The Steep Price of Sparsity
We all love sparse estimators these days. I am referring to things like the lasso and related variable selection methods.
But there is a dark side to sparsity. It’s what Hannes Leeb and Benedikt Potscher call the “return of the Hodges’ estimator.” Basically, any estimator that is capable of producing sparse estimators has infinitely bad minimax risk.
1. Hodges Estimator
Let’s start by recalling Hodges famous example.
Suppose that 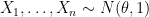
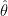




If 
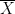

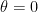


This seems like a good thing. This is what we want whenever we do model selection. We want to discover that some coefficients are 0. That’s the nature of using sparse methods.
But there is a price to pay for sparsity. The Hodges estimator has the unfortunate property that the maximum risk is terrible. Indeed,
![\displaystyle \sup_\theta \mathbb{E}_\theta [n (\hat\theta-\theta)^2] \rightarrow \infty.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Ctheta+%5Cmathbb%7BE%7D_%5Ctheta+%5Bn+%28%5Chat%5Ctheta-%5Ctheta%29%5E2%5D+%5Crightarrow+%5Cinfty.+&bg=ffffff&fg=000000&s=0&c=20201002)
Contrast this will the sample mean:
![\displaystyle \sup_\theta \mathbb{E}_\theta [n (\overline{X}-\theta)^2] =1.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Ctheta+%5Cmathbb%7BE%7D_%5Ctheta+%5Bn+%28%5Coverline%7BX%7D-%5Ctheta%29%5E2%5D+%3D1.+&bg=ffffff&fg=000000&s=0&c=20201002)
The reason for the poor behavior of the Hodges estimator — or any sparse estimator — is that there is a zone near 0 where the estimator will be very unstable. The estimator has to decide when to switch from
I plotted the risk function of the Hodges estimator here. The risk of the mle is flat. The large peaks in the risk function of the Hodges estimator are very clear (and very disturbing).
2. The Steep Price of Sparsity
Leeb and Potscher (2008) proved that this poor behavior holds for all sparse estimators and all loss functions. Suppose that

here, 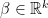



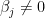




as 
Leeb and Potscher (2008) showed that if
![\displaystyle \sup_\beta E[ n\, ||\hat\beta-\beta||^2]\rightarrow \infty](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Cbeta+E%5B+n%5C%2C+%7C%7C%5Chat%5Cbeta-%5Cbeta%7C%7C%5E2%5D%5Crightarrow+%5Cinfty+&bg=ffffff&fg=000000&s=0&c=20201002)
as 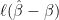
![\displaystyle \sup_\beta E[ \ell(n^{1/2}(\hat\beta -\beta))]\rightarrow \sup_\beta \ell(\beta).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_%5Cbeta+E%5B+%5Cell%28n%5E%7B1%2F2%7D%28%5Chat%5Cbeta+-%5Cbeta%29%29%5D%5Crightarrow+%5Csup_%5Cbeta+%5Cell%28%5Cbeta%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
3. How Should We Interpret This Result?
One might object that the maximum risk is too conservative and includes extreme cases. But in this case, that is not true. The high values of the risk occur in a small neighborhood of 0. (Recall the picture of the risk of the Hodges estimator.) This is far from pathological.
Another objection is that the proof assumes 
I am not suggesting we should give up variable selection. I use variable selection all the time. But we should keep in mind that there is a steep price to pay for sparsistency.
References
Leeb, Hannes and Potscher, Benedikt M. (2008). Sparse estimators and the oracle property, or the return of Hodges’ estimator. Journal of Econometrics, 142, 201-211.
Leeb, Hannes and Potscher, Benedikt M. (2005). Model selection and inference: Facts and fiction. Econometric Theory, 21, 21-59.

20 Comments
Aside from the other objections, a huge problem is that no one would ever truly use such estimators; they would cheat. No way they’ll accept a estimate of 0 for beta when they “know” it’s over 100, say.
And no, I’m not advocating a Bayesian approach. 🙂
I’m not sure what you mean.
People use variable selection estimators all the time.
I assume he means that people would in, say, the case of \ell_1 regularized regression a practitioner would pick a value of the regularization parameter that gives model parameter estimates roughly in line with what the practitioner considered reasonable. So there would be an unaccounted for user intervention in the variable selection process.
The theorem makes no assumption about how the estimator
is constructed, including human judgement,
only that it is sparsistent.
I think the key difference between Hodges estimator and current high-dimensional variable selection, say with the lasso, is that in actual use one typically uses a data-driven and not a fixed threshold (for instance using cross-validation). The same is true for model selection using empirical Bayes where you also adapt to your data. Likewise for the Stein estimator (which, of course, doesn’t do variable selection.
So the question is whether the undesirable risk behaviour is due to L1 vs. L2 regularisation, or due to fixed vs. adaptive choice of threshold? I think it is the latter.
Does the proof in the two papers by Leeb and Pötscher consider adaptive choice of regularisation parameters? Probably not.
The proof applies to any sparsistent estimator
which includes those with data-driven regularization.
So, yes, their theorem does apply in this case.
ok… if this is so then it really is indeed worrying!
Now I have to go and read these two papers…
Actually they are very readable.
The main proof is only a few lines long.
Reading through “…Return of Hodges’ Estimator”, the result is not for precise sparsistency, but for a “sparsity-type condition”, which is that the estimator selects a subset of the true set of nonzero predictors. Some of the exact (the selected set equals the true set) sparsistency results I can recall put an additional constraint on the magnitude of the linear coefficients, which would restrict the set over which the minimax risk is considered. I imagine that the key failure here is “near zero” coefficients inflating the risk, just as with Hodges’ estimator, so this could be important.
This is just a quick reply so I could be totally off here, thanks for the very interesting post.
yes.
They get good risk by
ignoring the zone where the risk is bad!
Yes, this is why this is a nice paper. It is revealing of the differences between theory and practice! After all, what estimator can survive minimax evaluation on the entirety of its potential targets (in this case, all of R^k)? That the bad stuff is right near what sparsity celebrates as its advantage is an inconvenient truth.
In their proof, they assume n goes to infinity while k stays fixed, so that the contiguity trick can be applied. I was wondering if there’s a way of proof without using contiguity to get a result which is applicable to more general asymptotic regime.s
I was wondering the same thing.
It’s not clear.
I did email Hannes about this a while ago.
We’ll see what he thinks
Usually if we’re doing variable selection we pretend that we are interested in throwing away all the regression coefficients that are really zero. But in fact we wouldn’t believe in any statement of the kind “the parameter is exactly zero”, would we? In fact we don’t do variable selection to find “true zeroes”, but we rather want to throw away (i.e., artificially set to zero) all that is “practically meaningless”, which can (often, probably not always) be translated into “having a very small absolute value”. Here what small is may or may not depend on n; it may more often than not *not* depend on n, which of course depends on such non-mathematical issues as the meaning of the variables and the aim of the analysis.
At least if it does not depend on n, there is not really a problem with having a “true” 10^{-6} estimated as zero. Your risk multiplies this by n and therefore it becomes infinity with unlimited n, but this is really inappropriate, because in such an application we are happy if 10^{-6} is estimated as zero regardless of n. So the risk function doesn’t quantify properly what we want.
The dependence on n makes it mathematically a bit more interesting, because here it depends on what speed you want to go down what you’re interested in compared to how precise you demand your estimator should be, which is the factor n in the risk function.
The problem you’re pointing at is then that if we want to do variable selection, we really shouldn’t expect the same precision of estimates around zero that we get if we use the plain “all components in” estimator. This is what the factor n in the squared risk is about: by using it we decide about our unhappiness if we estimate something zero that is indeed not zero. If we are not so picky about very small absolute values, we may replace the n by n^{1/2} or something, and can live happy ever after.
(One of the problems with asymptotics is that using the loss scaling dependent on n based on standard asymptotics, a loss may appear striking even if the distance to the true value is so small in absolute terms that in a given application we couldn’t care less.)
Multiplying the risk by n
doesn’t change anything.
Another way to state the result is that
the maximum risk of a variable selection
estimator divided by the risk of the mle goes to
infinity.
The scaling is just for convenience.
I’d see it the other way round: “dividing by the risk of the MLE” does just the same as multiplying by n, and this may not be appropriate in practice. The *absolute risk* does not converge to infinity, only if you either multiply it by n or divide it by the absolute MLE risk, which converges to zero.
Yes, asymptotically variable selection is infinitely worse than MLE risk, but that’s because the MLE is infinitely good with infinitely many observations and perfect model, which may not be so relevant in practice. And particularly if we *want* a true 10^{-6} estimated as zero with the finite n that we have, we shouldn’t care so much about what the MLE does for infinite n.
I would agree with Christian, the convenience of the mathematical representation is being confused with the practical importance of distinguishing between true 0 and 10^{-6} or making distinctions prior to getting to Geyer’s asymtopia.
Whether an effect is large or small depends on the context. Consider the apparently small number 3.2 * 10^(-11). In joule, this is about the average amount of energy released in nuclear fission of one U-235 atom. (On another scale, this is 200 million electron volts.) Irrespective of scale, it would be unwise to ignore this effect.
To obtain a statistically meaningful sense of scale, one can ask the question of whether or not an effect can be distinguished from zero with high probability based on the available data. As an idealized example, consider a set of n i.i.d. observations from a Gaussian with mean mu and variance s^2. The quantity (n mu / s^2) will be instrumental here; I’ll call it the signal-to-noise ratio. If the signa-to-noise ratio is small, then mu is almost indistinguishable from zero (look at the power of the LR-test). But if the signal-to-noise ratio is large, then the LR test will reject the hypothesis that mu=0 with high probability, and mu can be distinguised from zero with relative ease.
The large worst-case risk of sparse estimators is caused precisely by parameters with moderate signal-to-noise ratio, i.e., by parameters in the statistically challenging region where non-zero effects are hard to distinguish from zero effects.
“Whether an effect is large or small depends on the context.” Just to avoid misunderstandings: I totally agree with that. The value 10^{-6} in my postings basically stands for “whatever is small enough in a given application that we *want* to ignore it if it means that we can get rid of a parameter/variable”. Which is, as I think, what variable selection is about.
This sounds very similar to Yang’s finding in “Can the strengths of AIC and BIC be shared?” (Biometrika 92, 937–950, 2005) that optimal prediction and consistent model identification are mutually exclusive for parametric models. If one is willing to accept the somewhat weaker notion of cumulative risk, we have found that prediction and model identification can be reconciled after all (using a Bayesian approach, but there might be other options) in “Catching up faster by switching sooner: A predictive approach to adaptive estimation with an application to the AIC-BIC dilemma” (Van Erven, Grünwald, De Rooij, 2012, JRSS-B, vol. 74, no. 3). Makes me wonder whether the same holds at the level of generality considered by Leeb and Potscher.