I came across a very interesting paper by E. J. Masicampo and Daniel Lalande called A peculiar prevalence of p values just below .05. The link is here. (I saw it referenced at marginal revolution.
1. Peculiar Prevalence
I recommend reading the paper to get the full details. The quick summary is that they collected 3,627 p-values from journals. They found a statistical anomaly in the form of an excess just below 0.05. (They fit a parametric distribution to the p-values and demonstrated a significant departure right below 0.05).
There are some obvious explanations. First, selection bias. Studies with p-values above 0.05 are less likely to be published. Second, the tweaking effect. If you do a study and get a p-value just above .05 you might be tempted to tweak the analysis a bit until you get the p-value just below 0.05. I am not suggesting malfeasance. This could be done quite subconsciously.
You might say: well I would have predicted this would happen anyway. Perhaps. But it is quite interesting to see a carefully done study document and quantify the effect.
E.J. Masicampo was kind enough to share the data with me. Here is a histogram of the p-values.

The jump just below 0.05 is quite noticeable.
2. Multiscale Madness
Now I want to raise a meta-statistical issue. Fitting a parametric model and looking for a big residual is certainly a reasonable approach. But can we do this nonparametrically?
The density of p-values is a mixture of the form
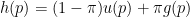
where 
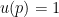

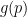

So, statistically, we might want to look for suspicious non-decreasing parts of the density. A good tool for doing this is the distribution free method developed in Dumbgen and Walther (2008). Briefly, the idea is this.
Consider data 
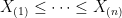
be the order statistics. Now construct all the local order statistics
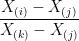
for 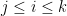
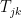
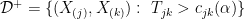
which are the intervals where the density apparently increases. It is possible to explicitly calculate the critical values 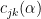

The procedure is implemented in the R package modehunt, written by Kaspar Rufibach and Guenther Walther. When applied to the p-values (I am ignoring a small technical issue, namely, that the data are rounded) we get the following:

The horizontal lines show the intervals with apparent increases in the density. The result confirms the findings of Masicampo and Lalande. There seems to be suspicious increases just below 0.05.
To quote Arte Johnson,
Verrry Interesting!
3. References
Dumbgen, L. and Walther, G. (2008). Multiscale Inference about a density. The Annals of Statistics, 36, 1758–1785.
Masicampo, E.J. and Lalande, D. (2012). A peculiar prevalence of p values just below .05. The Quarterly Journal of Experimental Psychology. http://www.tandfonline.com/doi/abs/10.1080/17470218.2012.711335.
—Larry Wasserman

15 Comments
Very cool, Larry. Thanks for sharing this!
This has been receiving a lot of press lately, I will need to read both more closely, but to those interested another article currently on SSRN does a similar analysis of p-values in top economic journals, . Their histograms look at z-statistics instead of p-values though, so off-the-cuff I can’t tell if the distribution of tests are similar (from the abstract(s) their findings appear to be largely the same though).
Brodeur et al., 2012. Star Wars: The Empirics Strike Back
Same p value finding (absense of p between .05 and .10 or so) found in pol sci by gerber and malhotra. My guess is that anyone with a computer who starts with p under .1 can respecify to hit the magic .05 without effort – since i know we can always get a result with at least one magic star i propose all stats programs do that automatically (much easier than looking at posterior densities).
I thought you were opposed to mixture models. Tequila or some such comparison.
good point!
I don’t understand why p-values between 0.045 and 0.05 have higher residuals and not p-values between 0.05 and 0.055. If scientists are tweaking their p-values, they should make the p-values just above 0.05 disappear… This does not appear in the graph. Other interpretation is that all p-values between 0.05 and 0.1 are under-represented because people don’t publish them. What do you think?
The plot only shows regions where the density is higher than expected
Yes, but in the original paper, the frequency of p-values between 0.05 and 0.1 are shown and there is no deep in frequencies for p-values between 0.05 and 0.055.
Hi Larry, since you have their data set, can you check if the most significant (leading) digit of the p-values is approximately Benford distributed?
I barely have time to get my classes ready!
Ok, sorry! BTW, I’ve just posted a question (linking back to your blog) at Stack Exchange: http://stats.stackexchange.com/questions/38403/distribution-of-published-p-value
So, get ready for a ton of page views.
ok thanks
Interesting histogram and pont! I however wonder at the rationale for looking for a uniform component in the mixture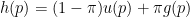 as (a) those p-values are presumably about different models and observations (so no frequentist argument there) and (b) there are so many selection biases in the selection of those p-values that there is no rationale for having a part of them distributed as a uniform “under the null”. Not that your test uses this uniform component anyway…
as (a) those p-values are presumably about different models and observations (so no frequentist argument there) and (b) there are so many selection biases in the selection of those p-values that there is no rationale for having a part of them distributed as a uniform “under the null”. Not that your test uses this uniform component anyway…
I would be interested in a different application of this logic, if you think it is reasonable. In the recent literature of public finance (or any micro-empirical economics) bunching is in fashion as a nonparametric measure of responsiveness where marginal incentives change. (Primary example: Entering a new tax bracket.)
I wonder if you have thoughts on an appealing statistical model of the phenomenon, with a null of no response only noise, and testing. (And of course confidence intervals.) What you did for p-values is not what the pioneers of the approach did for earnings so far. If you have time to skim two pieces, here are the main ones:
Click to access saezAEJ10bunching.pdf
Click to access denmark_adjcost.pdf
Thanks!
Thanks
I’ll have a look at those papers
LW
4 Trackbacks
[…] More here and here. […]
[…] read about this paper at wmbriggs.com first. Then I saw the post at Normal Deviate, which presents an interesting non-parametric treatment of the data (the non-parametric results […]
[…] If we really care about truth-seeking in the social sciences, let alone our own discipline of political science, we would consider null results on significant issues of critical importance. We would certainly consider them more important than the far-too-common paper with a ”positive” result that results from, well, efforts to get to a positive result via “tweaking” (e.g., and, also). […]
[…] but good: I missed this at the time, but Larry Wasserman of Normal Deviate discusses an interesting study showing that, in each of three leading psychology journals, published papers […]