WHAT IS BAYESIAN/FREQUENTIST INFERENCE?
When I started this blog, I said I wouldn’t write about the Bayes versus Frequentist thing. I thought that was old news.
But many things have changed my mind. Nate Silver’s book, various comments on my blog, comments on other blogs, Sharon McGrayne’s book, etc have made it clear to me that there is still a lot of confusion about what Bayesian inference is and what Frequentist inference is.
I believe that many of the arguments about Bayes versus Frequentist are really about: what is the definition of Bayesian inference?
1. Some Obvious (and Not So Obvious) Statements
Before I go into detail, I’ll begin by making a series of statements.
Frequentist Inference is Great For Doing Frequentist Inference.
Bayesian Inference is Great For Doing Bayesian Inference.
Frequentist inference and Bayesian Inference are defined by their goals, not their methods.
A Frequentist analysis need not have good Bayesian properties.
A Bayesian analysis need not have good frequentist properties.
Bayesian Inference 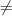
Bayes Theorem
Bayes Nets
Frequentist Inference is not superior to Bayesian Inference.
Bayesian Inference is not superior to Frequentist Inference.
Hammers are not superior to Screwdrivers.
Confidence Intervals Do Not Represent Degrees of Belief.
Posterior Intervals Do Not (In General) Have Frequency Coverage Properties.
Saying That Confidence Intervals Do Not Represent Degrees of Belief Is Not a Criticism of Frequentist Inference.
Saying That Posterior Intervals Do Not Have Frequency Coverage Properties Is Not a Criticism of Bayesian Inference.
Some Scientists Misinterpret Confidence Intervals as Degrees of Belief.
They Also Misinterpret Bayesian Intervals as Confidence Intervals.
Mindless Frequentist Statistical Analysis is Harmful to Science.
Mindless Bayesian Statistical Analysis is Harmful to Science.
2. The Definition of Bayesian and Frequentist Inference
Here are my definitions. You may have different definitions. But I am confident that my definitions correspond to the traditional definitions used in statistics for decades.
But first, I should say that Bayesian and Frequentist inference are defined by their goals not their methods.
The Goal of Frequentist Inference: Construct procedure with frequency guarantees. (For example, confidence intervals.)
The Goal of Bayesian Inference: Quantify and manipulate your degrees of beliefs. In other words, Bayesian inference is the Analysis of Beliefs.
(I think I got the phrase, “Analysis of Beliefs” from Michael Goldstein.)
My point is that “using Bayes theorem” is neither necessary or sufficient for defining Bayesian inference. A frequentist analysis could certainly include the use of Bayes’ theorem. And conversely, it is possible to do Bayesian inference without using Bayes’ theorem (as Michael Goldstein, for example, has shown). Let me summarize this point in a table:

Fairly soon I am going to post a review of Nate Silver’s new book. (Short review: great book. Buy it and read it.) As I will discuss in that review, Nate argues forcefully that Bayesian analysis is superior to Frequentist analysis. But then he spends most of the book assessing predictions by how good their frequency properties are. For example, he says that a weather forecaster is good if it rains 95 percent of the times he says there is a 95 percent chance of rain. In others, he loves to use Bayes’ theorem but his goals are overtly frequentist. I’ll say more about this in my review of his book. I use it here as an example of how one can be a user of Bayes theorem and still have frequentist goals.
3. Coverage
An example of a frequency guarantee is coverage. Let 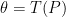

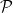
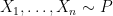
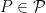


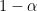
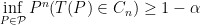
where 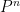

We say that
I think there would be much less disagreement and confusion if we used different symbols for frequency probabilities and degree-of-belief probabilities. For example, suppose we used 


Unfortunately, we use the same symbol

which, I think, just makes things confusing.
Of course, there are cases where Bayes and Frequentist methods agree, or at least, agree approximately. But that should not lull us into ignoring the conceptual differences.
4. Examples
Here are a couple of simple examples.
Example 1. Let 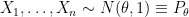


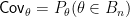



![{C_n=[\overline{X}_n - z_{\alpha/2}/\sqrt{n},\ \overline{X}_n + z_{\alpha/2}/\sqrt{n}]}](https://s0.wp.com/latex.php?latex=%7BC_n%3D%5B%5Coverline%7BX%7D_n+-+z_%7B%5Calpha%2F2%7D%2F%5Csqrt%7Bn%7D%2C%5C+%5Coverline%7BX%7D_n+%2B+z_%7B%5Calpha%2F2%7D%2F%5Csqrt%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Of course, the coverage of 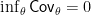


Example 2. A 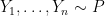

denote the order statistics (the ordered values). Choose 

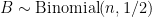
![{C_n = [Y_{(k+1)},Y_{(n-k)}]}](https://s0.wp.com/latex.php?latex=%7BC_n+%3D+%5BY_%7B%28k%2B1%29%7D%2CY_%7B%28n-k%29%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
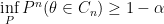
where the infimum is over all distributions

The plot shows the first 50 simulations. In the first simulation I picked some distribution 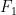

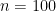
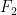
How would a Bayesian analyze this problem. The Bayesian analysis of this problem would start with a prior 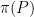

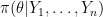

5. Grey Area
There is much grey area between the two definitions I gave. I suspect, for example, that Andrew Gelman would deny being bound by either of the definitions I gave. That’s fine. But I still think it is useful to have clear, if somewhat narrow, definitions to begin with.
6. Identity Statistics
One thing that has harmed statistics — and harmed science — is identity statistics. By this I mean that some people identify themselves as “Bayesians” or “Frequentists.” Once you attach a label to yourself, you have painted yourself in a corner.
When I was a student, I took a seminar course from Art Dempster. He was the one who suggested to me that it was silly to describe a person as being Bayesian of Frequentist. Instead, he suggested that we describe a particular data analysis as being Bayesian of Frequentist. But we shouldn’t label a person that way.
I think Art’s advice was very wise.
7. Failures of Assumptions
I have had several people make comments like: “95 percent intervals don’t contain the true value 95 percent of the time.” Here is what I think they mean. When we construct a confidence interval
Both Bayesian and Frequentist inference can fail to achieve their stated goals for a variety of reasons. Failures of assumptions are of great practical importance but they are not criticisms of the methods themselves.
Suppose you apply special relativity to predict the position of a satellite and your prediction is wrong because some of the assumptions you made don’t hold. That’s not a valid criticism of special relativity.
8. No True Value
Some people like to say that it is meaningless to discuss the “true value of a parameter.” No problem. We could conduct this entire conversation in terms of predicting observable random variables instead. This would not change my main points.
9. Conclusion
I’ll close by repeating what I wrote at the beginning: Frequentist inference is great for doing frequentist inference. Bayesian inference is great for doing Bayesian inference. They are both useful tools. The danger is confusing them.
10. Coming Soon On This Blog!
Future posts will include:
-A guest post by Ryan Tibshirani
-A guest post by Sivaraman Balikrishnan
-My review of Nate Silver’s book
-When Does the Bootstrap Work?
-Matrix-Fu, that deadly combination of Matrix Calculus and Kung-Fu.

78 Comments
I have two different definitions:
Bayesian: One who tries to make the best guess possible based on what is known, whether it be data from repeated trials or just simply other facts known to be true. There is no guarantee this guess will be correct or useful, but it is nevertheless the best that can be done with what is known. To do better requires that you know more.
Frequentist: One who tries to be wrong a fixed percentage of the time in future experiments that will never be performed, using assumptions about real long range frequencies from physical process that are usually wrong in the few instances in which they are checked.
I tried to to dispel the “experiments that will never be performed”
idea with the median example.
Anyway, we will just have to agree to disagree I guess.
By the way, how do you feel about this game theoretic approach:
and which I posted on here:
This approach makes no freqency assumptions at all
What are your thoughts?
Great post Larry. I hope it’ll dispel some of the confusion.
Also I can’t wait for the Matrix-Fu post. Sounds very intriguing!
thanks
#6 sounds a lot like Paul Graham’s “Keep Your Identity Small” essay. http://www.paulgraham.com/identity.html
Yes he nails it!
Thanks for the link.
> For example, he says that a weather forecaster is good if it rains 95 percent of the times he says there is a 95 percent chance of rain. In others, he loves to use Bayes’ theorem but his goals are overtly frequentist.
This is not coverage. It’s stronger than coverage, and it deserves its own name – does a name for this exist already?
A standard frequentist weather forecaster will do the following:
– “When the sky is planning to rain, my prediction will be for rain 95% of the time.”
– “When the sky is planning to be dry, my prediction will be for dry 95% of the time.”
– “Those last two statements covers all possible values of the true parameter, therefore my prediction will be correct 95% of the time.”
That’s coverage. But those three statements do *not* allow me to say:
– “When I predict rain, it will rain 95% of the time.”
– “When I predict dry, it will be dry 95% of the time.”
These last two statements involve conditioning on the data or on the predictions, and therefore they are not ‘coverage’.
I think this concept of conditional-on-prediction-correctness does deserve a name. Any thoughts on a name? It’s probably difficult/impossible, except maybe if you have a prior, to calculate this set of conditional probabilities in advance, but it’s still a desirable property and it can be measured later.
“I made a prediction every day for the last 10 years. Of the occasions where I predicted rain, I was vindicated 95% of the time. And this was t
rue for every other type of prediction I made.”
What do we call this concept?
Good point.
It is actually called calibration.
But I glossed over that for simplicity.
Perhaps I should not have done so.
Indeed, calibration != coverage, and while coverage may not be a goal for good Bayesian inference, calibration is. So it’s mot just a glossing over. Your implied criticism of Nate Silver is off point.
I don’t think so.
(There are lots of papers in the Bayesian literature arguing against calibration.)
Frequentist calibration is a frequentist
idea not a Bayesian idea.
But I’ll have to post about that in the future.
Also, there is more to my critique than just that one point.
Personally, I would be interested in a post on the connection (or lack thereof?) between calibration and frequentist techniques and/or Bayesian techniques.
Aaron, I had conflated calibration and confidence coverage until I read your comment. Thank you for pointing out the distinction!
The whole point of science is to turn our subjective beliefs into something as close as possible to reality. Right? Then the only reason I would care about frequency guarantees is because they inform me about how (and how much) I should change my mind. I prefer to take the more direct approach, and manipulate my beliefs directly.
I don’t deny that frequentist analysis is useful for having frequentist results. But what good are frequentist results? When I’m making a decision, why would I use anything but my subjective beliefs?
Well, my astronomer colleagues would be
disturbed if all the interval estimates
I have given them oer the years never trapped the true value.
As an astronomer, may I comment?
For many years, there were two schools of astronomers, one of which predicted that the Hubble parameter was about 50 (±10, say) and another that predicted that it was about 100 (±20, say). (Disclaimer: A faculty member at my institution led one of these schools).
Don’t take those error numbers too seriously, but they are probably in the ballpark of what these folks were claiming. At the time, both reductions used frequentist methods (Bayesian approaches were not much used if even known to most working astronomers at the time), so these intervals were claiming to be confidence intervals.
Note that at least one of these groups had to be wrong.
The Hubble telescope (which had a prime mission of settling this issue) produced a number which, ironically, was pretty close to the harmonic mean of 50 and 100, with a much smaller error. WikiPedia reports that the most recent value is 74.3 ± 2.1 (I know, excessive precision here.) I suspect that this was also gotten using frequentist methods, but I do not know this.
The point is that it is probable that neither of the two older groups produced CIs that contained the “true” value. Each of these groups produced many such intervals over a period that was several decades long.
Bill
Correct me if I am wrong but aren’t these usually Bayes’ intervals?
Most of the analyses I have seen for cosmological parameters involve multiplying the
(somewhat complicated) likelihood by a prior
(usually flat over a rectangular region) and running an MCMC.
Then one gets marginal intervals for H0, Lambda, etc
Perhaps I have seen a biased sample of the papers??
Larry
Err… I didn’t quite catch what you specifically disagreed with. Or how my way of thinking could lead to the disaster you described. Could you tell me, please?
Perhaps I just misunderstood your comment.
Larry,
The two schools (Allan Sandage and Gerard de Vaucouleurs) were using standard frequentist statistics. I know this to be the case with my colleague Gérard, and it is almost certainly the case with Allan. Astronomers just weren’t using Bayesian methods in those days, so I don’t think that you can interpret what they were doing as Bayes’ intervals.
http://en.wikipedia.org/wiki/Allan_Sandage
http://en.wikipedia.org/wiki/G%C3%A9rard_de_Vaucouleurs
The real reason that they differed so much doesn’t have anything to do with statistics, it is just that they both relied on different kinds of data to come to their conclusions. So it was bias (and the difficulty of doing it in those days). It may well be that their CIs were actual CIs with regard to the data that they were using, but it’s clear that as far as capturing the actual value of the Hubble parameter, at least one of them had to be wrong (and as it turned out, probably both of them were)..
I was interested to learn that Allan actually hit the right result in a paper in 1958, but then went for the lower (50) result and AFAIK stuck to that for the rest of his (pre-Hubble Telescope) career.
Thanks Bill
I guess I was thinking about recent estimates of
cosmological parameters where MCMC seems popular
Larry
Larry,
Thinking more on this, it is more a matter of model error than what I said, “bias”, in each of these astronomers’ results. Neither astronomer knew enough about the processes that were producing the data that they were using.
Terrific post. A couple of queries;
* What’s $n$ in Example 1?
* Example 2; I see the point about non-identical replications. But, as per Cox 1958, in frequentist inference we have to think hard about which replicated experiments are relevant to the inference we want to draw. Most of the time this is going to be replicates of the experiment we actually did, perhaps conditioned on some property that it had. Are you going to post about conditioning?
n = 20
Yes. Conditioning would make an interesting post.
I’ll add it to the list
(assuming I can think of something interesting to say about it)
No doubt you have something interesting to say on conditioning, as in your 2000 paper with Jamie Robins. I’d be very interested in your ideas (which may or may not include conditioning arguments) about how to get from mindless frequentist inference, which is trivially easy, to mindful inference.
Thanks for the post! The point that one aims at different goals in developing a technique from within a Bayesian framework than when one does so from within a frequentist framework is important. How far does it go in helping to resolve disputes about which kind of technique is more appropriate for a given application? My impression is that an applied statistician is usually aiming at a goal (such as some kind of predictive accuracy) that is not straightforwardly connected to either belief analysis nor a frequency guarantee, so that consulting his or her goals doesn’t settle the issue one way or the other. Does that seem right to you?
Good point.
The goals in a real application are
diverse and sometimes hard to pin down.
My precise division of goals is useful for
conceptual purposes but for a given application
things will rarely be so clear.
As a practitioner I found this blog really useful. You’re right it’s often hard to come to a clear decision on whether your goals are explicitly frequentist or Bayesian in a practical situation. Some even-handed advice from the pros on this topic would be really interesting, even if the advice comes with a lot of hedges and qualifications 🙂
Personally speaking I tend to ask myself a question familiar to computer scientists looking at algorithmic complexity: do I care more about the bounding performance in the worst case, or about performance in the average case? (presuming I have useful prior information which I can use to quantify what I mean by ‘average’).
Usually the answer is “I care about both”. Which might explain why it seems popular e.g. to use Bayesian methods to derive models and frequentist methods to analyse them.
The sooner we can get over this silly sort of ideological purity where both sides of the “debate” want to take credit for these kinds of hybrid methods, the sooner we can get on with using them to get stuff done.
Hallo I read your analysis, and found it pretty convincing, I guess my main Problem with the Bayesian world is that there is not a clear definition of what is right or wrong and people wanting to prove that fall back all of a sudden in the frequency world backtesting their “predictions”.
Very enlightening post, thanks.
It might be because I have been surrounded by frequentists statistics way more than Bayesian statistics but I have a hard time expliciting the information contained in a Bayesian posterior interval. Namely, a 95% confidence interval means that, if you were to use this estimator on data following your assumptions, the interval would contain the true value of the parameter at least 95% of the time.
What can be said for a Bayesian posterior interval ? What does it mean to say “95% of my posterior mass lies in this interval”? Is there a way of using this information concretely?
Like you, my question is in no way a criticism of Bayesian statistics but rather the expression of an inability to fully apprehend the kind of questions they answer to.
Many thanks.
The DeFinetti interpretation would be:
you are personally willing to bet at 19:1
odds on whether the parameter fals in in the interval.
I should have mentioned this in the post.
LW
As written before in reply to the last posting on this blog, there is no such thing as a true parameter for de Finetti (unless it is observable).
Yes but as I say in section 8 of the original post,
we can replace all my statements about parameters
with statements about observables
Aye. But see what I wrote further down. People do believe that Bayesians talk about true paremeters if they sound as if they do, and I think that this leads to confusion.
Nicolas:
You might find this paper provides some of the concreteness (in repeated applications) you might be hoping for
Paul Gustafson and Sander Greenland http://arxiv.org/pdf/1010.0306.pdf
(Really just Larry’s graph in Example 1, but extended and fleshed out for even omnipotent priors.)
Thank you both or your reply, I will read the aXiv paper carefully.
Very nice way to re-define the debate!
I did often notice that it was awkward for those who labeled themselves as Bayesians but agreed that repeated performance of statistical procedures over applications was critical – to discuss/write up this candidly.
Perhaps the best exception was Don Berry at MD Anderson who wrote that regulatory agencies had to be concerned with type one and two error rates and that this had to be determined when using Bayesian methods that offered convenience and often even better type one and two error rates.
Or Scott Emerson at University of Washington who wrote Frequentist Evaluation of Group Sequential Clinical Trial Designs and Bayesian Evaluation of Group Sequential Clinical Trial Designs pointing out the difference as mainly convenience [if type one and two error rates were the primary concern]. He also makes really nice type and two error plots over nuisance parameters showing how varied they can be.
And thanks for the link to Michael Goldstein – I’ll be interested in seeing how it relates to Mike Evan’s Relative Surprise Inference http://www.utstat.utoronto.ca/mikevans/research.html
Thanks
In example 1, if the Bayesian is correct that theta is being drawn from N(0,1), then won’t his 95% posterior interval contain theta 95% of the time? (Of course, if theta is not drawn from this distribution, then his 95% posterior interval will contain theta some other percentage of the time. In particular, if the value of theta is fixed, then your chart shows these coverage probabilities as a function of that fixed theta.) … Is this covered in the topic of calibration?
Yes that is right.
The average coverage (averaged with respect to
the Bayesian’s prior) is 1-alpha.
You can then think of the frequentist coverage as a sort of
robust Bayesian idea; the average coverage is at least 1-alpha
when average over any prior.
As a matter of fact, this might be the most important practical difference to take into account when deciding which inference to follow: one is to adopt a uniform/worst-case scenario approach; the other, to act as-if problems of “the same kind” as the one at hand have these odds of having generated the data. I’d guess many Bayesian practitioners are not concerned at all about the adequacy of limiting frequencies as a suitable abstraction (and personally I’d have a hard time finding someone disagreeing that calibration is desirable). On the other hand, many would be much less willing to go for a worst-case scenario protection (hence, coverage seems to be far less important in this setup).
While I share many of the sentiments expressed in your post, I would urge moving away from the recommended quick sum-up of “the goal” of frequentist inference: “Construct procedures with frequency guarantees”. I will write a post on this later on, but just want to make this one point here. Firstly, what are frequentist guarantees? If by this you mean (as I think you do) that the direct aim is to have tools with have “good long run properties”, and rarely err in some long run series of applications, then I think it is misleading. In the context of scientific inference or learning, such a long-run goal, while necessary is not at all sufficient; moreover, I claim, that satisfying this goal is actually just a byproduct of deeper inferential goals. Bayesian methods may have good long-run properties, and so it would then seem there is no difference between them, or that “unification” is at hand by paying obeisance to some good performance properties in repeating a Bayesian method over and over again (as some of your commentators suggest). Let Bayesians have their one updating rule. If there is one thing Fisher, Neyman, Pearson and all the other “frequentist” founders fought was the very idea that there is a single “rational” or “best” account or rule that is to be obeyed: they offered a hodge-podge with clear-cut properties, which may be relevant to the user at various stages with various goals. Their methods do embody some fundamental principles such as: if a procedure had very little capability of finding a flaw in a claim H, then finding no flaw is poor grounds for inferring H. I return to these points on errorstatistics.com.
I agree that long run guarantees are not the only goal
of frequentist inference. But I do think they are the main goal.
I deny this. In the context of scientific inference or learning, I argue, satisfying the low-long run error goal is actually just a byproduct of deeper inferential or learning goals. By supposing it is the top goal, one invites all manner of howlers that no frequentist would promote: e.g., insisting that one’s highly imprecise measurement was actually rather good because most of the time a more precise instrument would have been used. That is why Pearson bemoaned “the absurd extent to which people focused” on behavioristic goals, and why so many classic fallacies persist. Of course it is possible that there is confusion over the meaning of the goal of low long-run error….and that you are taking what is only a consequence of a different goal (that concerns the inference at hand) as if that were the actual goal and the intended criteria for judging an inference.
Interesting.
I’m not sure how to interpret, say, confidence
intervals without appealing to their long run properties
Sure you do. See for example http://errorstatistics.com/2012/10/20/mayo-section-5-statsci-and-philsci-part-2/
It is what arises from the dual significance test. Why is there evidence that theta exceeds the lower .99 CI bound? Because were it not, then with high probability we would have observed a larger difference than we did.
Oh, but there *is* one true updating rule: it’s the one you should use to choose the method to analyse your data. Not believing that is falling prey to relativism.
For instance, let’s imagine that we can use either p-values, or log-odds, and that each is better suited to a range of applications than the other. Even if it doesn’t feel like it, your brain does use a single algorithm to choose the most appropriate method. Let us just pray it’s the right algorithm.
If we accept that, Bayesians further claim that they have found the algorithm (too bad it’s often computationally intractable). I can imagine that they didn’t. But I can’t fathom the possibility that there is *no* such algorithm.
“Even if it doesn’t feel like it, your brain does use a single algorithm to choose the most appropriate method.” Sounds like religious belief to me (and you continue with a prayer in the very next sentence;-)… do you have any empirical evidence backing this up? Or is this a definitory sentence of the type “whatever your brain does I’ll call ‘a single algorithm'”, in which case it doesn’t mean much?
Honestly I’d be much happier with relativism than with this kind of dogma…
We have pretty good empirical evidence today that our universe runs on math. The supernatural, in the sense of ontologically basic mental entities (such as souls that survive the body, or God), have a ridiculously low chance of existing. Starting from that, it’s obvious that physical processes in general, including brains, form some kind of algorithm. The catch is, we don’t have direct access to our own decision-making algorithm. There are experiments about that, where a machine can predict your decision *seconds* before you thought you made it. (Electrodes to your head, 2 buttons to push, you choose which one.)
Finally, I understand you sneer at dogma (you should), but don’t forget that some facts are universally accepted as truth: 2+2=4 (there are laws of thought), and when you drop an apple, it falls (there are laws of physics). Think twice before saying that something isn’t bound by either the laws of physics, or the laws of thought. They are pretty widely applicable.
Loop Vaillant: The claims you made before were *much* stronger than that a dropped apple falls or 2+2=4.
By the way, what exactly does the claim “our universe runs on math” mean and how does evidence in its favour look like? And how is this related to the “single algorithm” claim you made before? (You’re “Loup”, as I see, sorry for the typo before.)
@Christian: Long route: read the sequences on LessWrong, they’re about a million words. (Seriously, I highly recommend “Highly advanced epistemology 101 for Beginners”. It’s recent, well written, accessible, and relatively short). Now to make it a bit less steep:
My claim doesn’t stop at «there are laws of physics», and «there are laws of thought». I claim that the laws of physics are universal, and so are the laws of thought. In particular, there are laws for assessing of the state of the universe, and those are pretty much nailed down. If you have a prior belief, and you then gather information, the posterior belief you ought to have is fixed. One should change one’s mind according to the amount of evidence. No less, and no more. Well, that’s the ideal version anyway. In practice, we often don’t have the computational power required to do the exact calculations.
I started with “2+2=4” to illustrate that once you state a number of axioms (like Peano’s arithmetics), theorems like “2+2=4” are valid or not (or undecidable, but that is also in itself a definite result). You can’t escape “2+2=4” from Peano’s axioms. In the same way, you can’t escape Probability Theory from a number of axioms whose negation would be universally considered as nuts.
“Our universe runs on math” means that the universe can be described with math. I further claim that these maths are likely very simple. (Not “2+2=4” simple, but not as complicated as the high-level interactions between humans.) At the bottom, there’s only the wavefunction (or so we currently think). So, we humans are basically factors of the wafefunction. As such, we can be described mathematically, which makes us “algorithms” in a trivial sense. We’re not *simple* algorithms by a long shot, however.
As for the actual evidence that the universe is math, it basically starts with Newton. We did some corrections since (Relativity, QM…), and I expect we will do more (our “laws” of physics aren’t complete yet), but one thing has never changed: the assumption that it’s math, we just have to find it. So far, this assumption has worked pretty well (see our whole civilization), so I’d say it’s good evidence. Better evidence than any theory based on the assumption that some things are inherently mysterious. It’s not like churches made huge technological leaps because of their knowledge in theology (and they had incentives: who wouldn’t want to demonstrate the mighty power on one’s God?).
Loup: Interesting discussion, similar in some ways to an argument Peirce made that could be caricatured as – “If a university did not run on math, it would not contain cognisant life forms and I do not doubt that I exist in this universe and can be cognisant.”
Unfortunately Peirce’s actual arguments are notoriously difficult to grasp and get actually what _he meant_ in the context of his vast writings and wide ranging concerns.
However, for those who are interested this might be the best start: Paul Forster, Peirce and the Threat of Nominalism, Cambridge University Press, 2011, which is reviewed here http://ndpr.nd.edu/news/29410-peirce-and-the-threat-of-nominalism/
Loup: This makes good reading but still I see much more “I claim…” in your text than “the evidence is…”. How does successful application of mathematics in physics tell me anything about the claim that “If you have a prior belief, and you then gather information, the posterior belief you ought to have is fixed”? By the way, “success” is not well defined and the very concept of “success” looks very relative to what human beings want.
Christian: it tells you very little. The later does not follow from the former, but from probability theory, which lies on a very small set of axioms. See the first two chapters of “Probability Theory: the Logic of Science” for a thorough explanation. As for where the small set of axioms come from… for now I just take them for granted. I think however that Bayesian inference demonstrated its superiority in some concrete cases, like finding pieces of an airliner lying in the ocean. Typically cases where clear evidence was scarce.
What follows from “scientist are impressive (moonwalking (Apollo), long range telepathy (phone)…)” is “Scientist are right” (It’s not logical implication, merely Bayesian evidence). On core thing about science is that in the laboratory, everything is supposed to have an explanation. Except maybe the very core laws of physics, which as we know them are math. And the existence of these assumptions, and the fact they lead to impressive feats, while religious beliefs do not, are indirect evidence that the universe *is* mathy. If it were strong evidence for Bayesian inference, we would have adopted it, or science wouldn’t have taken off.
It seems you’re assuming Bayesian reasoning in order to justify it…
My first paragraph assumes a few axioms to justify Bayesian inference. I won’t comment on the details because I do not fully understand them yet. My second paragraph loosely uses Bayesian reasoning to *not* justify it: I was saying that history showed us that Bayesianism wasn’t clearly needed.
Really, my argument ultimately hinges on some common sense axioms, though I’m sure that over time, empirical evidence will eventually make Bayesian inference look good even in the light of Frequentist criteria. (Which by the way was probably one goal of Nate Silver’s book: “hey, look, my methods are better than yours, even according to your criteria!” Of course he would analyze the frequency properties of his Bayesian predictions. Calling him out on that is unreasonable.)
Re your point 7: whatever the cause of the problems (and I agree, failed assumptions are probably the biggest culprit), it would be nice if we achieved calibration in our confidence reporting. E.g., what if we required all confidence intervals reported in (say) JAMA and NEJM to carry a footnote: “of the 95% confidence intervals reported in the last five years in this publication, 47% have contained the true value of the parameter.” I’ll bet it would change the way people read the articles…
That wold be great!
(albeit hard to implement)
Yes, well, implementation is left as an exercise for the reader…
“E.g., what if we required all confidence intervals reported in (say) JAMA and NEJM to carry a footnote: “of the 95% confidence intervals reported in the last five years in this publication, 47% have contained the true value of the parameter.” I’ll bet it would change the way people read the articles…”
Bruno de Finetti would be pleased with your bet.
Geoff: Very hard to say how that would change the people (clinical researchers?) who read JAMA and NEJM.
They have been hit over the head now for 20+ years about p_value censorship (Larry even gave a talk on this with another student back in grad school at U of T). They must realize that ruins coverage (or at least the statisticians who work with surely will have pointed that out).
But it is a very general problem – we don’t know what researchers (including statisticians) in the field (and academia)don’t know.
We can get a biased sense of this from comments posted on blogs – here that some statisticians don’t fully understand interval coverage form both Bayesian and Frequentist perspectives. I only knew that – “The average coverage (averaged with respect to the Bayesian’s prior) is 1-alpha” because it was a result given in a technical paper I once read. It is nice fleshed out in the Gustafson and Greenland paper I cited above – but how many statisticians know that material. (And I strive to write my comments so its hard for people to discern what I don’t know).
We should do regular confidential surveys to discover this, but these will be hard to implement.
And it would be impossible to get the needed “remedial” materials into journals!
I didn’t mean to single out medicine — that was just an example of a field where it would be important to get calibration right. (It’s not just clinical researchers who read JAMA and NEJM, although these are one important class of readers; medical practitioners read these journals as well, so the published claims directly affect patient care.) My belief in any case is that experienced practitioners in any quantitative field do know that 95% confidence intervals aren’t. But that leaves a lot of ground for less-experienced readers to misunderstand, and even for experienced ones, there’s a strong temptation to take a stated claim at face value instead of correcting for miscalibration.
In the case of point estimation, I interpret “being Bayesian” as wanting good *average case risk* where the average means the expectation under the prior. On the other hand, frequentists want good *worst case* risk i.e., minimaxity.
That’s something I don’t understand: what do “worst case” and “average case” have to do with epistemology? Can’t we start from the whole probability distribution, and let the decision makers put the thresholds where they want?
Unless you are objecting to http://en.wikipedia.org/wiki/Fallibilism (and not claiming everything is relative so there is no sense of less wrong representations of reality), you actually start with a fallible prior distribution that is fallibly restricted/reweighted/conditioned on data (fallible because the correct data model is never known).
The “average case” with respect to the prior assumed is a silly start, but it is a start. Ideally that average is calculated with respect to priors and data models that remain sensible.
Faillibilism is at the core of Bayesian philosophy (except maybe about Bayesian itself), so…
The perfect prior is the one that puts all probability mass on truth to begin with. Of course, do not try this at home. But we can’t escape starting from a prior. If it’s a problem, just provide odds ratios, and combine them with the relevant priors (maximal uncertainty, your own prior, and the prior of your policy-maker, for instance). That would likely be much more informative than an analysis that doesn’t explicitly state its assumptions.
Hi Larry!
I think this is a good provocation, but I also think it missed the main point!
I know you looked for simplicity, but I don’t think your definitions would clarify the debate, because I think they did not capture the essential difference between the two methods of statistical inference. And that is what we look for in a definition!
First, you did not define the “inference” itself in the frequentis inference! To infer something is to use evidence and logic to reach a conclusion. So, frequentist inference could not be defined as “construct procedures with frequency guarantees”… this could surely be the goal of a theoretical frequentist statistician, that is, to provide the scientific comunity what he thinks are good technical procedures. But this surely is not the goal of an inference!
So, I would claim that both Frequentist Inference and Bayesian Inference have the same goal – which is the goal of any kind of inference!
Their goal is to answer the folowing question:
– When is data X, generated by the procedure T, good evidence for the claim H?
Frequentist philosophy approaches this question in a different manner than bayesian philosophy. And both could rely on the frequencies properties of the methods used to reach a conclusion! So your definition would not be a good way to distinguish very different kinds of bayesian and frequentistsinferences.
Best,
Carlos
I like this posting but I think that there is one issue that deserves more focus.
I know I’m boring you with insisting on “there’s no true parameter for de Finetti”, but I think that the meaning of the idea of a “true parameter” is central for frequentism. Even if somebody does Bayesian inference, as long as there still is the idea that there is a true sampling model governed by some unobservable parameter is essentially frequentist as far as I see it.
Bayesian analysis is often done using the standard setup prior(parameter)*sampling_distribution(.|parameter), but the interpretation of probability implied varies a lot. Some valid options are, as far as I see it,
1) the parameter is only an artificial mathematical device in order to set up predictive distributions for future observation (de Finetti),
2) *both* prior and sampling distribution have a physical/frequentist/propensity meaning, as can be justified sometimes (e.g. in the physical experiment described in Bayes’s original paper) but not in the vast majority of applications,
3) all probabilities (including the resulting predictive ones) are not intended to have an operational/physical meaning but are plausibilities resulting from a logical analysis of existing knowledge (Jeffreys/Jaynes).
However, it seems to me that very often Bayesian analysis is interpreted as if the sampling distribution has a physical meaning, there is a true parameter, and the posterior tells us something about what we know about it given the data and the prior information. But I don’t think that any justification of probability calculus licenses a mixed use of the sampling distribution as something “out there in the real world” whereas the prior formalises a belief about something that is not in any sense “distributed” in nature. Either both should be frequentist and about “data generating processes in the real world”, or both should be logical and about beliefs.
When interpreting results very carefully, Jaynes’ approach accomodates belief about both “true (unobservable) states of reality” and what will be observed in the future, but even there it is not really taken into account on how essentially different considerations usually are, in practice, that are required for setting up the parameter prior and the sampling distribution, and Jaynes himself emphasizes that the sampling model is about logical ideas involving *treating* some things as symmetric/exchangeable and not about a process going on in the real world.
I see your point now Christian.
There is indeed a lot of mixing of ideas that goes on.
Christian: Thanks for clarifying.
Reminds me of David J. Spiegelhalter’s distinctions of epistemological versus aleatory uncertainty.
Not sure its exactly the same as you are raising here.
I would want to avoid confusing the representation (model) with what that representation is trying to represent (in some sense for some purpose).
And mixing distributions in Bayesian hierarchical models do seem to really mix it all up.
Keith: The distinction between epistemological and aleatory uncertainty is closely related and certainly useful. My point is that I think it is problematic to mix both of them up in the same reasoning, as you apparently realised already. Bayesians seem to do this a lot.
When I toss a coin, it will either come up heads or tails.
If I could know all the initial conditions right before the toss, I would know for sure what the result would be.
So if I can’t predict exactly what the result will be, that’s an epistemological uncertainty, even in an event as simple as a coin toss.
Following Kolmogorov, define S as the set of the complex conditions of the coin toss. When I say that the frequentist probability of coming up heads is 0.5, what I’m saying is that the limiting frequency of the event “heads” under these S conditions is 50%. But the uncertainty here is still epistemological, for if I knew exactly what subset S’ of S each toss came from, the event would not be random for me. So, randomness, even in the frequentist definition provided by Kolmogorov, is not absolute.
The “objectivity” in the frequentist probability definition is only related to the fact that the distribution of “heads” under complex conditions S woud be b(0.5), even if you could tell each result.
But the uncertainty (that is, the fact that you can’t exactly predict each toss) is essentialy epistemological.
Carlos: The word “objectivity” has many meanings (and by the way I haven’t used it in this discussion up to now). I agree that frequentist distributions depend on how you look at the problem. According to my understanding, the whole business of mathematical modelling is about ways to look at real problems in a certain hopefully helpful way. I wrote about this, see http://link.springer.com/article/10.1007%2Fs10699-009-9167-x?LI=true
Assuming a frequentist model means to look at a problem in a certain way and for example to treat something as “repetition” that is not really exactly a repetition. A valid use of the word “objective” in this respect is to say that the frequentist mindset implies that we are modelling something that goes on objectively in reality (as opposed to beliefs), although I agree that the human activity of modelling it isn’t really objective.
Still I have a pretty good idea about what is implied if I do this. Same for some ways of applying Bayesian statistics, but not for some others, see above.
I will read your paper it looks interesting.
What I wanted to dispute was the notion that we couldn’t mix “epistemological” probabilities with “physical” probabilities, because even in the frequentist notion of probability, the uncertainty is epistemological.
Givern the event X under complex conditions S, If I know exactly the subset S’ of S that took place, to me, P(X|S’) is either 0 or 1. On the other hand, If you cannot distinguish S’ from S, your best guess is P(X|S)=fraction. And even though I know that P(X|S’) is either 0 or 1, that does not change the distribution of X given S. So, there’s no need to interpret the probabilty as an instrinsic property of the phenomena, even in the frequentist notion.
Carlos: The very core or frequentism (hence its name) is to associate probabilities with limits of relative frequencies, and this justifies the probability axioms in a frequentist way. In order to use frequentist probability, at least an idea of a repeatable experiment/observational condition is needed. This may not directly disagree with what you’re saying. But my point above was that if you use the symbol P for a probability measure, you should at least within a certain application use it consistently, and this means that you may associate it with betting rates, frequency limits, or Jaynes-type plausibilities, but please just one of them at a time. At least if you don’t want to confuse me 😉
Sorry for commenting on an older post — but I feel compelled.
I think you’re doing something unfair and unrealistic: trying to define Bayesians into an unhappy corner. It won’t work.
In fact, to me it seems much like inventing a very narrow definition of, say, “Jazz,” one that includes Duke and Ella and not much else, and then telling a bunch of modern Jazz musicians they aren’t really doing what they think they are. You might amuse them, but they won’t stop calling what they do Jazz.
Bayesian methods, and thus Bayesians, have a tradition and a culture. They are not narrow. They do not fit in a box.
The “subjective probability” thing — look, it is very important to those of a philosophical bent. Fine. It is also important to the AI crowd, since they are trying to invent optimal reasoners, and thus any scheme to optimize subjective beliefs will interest them.
But to say that should exhaust their goals is very limiting.
Of course Bayesians care about frequency guarantees, when they can get them. The AI guy designing a fire fighting robot wants it to work. He wants it to succeed, and he wants that often.
Which, if you think about it, is kind of the point of optimal subjective beliefs. We want them to be (to some degree) true. If they are true, they should work in the world, and do so frequently.
ok
that’s a fair point
LW
12 Trackbacks
[…] What Is Bayesian/Frequentist Inference? – Normal Deviate […]
[…] WHAT IS BAYESIAN/FREQUENTIST INFERENCE? « Normal Deviate. […]
[…] A found a good article discussing the difference between Frequentists and Bayesian Inference. […]
[…] Este post do Normal Deviate mostra de forma quase que absoluta: […]
[…] Wasserman takes on the Bayesian/Frequentist […]
[…] Deviate has a short and provocative post on the differences between frequentist and Bayesian statistics. I basically agree with what he has […]
[…] fan of Bayesian inference, which is fine. Unfortunately, he falls into that category I referred to a few posts ago. He confuses “Bayesian inference” with “using Bayes’ theorem.” His […]
[…] This is of course not a new idea. The aforementioned Normal Deviate has had several great posts on common myths about Bayesian vs. Frequentist. And I had a post on statistical machismo in this blog just under a year ago which had a record […]
[…] the two, or which approach is more appealing and why. Larry Wasserman already gave an excellent review. In practice, I am not sure there is big difference. I consider Bootstrap to be the Frequenist […]
[…] algorithm implements Bayesian reasoning. It doesn’t, it just involves Bayes’ theorem. Using Bayes’ theorem is not (necessarily) Bayesian. For it to be Bayesian, there should be some kind of probability distribution defined on the […]
[…] “Frequentist Inference is not superior to Bayesian Inference. […]
[…] “Frequentist Inference is not superior to Bayesian Inference. […]