Happy Independence Day and Happy Higgs Day.
Frequentist statistics treats observations as random and parameters as fixed. Bayesian statistics treats everything as probabilistic. But there is an approach to statistics that removes probability completely. This is the theory of individual sequences which is a subset of online (sequential) learning. You can think of this theory of taking the idea of distribution free inference to an extreme. The description I’ll give is basically from the book:
Nicolò Cesa-Bianchi and Gábor Lugosi, (2006). Prediction, Learning, and Games
and the article:
Cesa-Bianchi and Lugosi, (1999). On Prediction of Individual Sequences. The Annals of Statistics, 27, 1865-1895.
1. Individual Sequences
Let 



denote the first
The data sequence is not assumed to be random. It is just a sequence of numbers. In fact, we even allow for the possibility that the sequence is generated by an adversary who is trying to screw up our predictions.
We also have a set of algorithms (or predictors) 
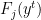


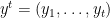
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
- You see
and
where
is the prediction for
from algorithm
- You make a prediction
.
-
- You suffer loss
.
We will focus on the loss 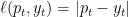


where 
You suffer average cumulative loss

Your regret is your cumulative loss compared to the loss of the best prediction algorithm:

Since we are not using probability, how do we deal with the fact that the regret depends on the particular sequence? The answer is: we take the worst case over all sequences. We define the maximum regret
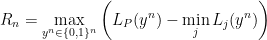
where the maximum is over all possible binary sequence of length

This is the smallest possible maximum regret over all predictors 
It has been shown that

In fact, this bound is essentially tight.
Is there an algorithm
The algorithm is simple: we simply take a weighted average of the predictions from 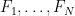
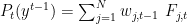
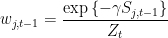
and 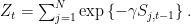
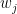
Theorem 1 Let
. Then

The proof (again I refer you to Cesa-Bianchi and Lugosi 1999) is quite simple and, interestingly, it is very probabilistic. That is, even though the problem has no probability in it, the proof techniques are probabilistic.
The result is for a specific time 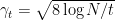
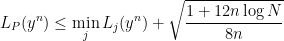
for all 
Now suppose that 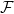
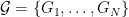



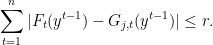
Let 
Theorem 2 (Cesa-Bianchi and Lugosi) The minimax regret satisfies
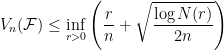
Cesa-Bianchi and Lugosi then construct a predictor that nearly achieves the bound of the form

where 
2. Back To Probability
What if we have batch data (as opposed to sequential data) and that we make the usual i.i.d stochastic assumption. Can we still use these online ideas? (The reference for this section is: Cesa-Bianchi, Conconi and Gentile 2004).
Using batchification it is possible to use online learning for non-online learning. For example, suppose we are given data: 





To choose a final classifier we either use 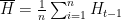
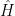
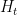

Let 
Theorem 3 If
is convex:
For any


This means that we get nice performance bounds in the traditional probabilistic sense from online methods.
3. Summary
Individual sequence prediction and, more generally, online prediction methods, are interesting because they require no stochastic assumptions. This is very satisfying because the usual assumption that the data are drawn from a distribution (or, if you are a Bayesian, the assumption of exchangeability) is a fiction. Data are just numbers. Except in special situations, assuming that the data are random is something we do by reflex but it is often not justifiable.
Most research in this area is done by people in machine learning. Statistics is being left behind. There are exceptions of course; some names that come to mind are Gabor Lugosi, Andrew Nobel, Peter Grunwald, Andrew Barron, Sasha Rakhlin, and others I am forgetting. Nonetheless, I think that most statisticians are unaware of this area. We need to be more involved in it.
4. References
Nicolò Cesa-Bianchi and Gábor Lugosi (2006). Prediction, Learning, and Games.
Cesa-Bianchi, N. and Conconi, A. and Gentile, C. (2004). On the generalization ability of on-line learning algorithms. IEEE Transactions on Information Theory, 50, 2050–2057.
Cesa-Bianchi and Lugosi, (1999). On Prediction of Individual Sequences. The Annals of Statistics, 27, 1865-1895.
Littlestone, N. and Warmuth, M. (1994). The weighted majority algorithm. Inform. and Computing. 108, 212-261.
Vovk, V. (1990). Aggregating strategies. Proc. Third Workshop on Computational Learning Theory, 371–383.
I recommend these lecture notes by Sasha Rakhlin and Karthik Sridharan.
—Larry Wasserman

26 Comments
Nice post. May I suggest some small corrections about the index $i$?
– All \sum_{i=1}^n should be replaced by \sum_{t=1}^n
– Section 2: data $(Z_1,…,X_n)$ where $Z_i=(X_i,Y_i)$ => corrected as (Z_1,…,Z_n)$ where $Z_t=(X_t,Y_t)$
– And the formula to calculate $\hat{H}$ by choosing $H_t$ to minimize…
Best,
Hung Ngo
Thanks
–LW
Larry: I’m wondering if you can give an example of one of these methods–ideally at a baby level–along with the specific performance bounds, and how to interpret/use them. I have studied parts of the lecture notes to which you link, and a few other resources (since the recent CMU conference) but my understanding is mostly hazy. Thanks much.
A toy example is predicting the weather: Rain, No Rain, No Rain, Rain, etc.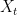 as well as
as well as 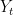 . (I discussed only
. (I discussed only 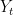 for simplicity.)
for simplicity.)
But the best examples require including some
Then, this applies to any sequential classification problem. Think of predicting a stock or think of Google trying to predict if you will click on an ad.
— LW
Well I trade on the stock market fairly regularly, so how might I apply these ideas? (Of course I want to know how much up, how much down).
Nice post. This gives more details on one of the topics discussed on your RMM paper ‘Low Assumptions, High Dimensions’.
However, I still have some few general questions that I think would be great if you could answer:
a) does the predictors $F_1, \ldots, F_N$ need to be independent? If not, how to interpret these result in case they are identical?
b) the first upper bound on $V_n$ is minimized when $N=1$; how should I interpret this?
c) how all of this compare to empirical process or nonparmetrics that is already done by statisticians?
Thank you.
By independent I guess you mean, not identical?
In fact if F1 and F2 are copies of each other you can do better by taking that into account.
Using coverings, as I mentioned in the post does, in fact, take this into account.
(The covering would never contain two experts that are copies.)
You get smaller risk for small N because you are trying to track fewer experts.
The theory does use similar tools as nonparametric inference (for example empirical processes).
But it is hard to compare them since the goals are a little different; it is very sequential.
If you type “online learning nonparametric” in Google scholar you’ll find lots of interesting connections.
I hope that helps.
—LW
Thanks. It helps a lot. The answer to my second question, together with your answer to Christian Hennig are very informative. But now I’m confused because before applying this theory I have to have the predicotrs (or experts or algorithms), right? The confusion is: should I care about tracking experts or about building better experts (to me, this last on seems to be the main objective of statisticians)? Could you please clarify this?
Thanks againg.
You need to do both: construct a good set of experts ad track the best expert.
It is really the same as traditional statistics. You need to construct a good model
and then find a good estimator for that model.
—LW
I wonder whether I miss something important here… I don’t see any assumption that makes sure that y_{t+1} has anything to do with y_1,…,y_t. So how can y_1,…,y_t give any information about y_{t+1}? In other words, how is under the given (non-)assumptions predicting y_{t+1} given y_1,…,y_t any easier than predicting y_1 without having any observations before?
If I haven’t missed any such assumption, it seems that the theory refers to a situation in which n observations are already there, and then an optimal rule is found out that would have been good had we used it up to step n (within-sample error). But because n steps are already there, how does this help us with predicting y_{n+1}, which can be anything totally regardless of what y_1,…,y_n had been and what had been optimal within-sample?
Christian
That’s the amazing thing about all this. It seems impossible doesn’t it?
But remember, we are just minimizing regret. It is all relative to a given set of algorithms.
I had the same reaction as you when I first encountered this area.
Keep in mind that even if we track the best expert, all the experts might be bad.
—LW
Well, the theorems don’t seem impossible, but I’m not sure whether what the theorems say is of any use for actual prediction. In reality most sequences have some structure and I believe that nature doesn’t try on purpose to be as evil with us as it can, so using the structure (and be it in a slightly wrong way by getting model assumptions wrong) should usually be much better than the minimax.
Larry, thanks for the post! The question of “sequences with some structure” often comes up, and there are ways of adding this information (just added lecture 22 in the notes to address this).
Thanks for the update Sasha
—Larry
Hi Christian, Larry,
Christian, your question indeed often comes up. I should add to Sacha’s reply that, even if you don’t add extra information, this stuff can be very useful for actual prediction.
*In fact some of the best current data compression algorithms (the CTW method) is based on exactly the worst-case individual sequence idea that Larry described.*
The reason is that the worst-case individual-sequence regret is in many cases hardly larger than the expected regret , where the expectation is over a Bayesian marginal distribution and the distributions are Bayes optimal.
* This means that the absolute worst-case regret is not so far from the absolute nicest-case regret (under Bayesian assumptions) – a quite surprising fact.*
For example if you predict a sequence of bounded random variables
using the worst-case optimal sequential prediction strategy relative to a k-parameter exponential family with log loss, the regret will be (k/2) log n + O(1).
If you look at the expected regret you get if you assume a smooth (otherwise arbitrary) prior with full support over the parameters and you predict sequentially with the Bayesian predictive distribution under that same prior (which is the optimal prediction strategy you can use here) , you get (k/2) log n plus a smaller constant – the difference is quite small for most priors people use in practice. For Jeffreys prior the constant even goes to 0 for large n.
One really interesting question that I’ve seen asked but never quite answered is: Is ERM actually necessary?
Nathan Srebro and Karthik had a paper at a workshop organized by Alekh and Sasha where I first heard the question posed this way.
More specifically: we often write down some convex loss + regularizer and then run some convex optimization routine to minimize the training risk. One way to do this convex optimization is to run stochastic gradient descent, i.e. look at an example compute the gradient, take a step.
There are two ways to think of SGD in this context:
1. Keep running it over the examples (in a randomized order) – we know SGD will converge to the ERM solution if you make enough passes over the data. We also know from statistical learning theory that the ERM is “good”.
2. The other way is to run it just once over the examples (in a random order). The right way to understand SGD now is by noticing we are doing stochastic online convex optimization on the population risk directly. Here the online learning regret bounds tell you that the solution is “good”.
As it turns out these two typically give identical upper bounds, and the bounds are tight. In the second case we are not doing ERM, and the algorithm is much simpler (if you assume you have to look at every example at least once – then it is computationally optimal in many cases).
What is the relationship to Thomas M. Cover’s work on optimal prediction and portfolios?
The ideas are the same. Data compression, universal portfolios, optimal prediction of individual sequences- they are all based on the same concept.
For a universal portfolio the set of “experts” is all possible “constantly rebalanced portfolios” and the best one (in hindsight) can be tracked sequentially ((without hindsight). When I first learned about these portfolios I was more than a little surprised, considering that stock returns are usually not stationary and can do arbitrarily odd things. Then I realized that since the target expert is constant, I would only be charged with the task of tracking the best “idiot”. It is a beautiful theory though.
Indeed, competing with constant rebalanced portfolios might not be so interesting. Over the past 5-10 years, there has been quite a bit of work on understanding how regret bounds can be extended to infinite sets of experts and strategies, and what is the right way to measure complexity of such a set. For instance, being able to compete with a set of all finite-lookback or finite-memory strategies seems quite interesting.
Rissanen’s minimum description length principle is another way to approach prediction from individual sequences; it seems to fit under the online sequential learning umbrella too. In MDL, the loss is always the log, though, because log loss is related to message length. If you’re familiar with MDL and have some thoughts about it, I would definitely be interested in reading them!
Indeed, log loss plays a big role.
Chapter 9 of Cesa-Bianchi and Lugosi is devoted to log loss.
And Peter Grunwald’s book on MLDL is a wonderful reference.
As you note, the major references are the work by Rissanen,
but also, Andrew barron, Bin Yu and Peter Grunwald.
—LW
Larry – Thanks for this thought-provoking post in an area wholly new to me. What sources would you recommend for that provide the best non-trivial example applications? (I am especially interested in those sources with multivariate apps as you also mentioned in responses to comments.) I plan to dig into the references your provide (also thanks for these!) and comb through Google scholar results with your suggested query term, but it would be nice to have some applied material to walk through the theories and aid my comprehension. One more query: do you know of any software tools (maybe R?) which provide functions aligned to this discipline? It seems the frequentist methods are available in everything. Thanks again!
I don’t actually have good recommendations for
examples. Perhaps someone else does?
–LW
I’m sure others out there will have better suggestions for applications but in the machine learning literature there are applications where people want to make predictions in real time or have strong reasons to move away from i.i.d assumptions. Also, online convex optimization algorithms are widely applied in “big data” problems. Some theorists who have worked a bit on applications)
http://eprints.pascal-network.org/archive/00004161/01/ShalevThesis07.pdf (section on applications)
ftp://ftp.cs.princeton.edu/reports/2006/766.pdf (for a description of applications in computation bio and portfolio optimization)
Computer scientists have been studying online algorithms from the viewpoint of competitive analysis (instead of regret) for many years. The wikipedia page talks about a few applications (but there are many many more algorithms for paging, queueing, server allocation, routing etc. that have been analysed this way and can be found with a little google searching)
http://en.wikipedia.org/wiki/Competitive_analysis_(online_algorithm)
Thanks for the great reading recommendations, sivaramanb!
This is cool, especially the part where you figure you have an adversary who is actively trying to mess with you. How do I apply this to defending really big computer networks from intruders? And to what extent do I need to measure regret? Eg, if an enemy breaks into my network and steals stuff very surreptitiously, it could be that I would never even discover such a thing, and thus would not even know to regret it in light of my current observed history? I suppose it comes in to the equation of making sure I have a good robust algorithm to start with.
2 Trackbacks
[…] Não, não é nada Bayesiano nem frequentista. É outra coisa. […]
[…] about data and using probability to understand variation in the data. Except when it isn’t. Probability free statistics looks a lot like frequentist statistics, except it ignores probability theory entirely. So while […]