HOW CLOSE IS THE NORMAL DISTRIBUTION?
One of the first things you learn in probability is that the average 




where

and 
1. How Close?
But how close is the distribution of 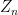

where 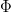

But these days we are often interested in high dimensional problems. In that case, we might be interested, not in one mean, but in many means. Is there still a good guarantee for closeness to the Normal limit?
Consider random vectors 

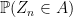
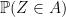


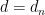

One of the best results I know of is due to Bentkus (2003) who proved that

where 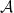




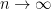
2. Ramping Up The Dimension
So far we need 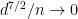
Yes. Right now we are witnessing a revolution in Normal approximations thanks to Stein’s method link.
This is a method for bounding the distance from Normal approximations invented by Charles Stein in 1972.
Although the method is 40 years old, there has recently been an explosion of interest in the method. Two excellent references are the book by Chen, Goldstein and Shao (2012) and the review article by Nathan Ross which can be found here.
An example of the power of this method is the very recent paper by Victor Chernozhukov, Denis Chetverikov and Kengo Kato. They showed that, if we restrict

as long as 
This is an astounding improvement. We only need 


The restriction to rectangles is not so bad; it leads immediately to a confidence rectangle for the mean, for example. The authors show that their results can be used to derive further results for bootstrapping, for high-dimensional regression and for hypothesis testing.
I think we are seeing the beginning of a new wave of results on high dimensional Berry-Esseen theorems. I will do a post in the future on Stein’s method.
References
Bentkus, Vidmantas. (2003). On the dependence of the Berry-Esseen bound on dimension. Journal of Statistical Planning and Inference, 385-402.
Chen, Louis Goldstein, Larry and Shao, Qi-Man. (2010). Normal approximation by Stein’s method. Springer.
Victor Chernozhukov, Denis Chetverikov and Kengo Kato. (2012). Central Limit Theorems and Multiplier Bootstrap when p is much larger than n. http://arxiv.org/abs/1212.6906.
Ross, Nathan. (2011). Fundamentals of Stein’s method. Probability Surveys, 8, 210-293.
Stein, Charles. (1986), Approximate computation of expectations. Lecture Notes-Monograph Series 7.

4 Comments
What still surprises me about statistics or the way statisticians do their business is the following: The Berry-Esseen theorem says that a confidence interval chosen based on the CLT is possibly shorter by a good amount of $c/\sqrt{n}$. Despite this, statisticians keep telling me that they prefer their “shorter” CLT-based confidence intervals to ones derived by using finite-sample tail inequalities that we, “machine learning people prefer” (lies vs. honesty?). I could never understood the logic behind this reasoning and I am wondering if I am missing something. One possible answer is that the Berry-Esseen result could be oftentimes loose. Indeed, if the summands are normally distributed, the difference will be zero. Thus, an interesting question is the study of the behavior of the worst-case deviation under assumptions (or: for what class of distributions is the Berry-Esseen result tight?). It would be interesting to read about this, or in general, why statisticians prefer to possibly make big mistakes to saying “I don’t know” more often.
I prefer finite sample intervals.
The problem is that there are many, many, many, practical problems where there aren’t
any known finite sample intervals and we are forced to use Normal approximations.
It’s by necessity not preference.
LW
Csaba:
You might find this paper of interest – Stigler, Stephen M. “The changing history of robustness.” The American Statistician 64.4 (2010): 277-281.
https://files.nyu.edu/ts43/public/research/.svn/text-base/Stigler.pdf.svn-base
Interesting read, thanks for the pointer!
So the conclusion, with an analogy from the paper, is: “In the United States many consumers are entranced by the magic of the new iPhone, even though they can only use it with the AT&T system, a system noted for spotty coverage—even no receivable signal at all under some conditions. But the magic available when it does work overwhelms the very real shortcomings.” So classical results are like iPhone.
I can understand this:) But then, again, I own an Android phone and tablet;)
2 Trackbacks
[…] Sobre teoremas de upper-bound para erros de aproximação pela curva normal (vale conferir uma sugestão que surgiu nos comentários do post, um texto histórico, bacana, […]
[…] Source URL: https://normaldeviate.wordpress.com/2013/02/04/how-close-is-the-normal-distribution/ […]