SIMPSON’S PARADOX EXPLAINED
Imagine a treatment with the following properties:
| The treatment is good for men | (E1) |
| The treatment is good for women | (E2) |
| The treatment bad overall | (E3) |
That’s the essence of Simpson’s paradox. But there is no such treatment. Statements (E1), (E2) and (E3) cannot all be true simultaneously.
Simpson’s paradox occurs when people equate three probabilistic statements (P1), (P2), (P3) described below, with the statements (E1), (E2), (E3) above. It turns out that (P1), (P2), (P3) can all be true. But, to repeat: (E1), (E2), (E3) cannot all be true.
The paradox is NOT that (P1), (P2), (P3) are all true. The paradox only occurs if you mistakenly equate (P1-P3) with (E1-E3).
1. Details
Throughout this post I’ll assume we have essentially an infinite sample size. The confusion about Simpson’s paradox is about population quantities so we needn’t focus on sampling error.
Assume that 
 |
(P1) |
 |
(P2) |
 |
(P3) |
Here, 
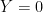

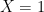
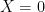

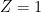
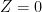
It is easy to construct numerical examples where (P1), (P2) and (P3) are all true. The confusion arises if we equate the three probability statements (P1-P3) with the English sentences (E1-E3).
To summarize: it is possible for (P1), (P2), (P3) to all be true. It is NOT possible for (E1), (E2), (E3) to all be true. The error is in equating (P1-P3) with (E1-E3).
To capture the English statements above, we need causal language, either counterfactuals or causal directed graphs. Either will do. I’ll use counterfactuals. (For an equivalent explanation using causal graphs, see Pearl 2000). Thus, we introduce 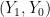


In other words, if
 |
(C1) |
 |
(C2) |
 |
(C3) |
These three statements cannot simultaneously be true. Indeed, if the first two statements hold then
![\displaystyle \begin{array}{rcl} P(Y_1=1) - P(Y_0=1) &=& \sum_{z=0}^1 [P(Y_1=1|Z=z) - P(Y_0=1|Z=z)] P(z)\\ & > & 0. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+-+P%28Y_0%3D1%29+%26%3D%26+%5Csum_%7Bz%3D0%7D%5E1+%5BP%28Y_1%3D1%7CZ%3Dz%29+-+P%28Y_0%3D1%7CZ%3Dz%29%5D+P%28z%29%5C%5C+%26+%3E+%26+0.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Thus, (C1)+(C2) implies (not C3). If the treatment is good for mean and good for women then of course it is good overall.
To summarize, in general we have
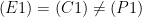


and, moreover (E3) cannot hold if both (E1) and (E2) hold.
The key is that, in general,
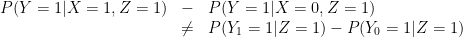
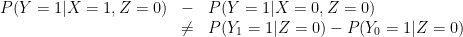
and
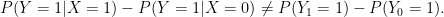
In other words, correlation (left hand side) is not equal to causation (right hand side).
Now, if treatment is randomly assigned, then 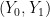

and so we will not observe the reversal, even for the correlation statements. That is, when
In the non-randomized case, we can only recover the causal effect by conditioning on all possible confounding variables 

and similarly, 
![\displaystyle \begin{array}{rcl} P(Y_1=1) &-& P(Y_0=1)\\ & = & \sum_w [P(Y=1|X=1,W=w) - P(Y=1|X=0,W=w) ] P(W=w) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+%26-%26+P%28Y_0%3D1%29%5C%5C+%26+%3D+%26+%5Csum_w+%5BP%28Y%3D1%7CX%3D1%2CW%3Dw%29+-+P%28Y%3D1%7CX%3D0%2CW%3Dw%29+%5D+P%28W%3Dw%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
which reduces the causal effect into a formula involving only observables. This is usually called the adjusted treatment effect. Now, if it should happen that there is only one confounding variable and it happens to be our variable
![\displaystyle \begin{array}{rcl} P(Y_1=1) &-& P(Y_0=1)\\ &=& \sum_w [P(Y=1|X=1,Z=z) - P(Y=1|X=0,Z=z) ] P(Z=z). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++P%28Y_1%3D1%29+%26-%26+P%28Y_0%3D1%29%5C%5C+%26%3D%26+%5Csum_w+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29+-+P%28Y%3D1%7CX%3D0%2CZ%3Dz%29+%5D+P%28Z%3Dz%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
In this case we get the correct causal conclusion by conditioning on
2. What’s the Right Answer?
Some texts make it seem as if the conditional answers (P2) and (P3) are correct and (P1) is wrong. This is not necessarily true. There are several possibilities:
-
- There is no confounder. Moreover, conditioning on
-
Without causal language— counterfactuals or causal graphs— it is impossible to describe Simpson’s paradox correctly. For example, Lindley and Novick (1981) tried to explain Simpson’s paradox using exchangeability. It doesn’t work. This is not meant to impugn Lindley or Novick— known for their important and influential work— but just to point out that you need the right language to correctly resolve a paradox. In this case, you need the language of causation.
3. Conditioning on Nonconfounders
I mentioned that conditioning on a non-confounder can actually create confounding. Pearl calls this 
To elaborate, suppose I want to estimate the causal effect

If
![\displaystyle \theta = \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29+&bg=ffffff&fg=000000&s=0&c=20201002)
that is, the causal effect is equal to the adjusted treatment effect. Let us write
![\displaystyle \theta = g[ p(y|x,z),p(z)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+g%5B+p%28y%7Cx%2Cz%29%2Cp%28z%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
to indicate that the formula for 

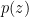
But, if

or
![\displaystyle \theta = \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z)?](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%3D+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29%3F+&bg=ffffff&fg=000000&s=0&c=20201002)
The answer (under these assumptions) is this: if ![{\theta = g[p(y|x)]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta+%3D+g%5Bp%28y%7Cx%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Now, when there are no confounders, the first identity is correct. But is the second actually incorrect or will it give the same answer as the first? The answer is: sometimes they gave the same answer but it is possible to construct situations where
![\displaystyle \theta \neq \sum_z [P(Y=1|X=1,Z=z)-P(Y=1|X=0,Z=z)] P(Z=z).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctheta+%5Cneq+%5Csum_z+%5BP%28Y%3D1%7CX%3D1%2CZ%3Dz%29-P%28Y%3D1%7CX%3D0%2CZ%3Dz%29%5D+P%28Z%3Dz%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
(This is something that Judea Pearl has often pointed out.) In these cases, the correct formula for the causal effect is the first one and it does not involve conditioning on
4. Continuous Version
A continuous version of Simpson’s paradox, sometimes called the ecological fallacy, looks like this:

Here we see that increasing doses of drug
5. A Blog Argument Resolved?
We saw that in some cases 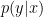
As I recall (Warning! my memory could be wrong), Pearl and Bareinboim were arguing that in some cases, the correct formula for the causal effect was the first one above which does not involve conditioning on
But I think they were talking past each other. When they said that one should not condition, they meant that the formula for the causal effect
6. References
For numerical examples of Simpson’s paradox, see the Wikipedia article.
Lindley, Dennis V and Novick, Melvin R. (1981). The role of exchangeability in inference. The Annals of Statistics, 9, 45-58.
Pearl, J. (2000). Causality: models, reasoning and inference, {Cambridge Univ Press}.

13 Comments
It’s always surprised me that people find it astonishing that conditioning on a variable can induce confounding – in the very simplest case where there is no causal relationship between X and Y but they both have a causal effect on Z it seems obvious that conditioning on Z can render X and Y dependent. Striking examples are easy to come by too – suppose X,Y are independent Bernoulli and Z = X*Y (or X*Y+noise if the determinism is bothersome…).
Yes that example you give certainly makes it clear.
In my open source book on probability and statistics heather.cs.ucdavis.edu/probstatbook I argue that it is only a “paradox” if one condiitons in the wrong order. If one conditions first on the most important predictor, and then adds the second predictor, the results are not at odds with each other.
what do you mean by “most important”? A forward selection type procedure does nothing to address simpson’s paradox (as Jared points out above, it can induce confounding), but maybe you have something else in mind.
Any thoughts (or literature references) for determining what the “correct” confounding variable is (or, conversely, how do you know if you have the wrong one)?
That’s the million dollar question.
Of course you can use variable selection methods.
But you also have to depend on subject matter knowledge.
And there is no escaping the fact that there will always be
some unobserved confounders.
Regarding ordering the variables, all I had in mind was taking action if Simpson’s Paradox is observed. It should be a clue that some other variable should be brought into the analysis first, i.e. the existing ordering should be changed. That should be easy.
Incidentally, I disagree with your characterization of the ecological fallacy
A continuous version of Simpson’s paradox, sometimes called the ecological fallacy…
The ecological “fallacy” was noted by Goodman, who noted that when individual-level data was aggregated, the correlation between two variables was typically different than when individual-level data was available and the correlation was calculated using the individual-level data. His solution was to use linear regression, which gave the same estimate as the individual level estimate of proportion. In a classic case, if the percent of one group supporting a candidate is calculated using the individual data (which is then just the mean of the vote for that candidate, if vote choice is coded 0-1) as it is for the regression estimate (essentially, in an election unit, let V be the vote for the candidate, X1 being the number in group one, p1 being the proportion voting for the candidate in group1, X2 being the number in group 2, p2 being the proportion voting for the candidate in group2, then V = X1p1 + X2p2 = X1p1 + X2p1 – X2p1 + X2p2 = (X1 + X2)p1 + X2(p2 – p1) which gives %Vote = a + %X2b, where b = p2 – p1, a = p1, and %V is percent vote for a candidate and %X2 is percent in group 2). Then the estimates for p1 and p2 from the regression will be approximately the same as from using the individual data _except_ for the empirical fact that the consistency of the p1 and p2, implicitly assumed in the regression, is rarely true. The relationship of the correlation coefficient and violations of this consistency assumption with its implications for regression analysis (including a theory of how central limiting processes imply a distribution on the error in the regression) are discussed at some length in
Arthur Lupia and Kenneth F. McCue. 1990. “Why the 1980’s Measures of Racially Polarized Voting Are Inadequate for the 1990’s.” Law and Policy 12: 353-387.
but it is the violation of the consistency of the coefficients between electoral units that gives the relation to SImpson’s paradox, so the ecological fallacy is a specialized subset of the paradox. In particular, in the example you give above about a drug interaction and gender, there is no aggregate data involved, and hence the term ecological fallacy, as is commonly used in the social science literature, would not be appropriate. It is appropriate to note that Simpson’s paradox (which I would interpret as multiple regimes generating the data) has made it very difficult to do ecological analysis.
ok thanks for the clarification
I guess in the beginning of section 2, instead of ‘Some texts make it seem as if the conditional answers (P2) and (P3) are correct and (P1) is wrong.’, what you’re trying to say is ‘Some texts … (P1) and (P2) are correct and (P3) is wrong.’
right thanks
There’s a nice article by Jim Clark et al. that talks about Simpson’s Paradox in Ecology Letters, with a good representation and explanation in Figure 1:
Clark JS, Bell DM, et al.. (2011). Individual‐scale variation, species‐scale differences: inference needed to understand diversity. Ecology Letters, 14(12), 1273-1287. http://dx.doi.rg/10.1111/j.1461-0248.2011.01685.x
This is often more of an issue when one does observational studies, as is often encountered in practical disciplines such as web traffic analysis for the purpose of internet marketing. I give some examples and explanations here: http://blog.analytics-toolkit.com/2014/segmenting-data-web-analytics-simpsons-paradox/
2 Trackbacks
[…] Equating probabilistic and deterministic statements. […]
[…] 2. New postings and publications 2.1. Larry Wasserman has a nice discussion on Simpson’s paradox posted on his blog. https://normaldeviate.wordpress.com/2013/06/20/simpsons-paradox-explained/ […]