When you are a student, one of the first problems you learn about is the two-sample test. So you might think that this problem is old news. But it has had a revival: there is a lot of recent research activity on this seemingly simple problem. What makes the problem still interesting and challenging is that, these days, we need effective high dimensional versions.
I’ll discuss three recent innovations: kernel tests, energy tests, and cross-match tests.
This post will have some ML ideas that are mostly ignored in statistics and as well as some statistics ideas that are mostly ignored in ML.
(By the way, much of what I’ll say about two-sample tests also applies to the problem of testing whether two random variables 


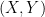
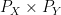
1. The Problem
We observe two independent samples:

and

(These are random vectors.) The problem is to test the null hypothesis

versus the alternative hypothesis

The various tests that I describe below all define a test statistic 


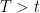

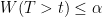
where 
Some of the test statistics
There are four ways:
- We may be able to find
- We may be able to find the large sample limit of
- Bootstrapping.
- Permutation testing.
The coolest, most general and most amazing approach is number 4, the permutation approach. This might surprise you, but I think the permutation approach to testing is one of the greatest contributions of statistics to science. And, as far as I can tell, it is not well known in ML.
Since the permutation approach can be used for any test, I’ll describe the permutation method before describe any of the test statistics.
2. The Amazing Permutation Method
Let
0
0
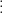
0
1
1
1
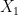
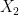
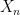
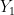


We have added group labels to indicate the two samples. The test statistic 

If 
Now we randomly permute the group labels and recompute the test statistic. This changes the values of 
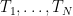

Finally, we define the p-value

where 

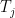


There are no approximations here. There are no appeals to asymptotics. This is exact. No matter what the statistic
Now we can discuss the test statistics.
3. Kernel Tests
For a number of years, a group of researchers has used kernels and reproducing kernel Hilbert spaces (RKHS) to define very general tests. Some key references are Gretton, Fukumizu, Harchaoui, Sriperumbudur (2012), Gretton, Borgwardt, Rasch, Sch{ö}lkopf and Smola (2012) Sejdnovic, Gretton, Sriperumbudur and Fukumizu (2012).
To start with we choose a kernel 

The test statistic is

There is some deep theory justifying this statistic (see above references) but the intuition is clear. Think of 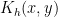


The aforementioned authors derive many interesting properties of
If you are paying close attention, you will have noticed that there is a tuning parameter 

We don’t have to. We can define a new statistic

This new statistic has no tuning parameter. The null distribution is a nightmare. But that doesn’t matter. We simply apply the permutation method to the new statistic
4. Energy Test
Szekely and Rizzo (2004, 2005) defined a test (which later they turned into a test for independence: see Szekely and Rizzo 2009) based on estimating the following distance between 

where 

Now, 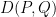

5. The Cross-Match Test
There is a long tradition of defining two sample tests based on certain “local coincidences.” I’ll describe just one: the cross-match test due to Paul Rosenbaum (2005).
The test works as follows. Ignore the labels and treat the data as one sample 

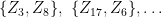
(For simplicity, assume there are an even number of observations.) However, we don’t pick just any matching. We choose the matching that minimizes the total distances between the points in each pair. (Any distance can be used.)
Now we look at the group labels. Some pairs will have labels 


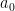

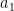
Define 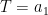

where 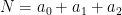
In fact, this distribution can be accurately approximated by a Normal with mean 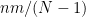
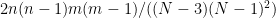
So the nice thing about Rosenbaum’s test is that it does not require the permutation methods. This might not seem like a big deal but it is useful if you are doing many tests.
6. Which Test Is Best?
There is no best test, of course. More precisely, the power of the test depends on
If you are undecided about which test to use, you can always combine them into one meta-test. Then you can use the permutation method to get the p-value.
Having said that, I think there is room for more research about the merits of various tests under different assumptions, especially in the high-dimensional case.
7. References
Gretton, A. and Fukumizu, K. and Harchaoui, Z. and Sriperumbudur, B.K. (2012). A fast, consistent kernel two-sample test. Advances in Neural Information Processing Systems, 673–681.
Gretton, A., Borgwardt, K.M., Rasch, M.J., Sch{ö}lkopf and Smola, A. (2012). A kernel two-sample test. The Journal of Machine Learning Research, 13, 723–773.
Rosenbaum, P.R. (2005). An exact distribution-free test comparing two multivariate distributions based on adjacency. Journal of the Royal Statistical Society: Series B, 67, 515-530.
Sejdnovic, D., Gretton, A., Sriperumbudur, B. and Fukumizu, K. (2012). Hypothesis testing using pairwise distances and associated kernels. link
Sz{é}kely, G.J. and Rizzo, M.L. (2005). A new test for multivariate normality. Journal of Multivariate Analysis, 93, 58-80.
Szekely, G.J. and Rizzo, M.L. (2004). Testing for equal distributions in high dimension. InterStat, 5.
Szekely, G.J. and Rizzo, M.L. (2009). Brownian distance covariance. The Annals of Applied Statistics, 3, 1236-1265.
—Larry Wasserman

20 Comments
The Kolmogorov-Smirnov test is worthy of mentioning as well. In my experience, it performs badly when the distributions $P$ and $Q$ differ on the tails. This is due to the nature of the statistic (the Kolmogorov-Smirnov distance between the corresponding empirical distributions).
Good point.
It also does ot generalize to high
dimensions very well.
—LW
Indeed, that is a second Achilles’ heel of the KS test.
Do you know how well the permutation method perfoms in one-dimensional cases where P and Q have different tails but similar “shoulders”?
That’s determined by the choice of test statistic.
The permutation method just finds the critical value.
It doesn’t define the test itself.
—LW
Another approach, used by people who work in Finance, for portfolio’s risk assessment, with a lot sucess is to model the dependency using copulas, usually parametric copulas. In this case, testing for equality reduces to testing independence, that is, if the copula is a product copula. And I think it is not very used neither in Statistics nor in ML.
I wonder what your suggestions when the sample size is small, which is common in lots of context. Permutation or Bootstrapping probably will not work well because the best pvalue you get would be large. Also KS test will never work in this situation. Not sure what you think of parametric modeling+Bayesian regularization which usually perform more robust than general methods? Thanks a lot.
Another type of rank-based nonparametric tests such as Wilcoxon, Mann–Whitney, etc are also used by many people in statistics, might be too conservative in many situations.
I think the large p-value for small samples simply reflects, correctly,
the fact that you don’t have much information. It should be large
in those cases.
—LW
The permutation method is a great idea – do you have any idea how it performs relative to bootstrapping on simulations? i.e. is it more conservative with its test thresholds?
I guess another way to pick thresholds is based on tail bounds for W which are often easy to obtain and more rigorous than plugging in the asymptotic distribution directly without accounting for the errors. At least for the kernel tests, Arthur tells me they aren’t very good though.
There is also this paper by Miles Lopes, Laurent Jacob and Martin Wainwright – for high dimensional two-sample tests when P and Q are Gaussian with different means
http://arxiv.org/abs/1108.2401
The permutation test is exact.
The bootstrap is only approximate.
Should it be clear as to what you mean by exact and approximate here?
Above for the permutation test you used a random sample of just 10,000 while for the naive bootstrap – if the sample size was small enough – one could enumerate all possible sample paths of iid draws from the empirical distribution taken as the true unknown distribution and be exact.
I would suggest the assumptions of the permutation test are strong (i.e. the labels were random and nothing else was) but ofen are ensured to not be too wrong under the (strict Fisher) null.
The combining idea is interesting – given uniform dependent p-values and all the functions that could be entertained to combine them.
It is exact no matter how many random permutations you use.
Exact means: Pr(type I error ) <= alpha
The only assumptions are i.i.d.
No stronger than usual
Nice posting. Regarding this one: “If you are undecided about which test to use, you can always combine them into one meta-test”: is there any reason to believe that the resulting meta-test will be better than a) all b) any or c) a randomly selected one of the three (or more) mentioned approaches? I’m not so sure (which really means that I’m not sure, not that I wanted to say that it’s a bad idea).
I second this question
Good point. It is indeed not really clear which is better
Thanks for this fruitful post.
I am just curious about how to do “two samples t-tests” when there are covariates? Are there some modern methods?
It depends on the setting.
Typically, that corresponds to testing
if a coefficient is 0 in a regression
but a “truly” distribution-free version is not
obvious.
Great posting. The extended version of our ICML paper that discusses equivalence of energy tests and kernel tests has now appeared on arXiv:
http://arxiv.org/abs/1207.6076
What you describe as permutation seems to me identical to what I have seen called bootstrapping where the resampling is done from the “pooled” sample. The label does not concern me, but I do wonder what you mean when you say that the permutation test is exact, while he bootstrap is only approximate.
They are similar but not the same.
The bootstrap samples n observations from the empirical distribution.
(Actually, in a testing problem, the empirical has to be corrected to
be consistent to the null hypothesis).
The type I error goes to 0 as the sample size goes to infinity.
In the permutation test, the type I error is less than alpha.
No large sample approximation needed.
–LW
I am interested in using the permutation method combined with the energy test to compare the distributions of a training dataset and a dataset generated from a Bayesian belief network that was learned from the training data. I’m a bit of a noob as far as statistical tests go, but how would you calculate the power of such a test, and the minimum sample size? Also, does this testing method require that both datasets come from different sources, as the KS test does? Thanks in advance.
2 Trackbacks
[…] Normal Derivate explains the the modern two-sample test. […]
[…] to test versus , you can get an exact, distribution-free test by using the permutation method. See here. We rarely search over all permutations. Instead, we randomly select a large number of […]