It’s been said a million times and in a million places that a p-value is not the probability of 
But there is a different type of confusion about p-values. This issue arose in a discussion on Andrew’s blog.
Andrew criticizes the New York times for giving a poor description of the meaning of p-values. Of course, I agree with him that being precise about these things is important. But, in reading the comments on Andrew’s blog, it occurred to me that there is often a double misunderstanding.
First, let me way that I am neither defending nor criticizing p-values in this post. I am just going to point out that there are really two misunderstandings floating around.
Two Misunderstandings
(1) The p-value is not the probability of
(2) But neither is the p-value the probability of something conditional on
Deborah Mayo pointed this fact out in the discussion on Andrew’s blog (as did a few other people).
When we use p-values we are in frequentist-land.
Let me get more specific. Let 

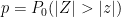
where 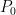

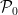

You could accuse me of being pedantic here or of being obsessed with notation. But given the amount of confusion about p-values, I think it is important to get it right.
More Misunderstandings
The same problem occurs when people write 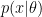



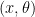
The coverage of a confidence interval 
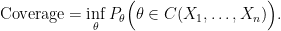
Again, there is no conditioning going on.
Conclusion
I understand that people often say “conditional on

45 Comments
Hi Larry, maybe this is getting overly detailed, but thought I’d bring up the ‘z’ variable from Efron’s two-groups model of hypothesis testing (in his 2008-or-so paper I think, that he uses to set up his Bayesian view of FDR). P(x|z=1) ~ H0, and P(x|z=0) ~ (something else). Then saying “the p-value is from a prob distribution conditional on H0” is just a sloppy way of saying “conditional on z=1”, where the ‘z’ variable indicates whether the null hypothesis is “active” or not.
Now you can’t do full Bayesian inference over this conditioning operator of course, given you don’t have a distribution for the z=0 case (though you can do some things like derive the Benjamini-Hochberg FDR bound), but surely P(x|z=1) is a conditional probability?
Good point.
When testing thousands of hypotheses
it does make sense to introduce a distribution on Z
(null true or false).
But that’s precisely because there is a frequency distribution of Z
in those cases.
So if z and h are random variables them it’s permissible to say P(z,h) = P(z|h)P(h). If P(h) ~ N(h0,sigma) then everything is fine and you have no objections. But if you consider the limit sigma-> 0 then P(h)->delta(h-h0).
Do you still consider h a random variable when it’s distribution is a delta function about h0? If not, then in the limit do we have to change the notation to read P(z;h)? Can we say P(z | h) -> P(z ; h0) as sigma ->0?
If you do consider h to still be a random variable in this limit, then what, pedantically speaking is the difference between P(z ; h0) and P(z | h) in the limit when sigma -> 0? What exactly is it about this limit that completely changes the philosophical meaning of these symbols?
Larry:
I think it’s a difference in notation rather than a misunderstanding. I like what Juho Kokkala wrote in a comment:
To put it another way, all these notations say the same thing in practice but they have different implications. If, like me, you use Juho’s definition (2), you’re putting people on the slippery slope toward assigning probabilities to B and sliding into definition (1). If, like Larry, you restrict conditional probability to definition (1), you’re drawing a bright line between different sorts of problems. The notation that Juho and I prefer is more convenient for Bayesians because then we don’t have to switch notation when we allow a parameter to be estimated. The notation that Larry prefers is more convenient for Larrys because then it makes clear that some symbols represent random variables while others are constant.
So, contrary to Larry’s claim above, I don’t think Juho and I are misunderstanding anything. I think we just have different uses in mind. The p-value, classical or otherwise, is indeed a probability conditional on an assumption. The difference between us and Larry is that we are happy to use the same notation for Pr(A|B) whether or not B is a random variable. I can see why Larry prefers to use different notation (e.g., Pr(A;B) or Fr(A|b)) but I can also see why such a distinction, helpful as it would be to Larry, would just get in the way for me.
Andrew, I wouldn’t disagree, but I don’t think it’s quite as simple as saying let them have their notation and we’ll have ours. The reason is hinted at in my comment above. If you consider P(h)~N(h0,sigma) then for both Bayesian and Frequentists everything is the same. But if you let sigma->0 then P(h) is a delta function about h0. In other words, h isn’t a random variable at all, it’s just the constant h0.
This causes a Frequentist to treat P(h) very different when sigma incredibly small from the case when the sigma-> 0 limit is taken. Both practically and philosophically it’s hard to see why “N(h0,sigma) when sigma is very close to zero” should be treated any different “h is always fixed at h0”.
Frequentist need to explain why these are so different. Why exactly is Bayes Theorem and Bayesian results perfectly legitimate for P(h)~N(h0, 10^{-10000000}) but not for P(h)=delta(h-h0)?
If they should be treated the same this puts quite a strong constraint on Frequentist methods, which many of their beloved results may not satisfy.
As Larry has written, frequentists are not so hung up on consistency as (some) Bayesians are, so I’d expect that a frequentist such as Larry would readily accept that there are problem domains where his methods would be inappropriate. I’m just guessing here, but I think Larry might say that Bayesian methods are particularly useful for predictive models with many levels of uncertainty (such as the sorts of multilevel problems I work on, modeling survey responses given many different factors), whereas he might say that frequentist methods are particularly useful for problems with clearly defined parameters for which rigorous inference is desired. This doesn’t directly address your question but it addresses the meta-issue. You have a Bayesian perspective and would like an overarching theory and notation that can work for all problems. Larry has a pluralistic frequentist perspective and is suspicious of any overarching theory, given his experience that different methods work well on different problems.
I think I’ve solved this notational issue in a way Frequentists can accept. An example will illustrate. Suppose we want to know a length mu. Instead of writing:
P(data ; mu)
since mu is a fixed quantity. However macroscopic objects actually fluctuate in length because of microscopic movements of atoms. Thus, P(mu) is actually distributed N(mu0, sigma=10^{-50}). That way we can write:
P(data | mu)
and it’s just a regular old conditional probability which everyone can accept as such. This wont affect equations in practice since sigma=10^{-50} is too small, but everyone agrees they are conditional probabilities and uses the same notation for them.
I think I’ve healed some deep, deep divisions here. Frequentists and Bayesians came come together like East and West Germany. Larry, tare down this wall!
Entsophy’s comment is actually revealing. He’s pointed out that the null hypothesis isn’t (almost ever) an exact point, therefore deserves a probability measure.
Everyone knows that an exact point null hypothesis is almost certainly false. Herman Rubin has stated this often. He states that it does not take any data at all for him to know that the null hypothesis, whatever it is, is false. Jim Berger has noted that even in a case that you might think the null hypothesis is really false (my plants will grow faster if I talk to them), there will inevitably be defects in the experiment that will contaminate the data to an extent that will eventually, with enough data, reject the null (for example, you forgot that talking to your plants gives them a small but not-insignificant amount of extra carbon dioxide that will make them grow faster).
This whole p-value and alpha-level-rejection stuff is not what we should be talking about. Again, as Herman Rubin has often said, the context should be decision theory, since the whole point of doing these experiments and investigations is to DECIDE what to do. Approve this drug? Buy that stock? Whatever.
And you can’t make rational decisions by simply setting an arbitrary alpha level, or looking at a p-value.
You have to have a loss function, and unfortunately, different actors will have different loss functions that will yield different decions. That means that the loss function is subjective. Sorry, folks, that makes all of this discussion moot, in my opinion.
And, BTW, as Wald proved, frequentist decision theory and Bayesian decision theory coincide in the sense that admissible decision rules are Bayes rules.
I agree this is a notation matter, not necessarily a misunderstanding. Many frequentists also write the likelihood as $P(X=x \vert \theta)$ while they do not interpret $\theta$ as a random variable.
I fully agree with Andrew that, from an objective perspective, there is no misunderstanding whatsoever. Unless you get into arcane measure theory details, conditioning upon a value and taking this value as fixed amount to the same thing. Discussing about notations does not seem like an optimal use of our time (times?)…
Agreed completely, but some people are whether this makes sense philosophically. Maybe this is a question for Dr. Mayo. Philosophically, what exactly is the difference between P(h)~N(h0, 10^{-10000000}) and P(h)=delta(h-h0) that would cause one to write “P(z|h)” as a conditional probability for the former case, but “P(z ; h)” as an unconditional probability in the later, and then to treat them very differently?
Agreement doesn’t make it so; it’s incorrect in a non-trivial manner and actually, indirectly, leads to the so-called prosecutor’s fallacy.
Andrew
I was not suggesting that YOU misunderstood anything.
I am talking about how best to communicate definitions to non-statisticians
(like NY times writers)
so they don’t get confused.
Larry
Entsophy has just a few things mixed up in his comment…among many…P(h) is P(z;h)? delta what?
Mayo: Entsophy is referring to the Dirac delta function; as a distribution for the random variable h, it makes h a constant random variable that takes the value h0 on element of the sample space.
Mayo, in words the issue is this: Frequentists treat h very differently depending on whether h is a random variable or a fixed quantity. This might be tenable if there was a sharp distinction between “random variables” and “fixed quantities”, but no such sharp distinction exists. One way to see this is that if h~N(mu,sigma) and sigma is very close to zero, then effectively h is the fixed quantity mu.
My comments on this issue follow:
Definition of p-values: “under H_0″ means a family of probability measures induced by T that are indexed by theta \in \Theta_0.
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143537
Response to Jugo: “conditional probability” and “conditional knowledge” are different concepts
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143603
Response to Bill Jefferys: why a classical statistitian do not set P(Theta0) = 1?
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143628
and
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143629
My comments on this issue follow:
Definition of p-values: “under H_0″ means a family of probability measures induced by T that are indexed by theta \in \Theta_0 (it is just a set of indexes).
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143537
Response to Jugo: “conditional probability” and “conditional knowledge” are different concepts
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143603
Response to Bill Jefferys: why a classical statistitian does not set P(Theta0) = 1?
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143628
and
http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143629
A very intriguing post! I enjoyed it. Glad to see some statisticians taking time to reflect on philosophical aspects of the subject: my role, as I currently see it, is to bridge the gap between statistics and philosophy.
I agree with Andrew, by and large it is much easier to think of them as a set of conditional probabilities, for example sufficiency can be expressed elegantly in terms of conditional independence, i.e. X ⫫θ | S
It should be acknowledged though, as Christian notes, this link can break in some weird cases when the family P_\theta is not absolutely continuous w.r.t. a single measure:
http://projecteuclid.org/euclid.aos/1176345895
Why a classical statistician cannot set a probability measure over a family of probabilities?
You (Bayesian) can set a probability for the null hypothesis or equivalently for the null parameter space, but you cannot do that in all contexts. I also can plant a big tree in my bathroom, but I will not do that, since it will obstruct a lot my way. Got it? If not, let me explain again:
Let Theta be our parameter space, that is, in a classical context, it is a set of indexes for our family of possible measures: F = {P_theta; theta in Theta}. That is, all P_theta, for theta in Theta are possible measures to govern the data behaviour. That is the beginning, OK? that is the context for a classical statistician!!
Does this mean that we are giving probability one to the family F? NO, it does not at all!! Let’s see why?
Suppose Q(F) =1, where Q is a probability measure. Then what are the implications of it?
1. Q(F) = 1 and Q(Empty) = 0
2. If F1 and F2 are two disjoint subfamilies of F, then Q(F1 U F2) = Q(F1) + Q(F2)
Supposing that F is a dense set (which is not rare in practice), we have the following implications:
a) We know from the Banach-Tarsky paradox that there are many subsets in our family F that cannot be measured by using probability rules. That is, it is not possible to compute probability for all elements of the power set of F. A possibility measure can measure all elements of the power set!!!!!!
b) For each P_theta in F, we trivially have that Q( P_theta ) = 0. Here we have a problem: I start saying that P_theta has full possibility one, now it has probability zero, is it not strange? Of course it is!! why?? because we cannot set probabilities if we start with possibilities.
That is, Q cannot be a probability measure if we want to consider possible all elements of F. Got it? If not, I am sorry but I cannot explain it here unless you want to understand what I am trying to say.
PS:
my original post: http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143684
see also this post: http://andrewgelman.com/2013/03/12/misunderstanding-the-p-value/#comment-143628
But by assumption, probability measures are only required to be countably additive. Hence the inference “For each P_theta in F, Q( P_theta ) = 0. Hence Q(F) = 0” is invalid. (And Banach-Tarski and nonmeasurable sets in general require the full Axiom of Choice and can’t be proved to exist under the slightly weaker Axiom of Dependent Choice, which is itself strong enough to develop most of analysis…)
“For each P_theta in F, Q( P_theta ) = 0. Hence Q(F) = 0″ that is not the inference I made.
In a classical analysis we want that Q(P_theta) > 0, since all have possibility one to be chosen as the data generator.
Corey,
Love the point about the Axiom of Choice. My misspent youth included years working towards a Ph.D. in Mathematical logic. My adviser was Randall Dougherty. I believe won the Putnam exam twice and came in second once. (Note for Gelman: since this is a hot topic lately, Dougherty definitely wasn’t Jewish). The other Logic prof I spent some time with was Harvey Friedman. He was a tenured faculty member in three departments at Stanford by the time he was 19. He spent most of his career trying to create a combinatorics problem that real mathematicians would care about, or at least find natural, who’s answer depended on the Axiom of Choice. I don’t think he succeeded.
Obviously though, mentioning the Axiom of Choice in a debate has exactly the same affect as mentioning Hitler. Everyone stops reading.
You got me hooked on Gregory Chaitin’s work by some offhand comments about it by the way.
Entsophy (and Corey),
I do not not if you are referring to me, I did not stop reading anything, I just corrected that I was not doing the inference Corey claimed I did.
Here, the tale follows: Once upon a time, we start giving possibility one for all probability measures in our family. We do not use the rules of probabilities to choose which probabilities will be included in our initial family. Then a (dogmatic) Bayesian appears to say that we SHOULD set a probability measure for our family of probabilities. (S)he wants me to have the same problems (s)he has with probability over a set of probabilities, but we have a choice to choose not have such problems, then (s)he gets mad and when we try to explain why we do not have such problems, (s)he becomes deaf. The end.
Corey,
Can you see why does a classical statistician not define a prior probability measure for the family F?
There has nothing to do with: “For each P_theta in F, Q( P_theta ) = 0. Hence Q(F) = 0″. In a classical context, the problem is to set probability zero for each “P_theta in F” that has full possibility to occur.
The difference between classical and Bayesian statisticians is that:
1. Classical statisticians define possibilities over the power set of F (since for a classical statistician, subsets of F are not random events),
2. Bayesian statisticians define probabilities over a sigma-field of F.
When Bayesians interpret classical quantities by using their tools, they will fail since they will use rules that do not apply, that is, these rules are being used out of the context.
The buzzes around this problem are just because Bayesians think that all types of uncertainties should be modelled by using probability measures, which is an exaggerated restriction. Some of them are so dogmatic on this that want to impose their restricted view of the world to all of us.
I am looking forward to hearing your response.
Best regards,
Alexandre.
My mistake Alexandre; my eyes skated over the word “possibility”. (Similar to this.)
Alexandre,
Oh, I see now. I hadn’t realized that Bayesians were just jealous because Frequentist methods are problem free. Those Bayesians sure are a bunch of scoundrels. If I see one in the street I’ll be sure to poke them in the eye.
Entsophy,
I never said that “Frequentist methods are problem free”. I do not know if Bayesians are jealous, but certainly most of them think they are right setting probabilities for the subsets of our family F and to interpret every thing by using probabilities. It is their mistake and I hope that one day they will realise that and start being a little more flexible and open-minded.
Most Bayesians like to make fan with classical methods saying that they are incoherent, however, most of them do not know that there are many ways of defining coherence (not just by linear games), they live in a very restricted world.
Entsophy,
If you could provide a good argument against what I write (possibility measures over the power set of F) I would appreciate.
Please, be as precise as possible to show where you disagree with me. Critics on marginal sentences do not matter at all, please go through the core of my arguments. I really want to see your point.
I am still waiting for a good-and-deep argument against what I have said here and in Gelman’s blog.
All the best
Alexandre Patriota.
Larry:
The _solution_ of sup over the NULL, has always seemed bogus to me and I recall it not being universally accepted.
(And in applications its almost always required – but I prefer plots of type one error rate over the NULL space)
This was interesting all right, also, can you hear the popcorn blasting in the offing? Oh no, it is students’ heads.
Alexandre,
Bill Jefferys, Daniel Lakeland, O’Rourke, and Gelman all addressed your points. Looking over their comments I can’t find anything to disagree with. I will add some points in no particular order:
(1) You make a passionate case that Frequentists should be using “possibility measures” rather than “probability measures” for theta and that the distinction is important. And yet Frequentists themselves often do use “probability measures” in this case. If a Frequentist can interpret theta as a random variable, they seem to have no problem with putting a probability distribution on it and using it the way a Bayesian would.
(2) There’s also the continuity issue alluded to in previous comments. If theta ~N(theta_0, 10^{-10000000000}) then there is absolutely no practical difference between this and treating theta as if it were fixed. Yet in one case you would use a “probability measure” and in the other you would use a “possibility measure”.
(3) The real point of the sum and product rule of probability, which you are so eager to avoid using in this case, is to count things correctly. For example, if you’re asked to find the probability of a given hand in poker, you’ll be implicitly using the sum and product rule many times in order to count the number of possibilities which lead to that hand. That’s why it’s so easy to motivate the axioms of probability theory using Venn diagrams (those rules are essentially related to “counting things”). The reason I mention this is because probabilities on singular events or fixed hypothesis also involve exactly this kind of counting. For example, if you’re asked to find the probability that the Democrats will win the next election, then one way to do this is to count (within some model) the number of states of the model compatible with what we know which result in a Democrat win. Counting these states requires the same rules of probability as does counting the outcomes in a hand of poker. Now Frequentists seem to be congenitally unable to understand this point, and refuse to admit that it’s even possible to talk about Pr(Democrats win next election), but so what? I understand it perfectly and will continue to use the probabilities in order to get it right.
(4) For reasons given by Lakeland, Corey as well as other reasons not stated, the Banach-Tarsky paradox is completely irrelevant for either the practice or principles of Statistics. If your argument in any way depends essentially on the Banach-Tarsky paradox, or any other similar considerations, then you may be making some interesting points about a certain mathematical structure, but you aren’t saying anything relevant to either the practice or foundations of Statistics.
(5) The NY Times couldn’t get P-values right. When Gelman brought it up it resulted in 139 comments arguing about it. Yet whenever I’ve had to do a statistical test comparing two means I just used the Bayesian P(mu1 > mu2 | data) and never had anyone, no matter how little statistical education they had, misunderstand this in the slightest. So why should I even care whether you can make P-values comprehensible after a great deal of effort?
Entsophy:
I disagree strongly with point 5.
People think they understand Pr(parameter |data) clearly but they don’t.
As I have explained before, you can have Pr(mu in A|Data) =.95 and yet
the frequency coverage of A can be 0.
I think the clarity you see in interpreting posterior probabilities
is at the high cost of refusing to think about the operating characteristics
of these posterior probabilities. The conceptual simplicity of Bayes is
an artefact of sweeping difficult problems under the rug.
Larry
Larry,
I respect your point and don’t wish to minimize it, but I will add a clarification. Although as a Bayesian I probably identify the most with Gelman, I seem to be off the reservation in many ways. One of those ways is relevant to your point.
Probability distributions (priors, sampling and posteriors) need to have the property that the true values lie in the high probability region of the distribution. If that doesn’t happen then all kinds of bad things happen. If it does happen, then you can get away with all kinds of things which look strange to a Frequentist. For example if you’re trying to weight yourself you will get perfectly fine results using the prior ~N(0,70 tons) even though P(weight<0)=.5. The fact is that your weight is guaranteed to be in the high probability manifold of this prior (i.e. the statement "my weight is between -70 tons and +70 tons" is actually true) and when you plug it into Bayes theorem nothing bad will happen.
This is why incidentally both Frequentist and Bayesian intervals stick to closely to high probability regions in practice, with the only common exception being the often controversial one-sided tests. This is true even though from a Frequentist perspective every A that satisfies Pr(mu in A)=.95 is on an equal footing.
Have to agree with these
“high cost of refusing to think about the operating characteristics
of these posterior probabilities.”
“The conceptual simplicity of Bayes is an artefact of sweeping difficult problems under the rug.”
(Both in the choice of prior and how the posterior is _used_)
Entsophy,
“Bill Jefferys, Daniel Lakeland, O’Rourke, and Gelman all addressed your points. ”
Actually, none of them properly addressed my below point. You are reading with your probabilistic bias and it seems that you really not understand what I said, but that is my fault, isn’t?
**Again, considering dense sets: For each P_theta in F, we trivially have that Q( P_theta ) = 0, if Q is a probability. Here we have a problem: I start saying that P_theta has full possibility one, now it has probability zero, is it not strange? Of course it is!! why?? because we cannot set probabilities if we start with possibilities.
**Again, since none one is taking into account: If you say that a dense null set has probability one, you are implicitly imposing that each element of this null set has probability zero, when we previously define possibility ONE for each of them. The issue of testing sharp hypothesis is a tough problem for Bayesian not for a frequenstist, and do you know why?
I tell you: because Bayesians always impose a prior probability over the (null or the full) parameter space. Classical statisticians just set a possibility measure. There is a huge difference, since the former CANNOT perform sharp tests while the latter can. A test is sharp when the dimension of the null parameter space Theta0 is smaller the the full parameter space Theta.
Your comment (2): it seems you are considering that Theta0 has only one element
Your comment (3): frequentist use frequencies to justify probabilities. We do not implicit use the probability rules for these problems, we EXPLICIT use them!
Your comment (4): it has practical impact. See my comment above about sharp tests. Bayesians cannot do it (if you cite “Bayes factors”, you must know that they have intrinsic problems).
Your comment (5): Larry answered it.
The core of my point is above in “**”, do you think that you addressed them?
Alexandre,
You may want to spend some time reviewing Generalized Functions Theory, in particular, the Dirac Delta Function. I stand by my claim that any argument that depends critically on quirks of measure theory/set theory is precisely irrelevant for either the practice or foundations of statistics.
Entsophy,
We can use the Dirac delta function to represent the density of a degenerate random variable when our null hypothesis is of the type: ‘H0: theta = theta0′. I just repeat this many times, but I did not use “Dirac delta function”, just because we do not need necessarily to use this term.
I understand what your are saying, but I think you did not get what I am saying, otherwise you would demonstrate in your comments.
It seems that you do not realize that it is full possible to have null hypotheses that have uncountable many elements and that by setting a probability measure on them you are forcing many subsets (including the singletons’ ones) to have zero probability. This can be done under a Bayesian approach, but they have to face the problems (see the sharp tests…)
You find irrelevant the peculiarities of measure theory to the foundations of statistics, that is the reason you cannot see what I am saying. You did not addressed my raised points and it is quite obvious that you don’t want to understand what I am saying.
Above all, it was nice to chat with you.
Best regards,
Alexandre.
Entsophy,
Maybe we agree in one thing: we cannot use only measure theory to the foundations of statistics. As you can see, possibility measures are not part of the classical measure theory. However, if we define properly a p-value, we see that it is an induced measure from a statistics T that is build for a null set Theta0. The implications of it are deduced from measure theory.
I think that general belief functions are fully applied to the foundations of statistics, but any statisticians devote attention to them.
I also think this isn’t really a misunderstanding and more a matter of speech. The p-value might not be the conditional probability in the formal sense, but it is certain a probably which is conditional to a hypothesis being true.
What is the real problem which if
A implies B
and B states that your statistic X has a certain probability measure P,
writing p(X) = P(X|B)? The theorem of Bayes does not apply, but this is clear since we do not have a probability measure on B. This includes the case when A is itself governed by a probability measure in which it coincides with the usual definition. In fact, this is what I would I prefer. I don’t see the point of introducing hypothetical pseudo probability at all.
Frankly, I get the point but I don’t see the importance. What is the argued danger of this misunderstanding? Mayo mentions the prosecutor’s fallacy, but I don’t the relevance here. This seems to be caused more by the misunderstanding originally commented on by Andrew in his blog. You can resolve it both in a Bayesian way, by thinking about what your prior should look like or in a frequentist way, by noticing that you actually look at a sample of people dragged before the court and not a random sample of the population. The problem is only that the null hypothesis is not just that the accused is innocent but that the accused is innocent and stands accused of a crime anyway.
And this resolves the fallacy quite nicely, if we think of a DNA match even if expressed as “conditional probabilites”:
P(DNA match|Innocent is small) is low and not relevant.
P(DNA match|Innocent and dragged before court based on random DNA matching) is high, but
P(DNA match|Innocent but was identified by victim) is again low. Both make sense.
Mistaking the p-value for the probability of the null hypothesis being true is clearly dangerous. That’s important. But the discussion here seems to me just to be a quibble.
Erik,
“What is the real problem which if A implies B and B states that your statistic X has a certain probability measure P, writing p(X) = P(X|B)? ”
1. A first problem is when B states a family of distributions for your statistics X rather than a unique distribution for X, let’s call this family by F_B. There will be only one distribution if B states a singleton or if your statistic X was ancillary to that family implied by B (this happens asymptotically under mild regular conditions and happens also under normality). Once this is understood, you may not write, in general, that p(X) = P(X|B) or p(X) = P(X; under B) since this equality is not always well defined. In the parametric context, let’s suppose that B states that theta lies in a null set Theta_B, then it should be write as:
p(X) \in F_B, where F_B = {P_theta, theta \in Theta_B }
and you may want to choose the most conservative p-value taking the sup over F_B.
Note that, if Theta_B = { b }, then the following equality is well defined: p(X) = P_b(X). But this is only valid when Theta_B has one element or when our statistics X is ancillary to F_B.
2. Let’s assume that Theta is the real line and our null hypothesis is Theta_B = { b }, if you write p(X) = P(X| theta = b) you are implicitly saying that there are different probability spaces for the full and the null parameter spaces. As Theta_b is a singleton, we have a problem in this definition since “P(X| theta = b)” does not correspond exactly to the conditional probability definition. What is the probability of A given B when P(B) = 0? as far as I know it is not well defined. If we define our p-value by using an ill-defined definition, we will be contributing to more controversies on this subject.
3. Let’s suppose that our statistic X is ancillary to the null family of probability measures F_B. The same problem described in 2. happens here in the writing “p(X) = P(X|B)”.
My suggestion is: if you are a Bayesian and wants to explain what is a p-value you should not use prior probabilities to do this, instead you can use prior possibilities. That is, you must do an effort for not assigning any probability distributions for the full and null parameter spaces.
Best,
Alexnadre.
Hi Larry,
I am very glad to see you make this point: I think it /is/ important that we preserve the distinction between ‘;’ and ‘|’. A related point is that confusion arises when people try to make the probability measure ‘conditional on all available information, H’, and write p(X | H), or something similar. Clearly, H is the inferential basis for p, and is /not/ a random quantity within p. Logical (or necessary) Bayesians have the best reason for writing p(X | H), I suppose, but in this case p would have to be the primeval probability measure.
I inform my students that Frequentist statisticians treat theta as the index of a family of distributions, hence writing X ~ f_X(x ; theta), but that Bayesian statisticians are comfortable treating theta itself as a random quantity, and are thus able to interpet f_X(x ; t) as p(X = x | theta = t). I don’t think it is helpful to write f_X(x | t) but I do write f_{X | theta}(x | t) as I tend not to use p() — it’s a bit inky but at least it is clear.
Jonathan.
An interesting post from the Eran’s blog relating one of the “problems” of the p-values: http://eranraviv.com/blog/on-p-value/
It was re-posted at the R-bloggers: http://www.r-bloggers.com/on-p-value/
Usually I don’t read article on blogs, but I would like to say that this write-up very compelled me to take a look at and do so! Your writing taste has been surprised me. Thank you, very nice post.
8 Trackbacks
[…] Double Misunderstandings About p-values – Normal Deviate… […]
[…] subtle discussion on the correct (frequentist) definition of the p-value that currently continues on Larry Wasserman blog. Read for yourself – I for myself am still happy to write […]
[…] p-values something else that is more descriptive. There’s been a fair bit of misunderstanding about them going on […]
[…] Até o momento desse post são 134 comentários no blog do Gelman! Vale a pena ler também o texto do (frequentista) Larry Wasserman e os comentários. […]
[…] Wasserman‘s recent post about misinterpretation of p-values is a good reminder about a fundamental distinction anyone […]
[…] 纽约时报犯错了?统计学家是不会放过你的!这里以及这里。(肖楠配图:如果说隐藏在幕后的统计学家还能为大众福祉主动发声,那些「只为自己带盐」的经济学家似乎就没这么走运了……) […]
[…] Para quem esqueceu ou não viu, aqui está o link para o ótimo post do Larry Wasserman sobre o P-Va… […]
[…] Wasserman: His perspective on statistics is different from mine (for example, he defines p(a|b) = p(a,b)/p(b), whereas I define p(a,b)=p(a|b)p(b)), but it’s good that he can get his […]