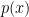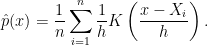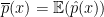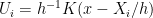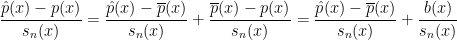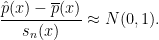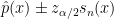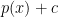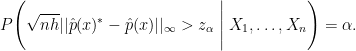The JSM, Minimaxity and the Language Police
I am back from the JSM. For those who don’t know, the JSM is the largest statistical meeting in the world. This year there were nearly 6,000 people.
Some people hate the JSM because it is too large. I love JSM. There is so much going on: lots of talks, receptions, tutorials and, of course, socializing. It’s impossible to walk 10 feet in any direction without bumping into another old friend.
1. Highlights
On Sunday I went to a session dedicated to the 70th birthday of my colleague Steve Fienberg. This was a great celebration of a good friend and remarkable statistician. Steve has more energy at 70 than I did when I was 20.
On a sadder note, I went to a memorial session for my late friend George Casella. Ed George, Bill Strawderman, Roger Berger, Jim Berger and Marty Wells talked about George’s many contributions and his huge impact on statistics. To borrow Ed’s catchphrase: what a good guy.
On Tuesday, I went to Judea Pearl’s medallion lecture, with discussions by Jamie Robins and Eric Tchetgen Tchetgen. Judea gave an unusual talk, mixing philosophy, metaphors (“eagles and snakes can’t build microscopes”) and math. Judea likes to argue that graphical models/structural equation models are the best way to view causation. Jamie and Eric argued that graphs can hide certain assumptions and that counterfactuals need to be used in addition to graphs.
Digression. There is another aspect of causation that deserves mention. It’s one thing to write down a general model to describe causation (using graphs or counterfactuals). It’s another matter altogether to construct estimators for the causal effects. Jamie Robins is well-known for his theory of “G-estimation”. At the risk of gross oversimplification, this is an approach to sequential causal modeling that eventually leads to semiparametric efficient estimators. The construction of these estimators is highly non-trivial. You can’t get them by just writing down a density for the graph and estimating the distribution. Nor can you just throw down some parametric models for the densities in the factorization implied by the graph. If you do, you will end up with a model in which there is no parameter that equals 0 when there is no causal effect. I call this the “null paradox.” And Jamie’s estimators are useful. Indeed, on Monday, there was a session called “Causal Inference in Observational Studies with Time-Varying Treatments.” All the talks were concerned with applying Jamie’s methods to develop estimators in real problems such as organ transplantation studies. The point is this: when it comes to causation, just writing down a model using graphs or counterfactuals is only a small part of the story. Finding estimators is often much more challenging.
End Digression.
On Wednesday, I had the honor of giving the Rietz Lecture (named after Henry Rietz, the first president of the Institute of Mathematical Statistics). I talked about Topological Inference. I will post the slides on my web page soon. I was fortunate to be introduced by my good friend Ed George.
2. Minimaxity
One thing that came up at my talk, but also in several discussions I had with people at the conference is the following problem. Recall that the minimax risk is
![\displaystyle R=\inf_{\hat \theta}\sup_{P\in {\cal P}}E_P[ L(\theta(P),\hat\theta)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++R%3D%5Cinf_%7B%5Chat+%5Ctheta%7D%5Csup_%7BP%5Cin+%7B%5Ccal+P%7D%7DE_P%5B+L%28%5Ctheta%28P%29%2C%5Chat%5Ctheta%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where  is a loss function,
is a loss function, 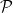 is a set of distributions and the infimum is over all estimators. Often we can define an estimator that achieves the minimax rate for a problem. But the estimator that achieves the risk
is a set of distributions and the infimum is over all estimators. Often we can define an estimator that achieves the minimax rate for a problem. But the estimator that achieves the risk  may not be computable in any practical sense. This happens in some of the topological problems I discussed. It also happens in sparse PCA problems. I suspect we are going to come across this issue more and more.
may not be computable in any practical sense. This happens in some of the topological problems I discussed. It also happens in sparse PCA problems. I suspect we are going to come across this issue more and more.
I suggested to a few people that we should really define the minimax risk by restricting 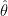 to be an estimator that can be computed in polynomial time. But how would we then compute the minimax risk? Some people, like Mike Jordan and Martin Wainwright, have made headway in studying the tradeoff between optimality and computation. But a general theory will be hard. I did mention this to Aad van der Vart at dinner one night. If anyone can make headway with this problem, it is Aad.
to be an estimator that can be computed in polynomial time. But how would we then compute the minimax risk? Some people, like Mike Jordan and Martin Wainwright, have made headway in studying the tradeoff between optimality and computation. But a general theory will be hard. I did mention this to Aad van der Vart at dinner one night. If anyone can make headway with this problem, it is Aad.
3. Montreal
The conference was in Montreal. If you have never been there, Montreal is a very pleasant city; vibrant and full of good restaurants. We had a very nice time including good dinners and cigars at a classy cigar bar.
Rant: The only bad thing about Montreal is the tyrannical language police. (As a dual citizen, I think I am allowed to criticize Canada!) Put a sign on your business only in English and go to jail. Very tolerant. This raises lots interesting problems: Is “pasta” English? What if you are using it as a proper name, as in naming your business: Pasta! And unless you live in North Korea, why should anyone be able to tell you what language to put on your private business? We heard one horror story that is almost funny. A software company opened in Montreal. The language police checked an approved of their signage. (Yes. They really pay people to do this.) Then they were told they had to write their code in French. I’m not even sure what this means. Is C code English or French? Anyway, the company left Montreal.
To be fair, it’s not just Montreal that lives under the brutal rule of bureaucrats and politicians. Every country does. But Canada does lean heavily toward arbitrary (i.e. favoring special groups) rules. Shane Jensen pointed me to Can’tada which lists stuff you can’t use in Canada.
End Rant.
Despite my rant, I think Montreal is a great city. I highly recommend it for travel.
4. Summary
The JSM is lots of fun. Yes, it is a bit overwhelming but where else can you find 6000 statisticians in one place? So next year, when I say I don’t want to go, someone remind me that I actually had a good time.