In the olden days, multiple testing meant testing 8 or 9 hypotheses. Today, multiple testing can involve testing thousands or even million of hypotheses.
A revolution occurred with the publication of Benjamini and Hochberg (1995). The method introduced in that paper has made it feasible to test huge numbers of hypotheses with high power. The Benjamini and Hochberg method is now standard in areas like genomics.
1. Multiple Testing
We want to test a large number of null hypotheses 

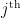
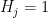
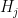
For each hypothesis 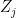
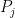


If we were testing one hypotheses, we would reject the null hypothesis if the p-value is less than 


A common and very simple way to fix the problem is the Bonferroni method: reject when 

It follows from the union bound that

where 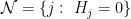
The problem with the Bonferroni method is that the power — the probability of rejecting 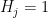
2. FDR
Instead of controlling the probability of any false rejections, the Benjamini-Hochberg (BH) method controls the false discovery rate (FDR) defined to be

where
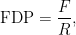


The BH method works as follows. Let

be the ordered p-values. The rejection set is

where 

(If the p-values are not independent, an adjustment may be required.) Benjamini and Hochberg proved that, if this method is used then 
3. Why Does It Work?
The original proof that
Suppose the fraction of true nulls is 
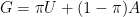
where 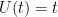


be the empirical distribution of the p-values. Suppose we reject all p-values less than 

and
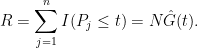
Thus,

and so

Now let 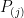



Setting the right hand side to be less than or equal to
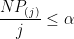
or in other words, choose 
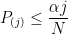
which is exactly the BH method.
To summarize: we reject all p-values less than
We then have the guarantee that 
The method is simple and, unlike Bonferroni, the power does not go to 0 as 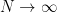
There are now many modifications to the BH method. For example, instead of controlling the mean of the FDP you can choose 

which is called FDP control. (Genovese and Wasserman 2006). One can also weight the p-values (Genovese, Roeder, and Wasserman 2006).
4. Limitations
FDR methods control the error rate while maintaining high power. But it is important to realize that these methods give weaker control than Bonferroni. FDR controls the (expected) fraction of false rejections. Bonferroni protects you from making any false rejections. Which you should use is very problem dependent.
5. References
Benjamini, Y. and Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological). 289–300.
Genovese, C.R. and Roeder, K. and Wasserman, L. (2006). False discovery control with p-value weighting. Biometrika, 93, 509-524.
Genovese, C.R. and Wasserman, L. (2006). Exceedance control of the false discovery proportion. Journal of the American Statistical Association, 101, 1408-1417.
Storey, J.D. and Taylor, J.E. and Siegmund, D. (2003). Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: a unified approach. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 66, 187–205.

12 Comments
I think the “limitations” section of this post is a little misleading. It says “Bonferroni protects you from making any false rejections.” That is not quite right: Bonferroni holds the overall (across-test) p-value to the specified alpha (usually 0.05), so that the probability of making one or more false rejections is equal to alpha (not zero).
Yes indeed
LW
If \pi=1, all rejections are false discoveries and FDR=1, isn’t it? So probably \pi<1 needs to be assumed but I don't see how the proof breaks down with \pi=1. I must be missing something. Or is it just that the statement holds for N to infinity and then j will converge to zero if \pi=1?
It’s a conservative upper bound but it allows you to get a threshold
without estimating pi.
OK, let me ask this again in a different way: Isn’t the FDR constant 1 if \pi=1? And doesn’t this imply that the given upper bound in this case is wrong? (I haven’t looked up literature to check this; the question comes just from the way you wrote it down. In the literature \pi=1 may be prohibited.)
Well we have:
FDR(t) <= Upper(t)
then setting Upper(t)=alpha and solving for t
gives a valid threshold t.
Sorry for still being stupid but if \pi=1 and alpha smaller, this has to be wrong because FDR=1 constant, no??
Probably my simplified derivation is just confusing.
Check out the original BH paper and I think it will be clearer
The FDR is precisely defined as E( F I( F > 0) /R ) rather than E (F/R), where I is the indicator function. Thus, if \pi = 1, the FDR is equal to FWER = Pr (F > 0) rather than 1. Such relationship between the FDR and FWER was pointed out in the original BH paper.
You say “FDR methods control the error rate while maintaining high power”. This is highly misleading. The “power” advantage is relative to other error controls, like FWER (as you explain). But there is no guarantee of absolute “power”. For a moderate FDR rate – say 10% – absolute “power” still depends crucially on how many true NULL’s are lurking. For “needle in the NULL haystack” applications (and there are many) FDR is no inferential panacea.
Embarrassingly dumb question. In section 3, how do you get from E(F/R) = E(F)/E(R) + O(N^(-1/2))?
Not a dumb question at all.
I am making an asymptotic approximation
(and it is not true without some assumptions)
Very roughly speaking, I am using the multivariate version of the delat method:
http://en.wikipedia.org/wiki/Delta_method