BOOTSTRAPPING AND SUBSAMPLING: PART I
Bootstrapping and subsampling are in the “amazing” category in statistics. They seem much more popular in statistics than machine learning for some reason.
1. The Bootstrap
The bootstrap (a.k.a. the shotgun) was invented by Brad Efron. Here is how it works. We have data 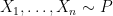
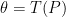


The 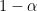
![\displaystyle C_n = \left[ \hat\theta - \frac{\hat t_{1-\alpha/2}}{\sqrt{n}},\ \hat\theta - \frac{\hat t_{\alpha/2}}{\sqrt{n}}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++C_n+%3D+%5Cleft%5B+%5Chat%5Ctheta+-+%5Cfrac%7B%5Chat+t_%7B1-%5Calpha%2F2%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C%5C+%5Chat%5Ctheta+-+%5Cfrac%7B%5Chat+t_%7B%5Calpha%2F2%7D%7D%7B%5Csqrt%7Bn%7D%7D%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
where 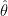




Now for some details. Think of the parameter of interest 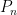

In other words, 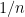

The estimator is just the function 

Now let
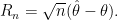
We use 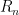


Suppose, for a moment, that we did know 


It follows that
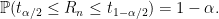
Continuing with the fantasy that we know
![\displaystyle \Omega_n = \left[ \hat\theta - \frac{t_{1-\alpha/2}}{\sqrt{n}},\ \hat\theta - \frac{t_{\alpha/2}}{\sqrt{n}}\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5COmega_n+%3D+%5Cleft%5B+%5Chat%5Ctheta+-+%5Cfrac%7Bt_%7B1-%5Calpha%2F2%7D%7D%7B%5Csqrt%7Bn%7D%7D%2C%5C+%5Chat%5Ctheta+-+%5Cfrac%7Bt_%7B%5Calpha%2F2%7D%7D%7B%5Csqrt%7Bn%7D%7D%5Cright%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Now I will show you that 

We engineered 

The problem is that we don’t know 

- Draw
observations
from
from these new data.
- Repeat step 1
.
- Approximate
where
denotes the indicator function.
- Find the quantiles
and construct
as defined earlier.
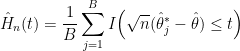
The interval 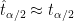


There are two sources of error. First we approximate

with

Essentially, we are replacing 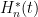

This second source of error is negligible because we can make
Remark: A moment’s reflection should convince you that drawing a sample of size
2. Why Does It Work?
If
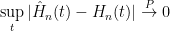
in which case

as 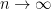
It is non-trivial to show that 
3. Why Does It Fail?
The bootstrap does not always work. It can fail for a variety of reasons such as when the dimension is high or when
An example of a bootstrap failure is in the problem of estimating phylogenetic trees. The problem here is that 
In fact, this is a general problem with the bootstrap: it is most useful in complex situations, but these are often the situations where the theory breaks down.
4. What Do We Do?
So what do we do when the bootstrap fails? One answer is: subsampling. This is a variant of the bootstrap that works under much weaker conditions than the bootstrap. Interestingly, the theory behind subsampling is much simpler than the theory behind the bootstrap. The former involves little more than a simple concentration inequality while the latter uses high-powered techniques from empirical process theory.
So what is subsampling?
Stay tuned. I will describe it in my next post. In the meantime, I’d be interested to hear about your experiences with the bootstrap. Also, why do you think the bootstrap is not more popular in machine learning?
References
Efron, Bradley. (1979). Bootstrap methods: Another look at the jackknife. The Annals of Statistics, 1-26.
Efron, Bradley, and Tibshirani, R. (1994). An Introduction to the Bootstrap. Chapman and Hall.
Holmes, Susan. (2003). Bootstrapping phylogenetic trees: Theory and methods. Statistical Science, 241-255.
van der Vaart, A. (1996). Asymptotic Statistics. Cambridge.
P.S. See also Cosma’s post:
here

10 Comments
I think machine learning people do not care about confidence interval too much in general.
In the bootstrap confidence interval do we put estimate of theta from original data, or do we put mean of all bootstrap estimates there? Generally they should be the same, but there are cases where they can differ (e.g. when T is median).
the original
I think one reason the bootstrap isn’t more popular is what Larry mentioned: “it is most useful in complex situations, but these are often the situations where the theory breaks down”. (There’s not much point in going to a lot of effort to get an error bound if the error bound is probably wrong.) Another is that the bootstrap requires re-running your estimation procedure a very large number of times, and often in ML we’re lucky if we can run the estimation procedure once.
I like bootstrap and use it occasionally. However, I think that an important issue with (nonparametric) bootstrap is that some features of P_n are essentially different from P (or our typical idea of P). P_n is basically discrete. This has implications. For example, in clustering, samples from P_n tend to produce larger between-cluster separation than the original sample, because points that could spoil separation can be taken away, but never added. Producing multiple points at the same location can lead to artifacts in clustering, but also in covariance-matrix estimation or group-wise covariance matrices in classification (implosion of eigenvalues). Samples from P_n (with or without multiple points) can have a smaller but not larger convex hull then the original samples etc. So I’d say that one needs to be very careful with bootstrapping statistics that can somehow be affected by discreteness, the convex hull and other problematic features somebody else comes up with.
Yes, I was confused by the comment – “A moment’s reflection should convince you that drawing a sample of size n from Pn is the same as drawing n points with replacement from the original data”. The adequacy of the Pn approximation is exactly what I have trouble convincing myself of even after a moment’s reflection, especially when n is relatively small and T(P) is relatively complex.
I find it interesting that Larry says “an example of a bootstrap failure is in the problem of estimating phylogenetic trees”. In practice this is one of the areas where boostrap is used most often.
P_n is a very accurate estimate of P
This follows from standard empirical process theory
For example, in one-dimension, P( ||P_n – P||_infty > epsilon) < 2e^{-2n epsilon^2}
The issue is the behavior of T(P).
n is not always large, though.
rj444, I believe the “original data” in the statement “drawing a sample of size n from Pn is the same as drawing n points with replacement from the original data” refers to the finite sample we were given, not the true distribution. This is not a statistical claim. It follows from the definitions of the empirical distribution and of sampling with replacement.
I think that’s what you were asking, but I’m sorry if I misunderstood the subject of your confusion.
I prefer to think of the bootstrap as sampling paths from the product space Pn(A)^n WITH replacement which is less efficient than without replacement, but that very quickly decreases with increasing “n”.
Makes it teachable as simple survey sampling, which worked well with undergrad class once. But the BCA correction stuff and why it fails for complex problems seemed way too hard to get accross.
Remember Efron wrote a paper in the early 2000 complaining most statisticians actual do bootstrapping incorrectly.
That included me, in that when the percentile intervals were _simmilar_ to the BCA intervals in applications, I (mis)thought they had no advantage (i.e. I forgot to think about the distribution of intervals over repeated applications).
5 Trackbacks
[…] um ótimo post do Normal Deviate sobre o […]
[…] Larry Wasserman, Bootstrapping and Subsampling, Part I: […]
[…] « Bootstrapping and Subsampling: Part I […]
[…] Sobre bootstraping I e […]
[…] The Bootstrap. I discussed the bootstrap here. Basically, to compute a confidence interval, we approximate the […]