—Larry Wasserman
In this post I want to review an interesting result by David Freedman (Annals of Mathematical Statistics, Volume 36, Number 2 (1965), 454-456) available at projecteuclid.org.
The result gets very little attention. Most researchers in statistics and machine learning seem to be unaware of the result. The result says that, “almost all” Bayesian prior distributions yield inconsistent posteriors, in a sense we’ll make precise below. The math is uncontroversial but, as you might imagine, the intepretation of the result is likely to be controversial.
Actually, I had planned to avoid all “Bayesian versus frequentist” stuff on this blog because it has been argued to death. But this particular result is so neat and clean (and under-appreciated) that I couldn’t resist. I will, however, resist drawing any philosophical conclusions from the result. I will merely tell you what the result is. Don’t shoot the messenger!
The paper is very short, barely more than two pages. My summary will be even shorter. (I’ll use slightly different notation.)
Let 



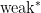

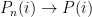

Let 

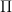
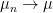


Let 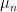



where 

Now we need to recall some topology. A set is nowhere dense if its closure has an empty interior. A set is meager (or first category) if it is a countable union of nowehere dense sets. Meager sets are small; think of a meager set as the topological version of a null set in measure theory.
Freedman’s theorem is: the sets of consistent pairs
This means that, in a topological sense, consistency is rare for Bayesian procedures. From this result, it can also be shown that most pairs of priors lead to inferences that disagree. (The agreeing pairs are meager.) Or as Freedman says in his paper:
“ … it is easy to prove that for essentially any pair of Bayesians, each thinks the other is crazy.”
On the frequentist side, convergence is straightforward here.
Indeed, if 


In fact, even stronger statements can be made; see the recent paper by
Daniel Berend and Leo (Aryeh) Kontotovich
(paper is here).
As a postscript, let me add that David Freedman, who died in 2008, was a statistician at Berkeley. He was an impressive person whose work spanned from the very theoretical to the very applied. He was a bit of a curmudgeon, which perhaps lessened his influence a little. But he was a deep thinker with a healthy skepticism about the limits of statistical models, and I encourage any students reading this blog to seek out his work.

25 Comments
Larry: welcome to the blog world! But please don’t say you’ll exclude Bayesian-frequentist business because far from being discussed to death, the issues—many quite new–have very rarely been properly argued through. You can call it Bayesian-error-statistical. You’ll see what I mean if you pursue foundational issues on your blog.
Frequentist in Exile
> I had planned to avoid all “Bayesian versus frequentist” stuff on this blog because it has been argued to death.
However it’s a good way to get visitors to a new blog. It seems that the statistics blogs have been dominated by Bayesians, so it’s good to get some other points of view.
This comparison seems a little unfair: as I understand it, the Bayesian is evaluated on the posterior mass that gets placed exactly on the correct distribution, whereas the frequentist gets an epsilon of wiggle room.
Actually, the posterior does not even concentrate in epsilon
neighborhoods.
–Larry
My memory is a bit hazy here, but wouldn’t a Dirichlet process (with a positive prior measure on the real numbers) be consistent for this example? If so, this would be imply that the set of (DP, distribution) pairs would also be meager under this topology.
To take meta-subjectivist point of view: if you were to ask any two Bayesians what prior they would use for this example, I would argue that there is a non-zero probability that they would both suggest a type of Dirichlet process.
I guess though that most of the priors that really existing Bayesians tend to write down are consistent, and that the set of “easily downwritable distributions” is meager, too.
Forgive me for being just a lowly software engineer, I don’t understand the math. But isn’t this just saying that most (almost all?) priors in a very unrestricted space are crap?
“ … it is easy to prove that for essentially any pair of Bayesians, each thinks the other is crazy.”
And isn’t this assuming that for every prior, you’ll find some Bayesian to defend it?
3 questions:
– Can we identify an explicit example of such an inconsistent pair?
– Also, in simpler models, there is a sense in which the MLE is identical to the MAP if a uniform prior was used. Does that have any meaning in this broader modelling setup? Is there a general concept of a ‘uniform prior’ and is it consistent?
– If the posterior mass is not concentrated at a point mass at the correct location, where is it? Does it converge to a point mass at an incorrect location, or perhaps it doesn’t converge to a single point mass at all?
Some replies to the comments:
Yes there are plenty of good priors (such as Dirichlet processes) that are consistent under weak conditions.
Are “easily downwritable distributions” a meager set? It would indeed be interesting to try to define that precisely
and prove it.
Does the theorem imply that “most priors” in a nonfinite space “are crap?” I think that is what Freedman was saying but what I just wrote in this comment
suggests we should be cautious about such an interpretation.
Can we identify an example? Yes. The constructions can be very explicit. In one of Freedman’s earlier papers for example
the true distribution is Geometric(1/4) and the posterior converges to a point mass at Geometric(3/4).
Uniform priors: doesn’t really have a meaning in this type of example.
Where does the posterior mass go? It concentrates on an incorrect distribution.
The bigger picture here is this: we can indeed construct priors that have good consistency properties.
But should Bayesians restrict themselves to such priors? They are, after all, a small set of priors?
Some Bayesians will say: yes. Let’s use priors with good frequentist properties.
Some Bayesians will say: who cares what the frequentist properties are.
Anyone who uses Bayesian methods has to decide this for themselves.
(Warning: things get tougher when we look at more stringent conditions than consistency such
as rates of convergence or coverage. But we’ll leave that for another day.)
—Larry
(Thanks for those answers, this is an interesting topic. It’s new to me, and I feel I should gain a slightly deeper understanding.)
I think that consistency might be one of the most Bayesian of the frequentist properties.
To clarify, standard consistency says (informally) that, for infinitely large samples, and for all possible true distributions, the probability is 100% that the estimated distribution will be equal to the true distribution. In short, we ‘condition’ on a particular true distribution and show that a nice property holds no matter which true distribution we ‘condition’ on. This is the idea behind many frequentist concepts such as unbiased estimators and frequentist confidence intervals – show that a property holds ‘for all theta’.
But Bayesians will find it interesting to condition instead on the observed data, x, and ask “what is the conditional probability that a certain nice property holds regarding the closeness of the true distribution to the estimated distribution?”. This is a harder question to answer, and it typically requires a prior. But it’s also typically the more ‘interesting’ question. An applied researcher will often want to look at the data and still be able to make useful statements conditioning on that data. We want this to be true ‘for all x’, not just ‘for all theta’.
Unbiased estimators don’t pass the ‘for all x’ test in general, but consistency does (except for the many exceptions thrown up by this paper!). If the “theta equals estimated-theta” property holds ‘for all theta’, then it holds ‘for all x’ also. Therefore I feel that consistency fits very comfortably into Bayesianism, where unbiased estimators do not fit it.
I would even be tempted to say:
> Some Bayesians will say: yes. Let’s use priors with good *Bayesian* properties such as consistency.
🙂
I’m not familiar enough with measure theory to understand more than the intuitive underpinnings of the argument, so I’d like to ask: Does this work have any implications for model complexity? In particular, a lot of “Google-style machine learning” comes down to using simple models with enormous amounts of data. Would it be better strategy to focus our energy on acquiring large amounts of data to solve problems, rather than working out more complicated models? Maybe more elaborate modeling puts us at greater risk of inconsistency?
I don’t fully understand the math, but based on comments and what I understood, I can’t avoid of thinking about this post:http://delong.typepad.com/sdj/2009/03/cosma-shalizi-waterboards-the-rev-dr-thomas-bayes.html
To me It seems odd that the theorem is about natural numbers. Second, I suspect that almost all priors are crap because almost all priors (in this setting, with natural numbers…) will put zero probability on the true value of theta. Am I wrong?
@normaldeviate said:
> Can we identify an example? Yes. The constructions can be very explicit. In one of Freedman’s earlier papers for example the true distribution is Geometric(1/4) and the posterior converges to a point mass at Geometric(3/4).
Let’s call this true distribution T = Geometric(1/4), and the false one is F = Geometric(3/4).
Freedman’s claim is that, as the sample size tends to infinity, the ratio of the posterior mass(or posterior density) tends to 0.
P(T|x) / P(F|x) -> 0 as n -> infinity
We can use a straightforward rearrangement due to Bayes’s Theorem to get the following expression:
P(T|x) / P(F|x) = P(T)/P(F) * P(x|T)/P(x|F)
A ‘sensible’ prior is a prior which, for any two points in the support of the prior, the *ratio* of their prior mass(or prior density) is a positive, finite, real number. If, on the other hand, this ratio was allowed to be zero or infinite, then I don’t think Freedman’s result would be of any real interest as this would be a ridiculous prior. ( Is this fair? Discuss. )
This tells us that P(T)/P(F), the ratio of the priors masses(densities) is a positive, finite, real number. And according to Freedman, the left-hand-side of that expression tends to zero. Combining these facts, tells us that the final factor, P(x|T)/P(x|F), must be tending to zero also. To be honest, I can’t really believe this.
Where’s the gap in my logic? Assuming that my logic is correct (a big assumption!), then it follows that Freedman’s result depends on allowing non-‘sensible’ priors.
As a followup to my comment of a few minutes ago, I’ve found the relevant section that @normaldeviate is referring to in Freedman’s 1963 paper. It’s a very complicated construct, and as a result I find Freedman’s result to be of less practical interest. I also don’t think it is fair to identify the Bayes’ estimate as being the *mean* of the posterior. If the mode of the posterior is used instead (analogous to the MLE), then I believe that Freedman’s result no longer holds and the posterior mode converges to the correct result. Freedman’s construction is such that the mode tends to the correct result, but that the posterior mean tends to an incorrect result. That is interesting, but given the complexity of the construction, it’s not something to make me worry about consistency. I respectfully suggest that all the priors that have been used in reality by all Bayesians throughout history are consistent in both the posterior mean and the posterior mode.
DA Freedman – The Annals of Mathematical Statistics, 1963 “On the asymptotic behavior of Bayes’ estimates in the discrete case” http://scholar.google.com/scholar?cluster=3661174959167163518&hl=en&as_sdt=0,5
See the 11th page of the pdf, where section “5. Bayes’ estimates are inconsistent” begins. The family of distributions is parameterized by x, a real number between 1/8 and 7/8. The true value of x is 1/4, but the mean of the posterior tends to 3/4, and I’ll attempt to explain how, but first I have to describe this family of distributions which make up the prior. For simplicity, assume a uniform prior on this x; I don’t think the shape of this prior matters. The distribution is not simply a Geometric(x) however. It is a truncated Geometric distribution, where the truncation is controlled by a function f(x). The values 1/4 and 3/4 are special here, because f(x) is defined to be infinite there. This means that, at x=1/4 and at x=3/4, then the distribution is indeed Geometric(1/4) and Geometric(3/4) respectively. These are the exceptions though; for other values of x the distribution is truncated. The function f is such that, as x approaches 1/4 or 3/4, the truncation is at larger and larger values and therefore the distribution becomes closer and closer to a true (untruncated) Geometric. In particular, the truncations are at *much* larger cutoffs around 3/4 than around 1/4, we’ll see why this is interesting later. In summary, we have a large class of almost-Geometric distributions, described by a real-valued parameter x, and that as the value of x approaches 1/4 and 3/4, the distribution do tend to become exactly-Geometric.
(Notation: I had used x to refer to the data in my earlier comments, but to be consistent with Freedman here, x will now be used to index the class of distributions in the prior.)
Now, for any given *finite* sample, there will be many values of x which still have some support on the posterior. Obviously, x=1/4 and x=3/4 will have support as such Geometrics may generate any given sample. There will also be many other values of x, close to 1/4 and 3/4, which have support in the posterior because the almost-Geometrics are truncated at very high cutoffs and therefore all the sample data is below the cutoff. But some values of x will have been ruled out; if f(x) gives a cutoff of 1000 and the sample contains the number 1001, then that value of x is ruled out.
As you use larger and larger sample sizes, the maximum number in the sample is larger and hence the allowable values of x get smaller and smaller. In the posterior, there will be two peaks around x=1/4 and x=3/4 and these peaks will get narrower and narrower as the sample size increases. But, as I said a couple of paragraphs ago, the cutoffs are much higher around 3/4 than around 1/4, therefore the peaks will be fatter around 3/4 than around 1/4. Informally, the set of allowable xs will be larger around 3/4 than around 1/4. Because it is much fatter, it is able to pull the posterior *mean* towards 3/4. So, the peak is wider at 3/4, but actually it’s not very tall. The value x=1/4 is still the best fit for the data as that is the correct value of x, therefore the peak at 1/4 will be taller and thinner.
The posterior will be taller, but thinner, at the correct answer (x=1/4) and it will be smaller, but fatter, at the incorrect answer (x=3/4). The posterior mean will tend towards 3/4 and the posterior mode will tend towards 1/4. The posterior mode is consistent (as far as I can see), but the posterior mean is not.
It’s a fun theoretical construct, but I’m not convinced it has much more value.
Actually it is not an issue of mode versus mean.
The whole posterior (not just the mean) fails to converge.
But I agree that this is easy to fix. Any prior that puts positive mass in each neighborhood of
the true distribution (plus satisfies a tail condition) will be consistent.
So inconsistency can be fixed easily in these cases (even though there are lots of inconsistent pairs).
However, there are are cases where it is not so easy to fix: such as:
Click to access coda.pdf
and
http://arxiv.org/abs/1203.5471
I’ll discuss those issues in the future
–Larry
I take it you agree that, for large finite sample sizes, the posterior mode will be very close to 1/4, just like the MLE? And that, as the sample size grows, the posterior mode and the MLE will get arbitrarily close to each other and to the correct answer?
Weird things happen when you push things to infinity, but I just want to clear up the finite case first. In the real world, we always have finite sample sizes, and hence the posterior mode will do a good job. We can never have an infinitely-large sample, but we can have an arbitrarily-large sample and be confident that the MLE and posterior mode will be very good estimates.
I understand that, as the sample size grows, the proportion of the posterior mass that is close to the wrong answer will grow and that proportion will grow arbitrarily close to 100%. So one can say, with a straight face, that the posterior converges to a point mass at x=3/4 and also that the posterior mode converges on x=1/4. That’s very weird, but things always get weird in these hypothetical ‘infinite-sample’ cases.
There is no mode in this space. In fact, the posterior has no density. This is true in general in nonparametric problems and the set of distributions on the natural numbers is the simplest nonparametric problem. You have to be careful about importing intuition from parametric (finite dimensional) inference to nonparametric (infinite dimensional) inference.
To clarify: When you say:
> There is no mode in this space.
You are saying that, in Freedman’s truncated-Geometric example, with finite sample sizes, there is no posterior mode? By ‘posterior mode’ I mean the value of x which selects the truncated-Geometric distribution where P(x | the sample) is maximized?
If there is no posterior mode, then surely there is no MLE either! The MLE is the value of x which maximizes P(the sample | x).
> You have to be careful about importing intuition from parametric (finite dimensional) …
I don’t believe this is an issue. In Freedman’s example the prior distributions were in a simple one-dimensional space parameterized by x. But even in the general case, the posterior mode is as well-defined as is the MLE – they are the distributions which maximizes either P(distribution | the sample) or P(the sample | distribution).
(Of course, there may be ties – multiple values of x which maximize the appropriate expression. But this is a problem for the MLE also.)
right no mode, no posterior density and no mle
edit:: let me clarify that. In general (for the nonparametric case) there
is no density or mode etc. One parameter subfamilies could have a well-defined
posterior density (and mode). But this doesn’t address the general result.
I hope that clarifies.
Sorry to be persistent, but I’d like to precisely restate my understanding of Freedman’s setup in section 5 of the 1963 paper. At which point below am I incorrect for the first time?
– We generate large finite samples iid from a Geometric(1/4). We call Geometric(1/4) the ‘true distribution’.
– The prior describes a family of distributions, which include the true distribution, but also includes other distributions which are Geometric or truncated-Geometric.
– Regardless of the density or mass that may or may not be associated with each distribution in the prior, I am simply talking about the set of distributions which are supported by the prior.
– The family of distributions which have support in the prior is not so complicated. The family is indexed by a real-valued variable x which ranges from 1/8 to 7/8. Each value of x describes one truncated-Geometric distribution and vice versa.
– For any value of x, we can take the corresponding distribution, which we’ll called Distribution[x], and calculate P(the sample | Distribution[x]).
– This final expression, P(the sample | Distribution[x]), is a real-valued function of x. Distribution[x] is a straightforward distribution with a probability mass function, and the sample is finite, so this function is well defined and easy to understand.
– There will be a value of x (or maybe a set of values of x), which maximizes P(the sample | Distribution[x]). We’ll refer to this value of x as x_hat. If there are multiple such values, we can tie break by selecting the smallest such value.
– This x_hat, as just defined, is the MLE. More precisely the MLE is Distribution[x_hat].
Yes. Sorry. I just edited my reply above as you were posting. I meant that, in the general case (prior and posterior over the set of all distributions) there is no posterior density or mode.
Thanks for all those replies – I’ve learned a lot. I found Freedman’s relatively simple one-dimensional example in the 1963 paper (that I have attempted to describe above) to be quite useful and educational. The setup is simple enough to be amenable to some sort of intuition – the prior is one-dimensional. But it’s complex enough to lead to the unintuitive behaviour.
It’s easy (and maybe justifiable, in my opinion) to dismiss the general theorem on the grounds that it might have no relevance to practical research. “Weird things happen when weird distributions are pushed to the limit at infinity”. If the search space of allowable distributions is too big, then I would think that all methods, Bayesian or otherwise, will behave quite badly.
> The result gets very little attention.
I don’t think that’s a bad thing. I’m sure everybody has their list of papers that they feel deserve more attention. For me, it’s “Testing a point null hypothesis: the irreconcilability of P values and evidence” http://www.jstor.org/stable/10.2307/2289131.
I’m glad I know about Freedman’s result, and it should be known by the hard core theorists. But if this result is to be promoted and appreciated more widely, then I think the simple examples are better. This doesn’t deserve popularity just because it’s correct, it’s going to need good communication.
Fair enough. Thanks for your comments.
A typo in my comment of a few minutes ago. When I said:
> Each value of x describes one truncated-Geometric distribution and vice versa.
I should have said:
> Each value of x describes one truncated-Geometric distribution.
Otherwise, I’m happy with my comment. Although there might be issues with the tie-breaking among the set of xs. Perhaps we should tie break with the *mean*, not the minimum of those xs. I think that works.
Aaron:
Perhaps a simpler and easier to show as practically unimportant example (impossible to happen in applications) is here
(see comment 19 and what seems agreement afterwards)
Larry, the challenge for people with less math skills than you, is that they are worried they are going to be fooled into worrying about things that can’t happen. That people are unintentionally mislead by people with very good math skills is perhaps demonstrated by Peter McCullagh publishing essentially the same error of conditioning on a continuous observation in an example involving ancillarity that Barnard pointed out.
Larry,
Nice to see Freedman’s result again. I do not think “meager” is of much concern. Most of the mathematical objects that we work with, continuous functions, differentiable functions are meager in the larger space of all functions. I have not checked, but guess that many sets of regular experiments considered in statistical theory, usually with some differentiability assumptions, would be meager in the set of all experiments ( under Le Cam’s toplology). It might be interesting to see If E , the set of consistent pairs (P,mu) , is of the second category in itself, i.e in the topology restricted to E
RV
3 Trackbacks
[…] – Almost all” Bayesian prior distributions yield inconsistent posteriors. […]
[…] that for essentially any pair of Bayesians, each thinks the other is crazy. — Larry Wasserman, Freedman’s Neglected Theorem …if you can’t explain how to simulate your theory on a computer, chances are excellent that […]
[…] Tons of interesting stuff on this new blog including here and here, including a link to this really interesting paper about causality. Share this:TwitterFacebookLike […]