery.” And second: “I can see a strong reason why it DOES NOT make sense to fund our community better. That is our community wide aversion to new ideas.”
Enough from me. Here is Steve’s comment:
Guest Post, by Steve Marron
My colleagues and I have lately been discussing “Big Data”, and your blog was mentioned.
Not surprisingly you’ve got some interesting ideas there. Here come some of my own thoughts on the matter.
First should one be pessimistic? I am not so sure. For me exhibit A is my own colleagues. When such things came up in the past (and I believe that this HAS happened, see the discussion below) my (at that time senior) colleagues were rather arrogantly ignorant. Issues such as you are raising were blatantly pooh poohed, if they were ever considered at all. However, this time around, I am seeing a far more different picture. My now mostly junior colleagues are taking this very seriously, and we are currently engaged in major discussion as to what we are going to do about this in very concrete terms such as course offerings, etc. In addition, while some of my colleagues think in terms of labels such as “applied statistician”, “theoretical statistician” and “probabilist”, everybody across the board is jumping in. Perhaps this is largely driven by an understanding that universities themselves are in a massive state of flux, and that one had better be a player, or else be totally left behind. But it sure looks better than some of the attitudes I saw earlier on in my career.
Now about the bigger picture. I think there is an important history here that you are totally ignoring. In particular, I view “Big Data” as just the latest manifestation of a cycle that has been rolling along for quite a long time. Actually I have been predicting the advent of something of this type for quite a while (although I could not predict the name, nor the central idea).
Here comes a personally slanted (certainly over-simplified) view of what I mean here. Think back on the following set of “exciting breakthroughs”:
– Statistical Pattern Recognition
– Artificial Intelligence
– Neural Nets
– Data Mining
– Machine Learning
Each of these was started up in EE/CS. Each was the fashionable hot topic (considered very sexy and fresh by funding agencies) of its day. Each was initially based on usually one really cool new idea, which was usually far outside of what folks working in conventional statistics had any hope (well certainly no encouragement from the statistical community) of dreaming up. I think each attracted much more NSF funding than all of statistics ever did, at any given time. A large share of the funding was used for re-invention of ideas that already existed in statistics (but would get a sexy new name). As each new field matured, there came a recognition that in fact much was to be gained by studying connections to statistics, so there was then lots of work “creating connections”.
Now given the timing of these, and how they each have played out, over time, it had been clear to me for some time that we were ripe for the next one. So the current advent of Big Data is no surprise at all. Frankly I am a little disappointed that there does not seem to be any really compelling new idea (e.g. as in neural nets or the kernel embedding idea that drove machine learning). But I suspect that the need for such a thing to happen to keep this community properly funded has overcome the need for an exciting new idea. Instead of new methodology, this seems to be more driven by parallelism and cloud computing. Also I seem to see larger applied math buy-in than there ever was in the past. Maybe this is the new parallel to how optimization has appeared in a major way in machine learning.
Next, what should we do about it? Number one of course is to get engaged, and as noted above, I am heartened at least at my own local level as discussed above.
I generally agree with your comment about funding, and I can think of ways to sell statistics. For example, we should make the above history clear to funding agencies, and point out that in each case there has been a huge waste of resources on people doing a large amount of rediscovery. In most of those areas, by the time the big funding hits, the main ideas are already developed so the funding really just keeps lots of journeymen doing lots of very low impact work, with large amounts of rediscovery of things already known in the statistical community. The sell could be that a better funded statistical community would be a more efficient way to get such things done without all on this highly funded re-discovery.
But before making such a case, I suggest that is it important to face up to our own shortcomings, from the perspective of funding agencies. I can see a strong reason why it DOES NOT make sense to fund our community better. That is our community wide aversion to new ideas. While I love working with statistical concepts, and have a personal love of new ideas, it has not escaped my notice that I have always been in something of a minority in that regard. We not only do not choose to reward creativity, we often tend to squelch it. I still remember the first time I applied for an NSF grant. I was ambitious, and the reviews I got back said the problem was interesting, but I had no track record, the reviewers were skeptical of me, and I did not get funded. This was especially frustrating as by the time I got those reviews I had solved the stated problem. It would be great if that could be regarded as an anomaly of the past when folks may have been less enlightened than now. However, I have direct evidence that this is not true. Unfortunately exactly that cycle repeated itself for one of my former students on this very last NSF cycle.
What should we do to deserve more funding? Somehow we need a bigger tent, which is big enough to include the creative folks who will be coming up with the next really big ideas (big enough to include the folks who are going to spawn the next new community, such as those listed above). This is where research funding should really be going to be most effective.
Maybe more important, we need to find a way to create a statistical culture that reveres new ideas, instead of fearing and shunning them.
Best, Steve
 . Define the risk of an estimator
. Define the risk of an estimator 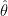 to be
to be 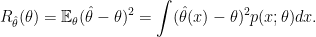
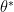 with smaller risk. In other words, if
with smaller risk. In other words, if 
 .
.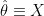 admissible.
admissible. where now
where now  ,
,  and
and 
 ,
, 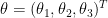 and
and  are independent. And the
are independent. And the  could have nothing to do with each other. For example,
could have nothing to do with each other. For example,  mass of the moon,
mass of the moon, 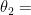 price of coffee and
price of coffee and 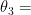 temperature in Rome.
temperature in Rome. is inadmissible if the dimension
is inadmissible if the dimension  of
of  .
.
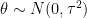 and
and  is estimated from the data. The Bayes explanation gives some nice intuition. But it’s also a bit misleading. The Bayes explanation suggests we are shrinking the means together because we expect them a priori to be similar. But the paradox holds even when the means are not related in any way.
is estimated from the data. The Bayes explanation gives some nice intuition. But it’s also a bit misleading. The Bayes explanation suggests we are shrinking the means together because we expect them a priori to be similar. But the paradox holds even when the means are not related in any way. . Suppose we have data
. Suppose we have data 
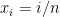 and
and 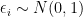 . Let us expand
. Let us expand  in an orthonormal basis:
in an orthonormal basis: 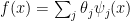 . To estimate
. To estimate  . Note that
. Note that  . This suggests the estimator
. This suggests the estimator 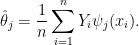
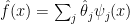 is useless because it is too wiggly. The solution is to smooth the estimator; this corresponds to shrinking the raw estimates
is useless because it is too wiggly. The solution is to smooth the estimator; this corresponds to shrinking the raw estimates 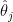 towards 0. This adds bias but reduces variance. In other words, the familiar process of smoothing, which we use all the time for function estimation, can be seen as “shrinking estimates towards 0” as with the James-Stein estimator.
towards 0. This adds bias but reduces variance. In other words, the familiar process of smoothing, which we use all the time for function estimation, can be seen as “shrinking estimates towards 0” as with the James-Stein estimator. is minimax, that is, it’s risk achieves the minimax bound
is minimax, that is, it’s risk achieves the minimax bound 
 of
of  is a constant. In fact,
is a constant. In fact, 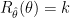 for all
for all  of the James-Stein estimator is less than the risk of
of the James-Stein estimator is less than the risk of 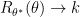 as
as 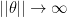 . So they have the same maximum risk.
. So they have the same maximum risk. denote all axis aligned rectangles in the plane. We can think of each rectangle
denote all axis aligned rectangles in the plane. We can think of each rectangle  as a classifier: predict
as a classifier: predict  if
if 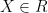 and predict
and predict 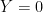 if
if  . Suppose we have data
. Suppose we have data 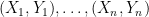 . If we pick the rectangle
. If we pick the rectangle 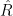 that makes the fewest classification errors on the data, will we predict well on a new observation? More formally: is the empirical risk estimator a good predictor?
that makes the fewest classification errors on the data, will we predict well on a new observation? More formally: is the empirical risk estimator a good predictor?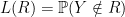 be the prediction risk and let
be the prediction risk and let 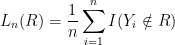
 is close to
is close to 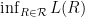 , with high probability. This fact follows easily if we can show that
, with high probability. This fact follows easily if we can show that 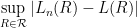
 , we have
, we have 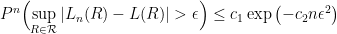
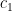 and
and  .
.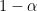 confidence interval for
confidence interval for ![\displaystyle C_n = [L_n(\hat R) - \epsilon_n,\ L_n(\hat R) + \epsilon_n]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++C_n+%3D+%5BL_n%28%5Chat+R%29+-+%5Cepsilon_n%2C%5C+L_n%28%5Chat+R%29+%2B+%5Cepsilon_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002)