Mladen Kolar, Alessandro Rinaldo and I have uploaded a paper to arXiv entitled “Estimating Undirected Graphs Under Weak Assumptions.”
As the name implies, the goal is to estimate an undirected graph  from random vectors
from random vectors 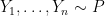 . Here, each
. Here, each 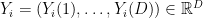 is a vector with
is a vector with  coordinates, or features.
coordinates, or features.
The graph has nodes, one for each feature. We put an edge between nodes  and
and  if the partial correlation
if the partial correlation 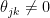 . The partial correlation
. The partial correlation 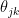 is
is
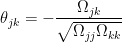
where 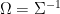 and
and  is the
is the 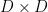 covariance matrix for
covariance matrix for 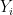 .
.
At first sight, the problem is easy. We estimate with the sample covariance matrix
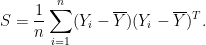
Then we estimate  with
with  . We can then use the bootstrap to get confidence intervals for each and then we put an edge between nodes and if the confidence interval excludes 0.
. We can then use the bootstrap to get confidence intervals for each and then we put an edge between nodes and if the confidence interval excludes 0.
But how close is the bootstrap distribution 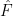 to the true distribution
to the true distribution  of
of 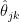 ? Our paper provides a finite sample bound on
? Our paper provides a finite sample bound on 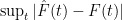 . Not surprisingly, the bounds are reasonable when
. Not surprisingly, the bounds are reasonable when 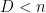 .
.
What happens when  ? In that case, estimating the distribution of is not feasible unless one imposes strong assumptions. With these extra assumptions, one can use lasso-style technology. The problem is that, the validity of the inferences then depends heavily on strong assumptions such as sparsity and eigenvalues restrictions, which are not testable if
? In that case, estimating the distribution of is not feasible unless one imposes strong assumptions. With these extra assumptions, one can use lasso-style technology. The problem is that, the validity of the inferences then depends heavily on strong assumptions such as sparsity and eigenvalues restrictions, which are not testable if 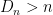 . Instead, we take an atavistic approach: we first perform some sort of dimension reduction followed by the bootstrap. We basically give up on the original graph and instead estimate the graph for a dimension-reduced version of the problem.
. Instead, we take an atavistic approach: we first perform some sort of dimension reduction followed by the bootstrap. We basically give up on the original graph and instead estimate the graph for a dimension-reduced version of the problem.
If we were in a pure prediction framework I would be happy to use lasso-style technology. But, since we are engaged in inference, we take this more cautious approach.
One of the interesting parts of our analysis is that it leverages recent work on high dimensional Berry-Esseen theorems namely the results by Victor Chernozhukov, Denis Chetverikov and Kengo Kato which can be found here.
The whole issue of what assumptions are reasonable in high-dimensional inference is quite interesting. I’ll have more to say about the role of assumptions in high dimensional inference shortly. Stay tuned. In the meantime, if I have managed to spark your interest, please have a look at our paper.

2 Comments
I am glad to see a graphical model not strongly relying on the divine normality assumption.
Hi Larry,
I think this paper would have helped me a lot about six months ago, and I look forward to getting a chance to sit down and read it.
Just from reading your summary of it here in the blog, though, it seems as if you’re stuck with doing a ton of matrix inverses, which is going to put a limit on the maximum size of D (both in the time required to compute them and the space required to store them (much less the space to store the sample covariances or even Y-Ybar in the large-n case!)