LOST CAUSES IN STATISTICS II: Noninformative Priors
I thought I would post at a higher frequency in the summer. But I have been working hard to finish some papers which has kept me quite busy. So, apologies for the paucity of posts.
Today I’ll discuss another lost cause: noninformative priors.
I like to say that noninformative priors are the perpetual motion machines of statistics. Everyone wants one but they don’t exist.
By definition, a prior represents information. So it should come as no surprise that a prior cannot represent lack of information.
The first “noninformative prior” was of course the flat prior. The major flaw with this prior is lack of invariance: if it is flat in one parameterization it will not be flat in most other parameterizations. Flat prior have lots of other problems too. See my earlier post here.
The most famous noninformative prior (I’ll stop putting quotes around the phrase from now on) is Jeffreys prior which is proportional to the square root of the determinant of the Fisher information matrix. While this prior is invariant, it can still have undesirable properties. In particular, while it may seem noninformative for a parameter 




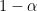
This is a general problem with noninformative priors. If 
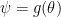
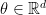

Jim Berger and Jose Bernardo wrote a series of interesting papers about priors that were targeted to be noninformative for particular functions of
A more fundamental question is: what does it mean for a prior to be noninformative? Of course, people have argued about this for many, many years. One definition, which has the virtue of being somewhat precise, is that a prior is noninformative if the
In general, it is hard to construct matching priors especially in high-dimensional complex models. But matching priors raise a fundamental question: if your goal is to match frequentist coverage, why bother with Bayes at all? Just use a frequentist confidence interval.
These days I think that most people agree that the virtue of Bayesian methods is that it gives you a way to include prior information in a systematic way. There is no reason to formulate a “noninformative prior.”
On the other hand, in practice, we often deal with very complex, high-dimensional models. Can we really formulate a meaningful informative prior in such problems? And if we do, will anyone care about our inferences?
In 1996, I wrote a review paper with Rob Kass on noninformative priors (Kass and Wasserman 1996). We emphasized that a better term might be “default prior” since that seems more honest and promises less. One of our conclusions was:
“We conclude that the problems raised by the research on priors chosen by formal rules are serious and may not be dismissed lightly: When sample sizes are small (relative the number of parameters being estimated), it is dangerous to put faith in any default solution; but when asymptotics take over, Jeffreys’s rules and their variants remain reasonable choices.”
Looking at this almost twenty years later, the one thing that has changed is the “the number of parameters being estimated” which these days is often very, very large.
My conclusion: noninformative priors are a lost cause.
Reference
Kass, Robert E and Wasserman, Larry. (1996). The selection of prior distributions by formal rules. Journal of the American Statistical Association, 91, 1343-1370.

21 Comments
Most people I’ve talked to think the virtue of Bayesian approaches is not the ability to systematically include prior information, but rather its ability to combine information efficiently.
In most data analysis scenarios outside of a controlled experiment the distinction between “prior data” and “data” is a semi-arbitrary anyway. More and more data analysis is happening outside of controlled experiments (e.g. nate silver’s prediction models, high dimensional case/control designs in biology), which is why I suspect approaches such as empirical bayes and multilevel models are getting popular. The (hyper)priors mainly serve to “glue” the latent structure of a model.
Part of the motivation of the Shafer-Dempster theory was to avoid the problems with specifying (or being unable to acceptably specify) ignorance (or non-information). While this theory has been pretty much rejected by the statistical community, it has found numerous applications in the computer science/machine learning community. Any thoughts on whether this theory can resolve some of the issues you discuss (note that this theory can combine information efficiently, which, as rj444 notes, is an attraction of Bayesian analysis).
Interesting question.
I did my thesis on Dempster-Shafer theory 25 years ago.
I’ll post about this in the future.
Larry:
I agree with you. In some specific cases, noninformative priors can improve our estimates (see here, for example), but in general I’ve found that it’s a good idea to include prior information. Even weak prior information can make a big difference (see here, for example).
And, yes, we can formulate informative priors in high dimensions, for example by assigning priors to lower-dimensional projections that we understand. The key, I think, is to have the goal of the prior being informative without hoping that it will include all our prior information. Which is the way we typically think about statistical models in general.
P.S. I intended the first “see here” above to link to this paper.
One question on the second part of your comment, Andrew. In formulating priors in high-dimensional settings, you mention “assigning priors to lower-dimensional projections that we understand”, which seems like an eminently reasonable strategy. However, if we are assigning priors to such projections, it would seem that we are left with the problem of expressing “ignorance” with respect to the remaining dimensions. Do you see a resolution to this issue, or does the projection approach circle around to the classical problem of creating non-informative priors?
Alex:
I’d still like to be weakly informative on these other dimensions. We still have a ways to go, though, in developing intuition and experience with high-dimensional models such as splines and Gaussian processes.
In my humble opinion, selection of a prior is very much tuned to the area and objective of the Bayesian Methods applications.
While the Non-Informative (NI) prior may be rejected as an useful prior in one application, it may be an indispensable tool in another one. In the area of ‘ Wavelet Modeling’ , where more than one parameters exist, in the wave decomposition, dependencies may exist between at least two of those parameters. In such cases, assigning a NI prior to act in such a way that it lets one to arrive at an analytically tractable and meaningful signal. Without setting the NI in that way, it may not be possible to arrive at that inference.
Not in a direct way, but in an indirect way, it proves to be a valuable alternative with more information than a classical
approach in such a situation.
Certain areas of applications have proven to be more user friendly to Bayesian methods showing good useful results.
In Wavelet Modeling, Bayesian methods have certainly been very useful.
Another area is the Bayesian Network.
I found the following reference an excellent source of information on Wavelet modeling.
1999, Peter Muller & Brani Vidakovic , Editors
“Bayesian Inference in Wavelet-Models”
Lecture Notes in Statistics, 141
Springer.
Thank you,
Sumedha
An Outlier of the Stat Domain.
…talking about matching priors: in simple parametric cases, you must be Jeffreys (i.e. noninformative in a sense) to be matching (Welch & Peers, 1963…I guess).
In slightly more complicated situations (e.g. mixtures), to be matching you have to be data-dependent = informative, in another sense (…that’s you Larry, right?). Sooo, moving to even more complicated settings (nonparametrics), is there any room to be informative & matching? Probably Richard Nickl has something to say on this point. Then, assuming all this makes sense, in this process that moves from noninfo to info is there a phase transition w.r.t. the model complexity?
Indeed. I am skeptical about finding matching priors in complex models.
In my understanding, priors are part of the model specification. Therefore, the interesting question really is not uniformative priors (that do not exist) but *implied* priors. I believe that every sensible frequentist procedure has a Bayesian interpretation, or at least an interpretation as approximation to a Bayesian procedure. This is the reason why matching priors are so important – not to mimick frequentist procedures but to understand them properly!
I don’t agree that every sensible frequentist procedure
has a Bayesian interpretation even approximately.
Examples are the permutation test and this previous post:
Larry: to say that uninformative priors don’t exist or are a lost cause is to say that the uniform discrete distribution does not exist or is a lost cause. I doubt this is a claim you want to make?
Let me elaborate: to counter your claim about uninformative priors, we only need a single counterexample so let’s talk about the simplest, and most well known one (not the Jeffreys prior, and not the continuous uniform distribution!), which arises in discrete problems. Whenever we formulate a Bayesian model for a coin- or dice-tossing problem (or one of their many real-world equivalents), part of the model is a prior on the set of discrete outcomes. In many, perhaps most, of these problems, we do not have any reason to bias the prior in a specific direction (no a priori reason to assign higher probability to some of the possible discrete observations than to others) – in these cases, the principle of indifference forces us to adopt the uninformative prior, which is just the uniform discrete distribution. It leads to correct and useful solutions to a great many real world problems.
Useful, yes.
But in what sense it is noninformative?
In the sense that it is the prior forced on us by the principle of indifference.
Konrad: It is not so simple here as being clever enough to extend probability to non-finite sets without creating distracting anomalies.
Think of two proportions, say in the treated versus untreated condition, each discrete with uniform priors and look at the implied prior on say the odds ratio.
Larry covered this generally and its sort of an elephant in room in any statistical approach and the second thing in statistics I try to explain to people.
I guess in the case of wavelet modeling example, the contribution of ” information” extracted from the weighted NI prior used for the interdependent parameters, was null. However, the total information was not.
Although i agree, perhaps the name “noninformative” prior is not the appropriate one to be considered for all different applications under all different conditions.
Could you please clarify your point about “The resulting posterior for {\psi} is a disaster.”?
The posterior distribution of each {\theta_i} is normal with variance {1/n}. Then, if you obtain a sample from each {\theta_i} and then transform these samples into a sample of {\psi}, the corresponding posterior should not be that terrible. Am I missing something? Which combination of the true parameters produce such disastrous posteriors?
This paper might also be of interest:
Hidden Dangers of Specifying Noninformative Priors.
http://www.tandfonline.com/doi/abs/10.1080/00031305.2012.695938#.UegMB23BzeQ
The disaster is that the frequentist coverage
of the 95 percent bayesian interval is nearly 0
(in high dimensions)
See section 4.2.2 of my paper with Kass or
Stein (1959, Annals of Mathematical Statistics, 877)
Do you any idea on the coverage of the profile likelihood intervals of this parameter of interest or the bootstrap confidence intervals?
Applied Statisticians are not that popular among the theoreticians. With that in mind, I am still making an analogy with a question and taking another senseless risk.
How do you evaluate the effect of a Placebo in a Clinical Trial ?
It gives one the effect of the Treatment and not the Placebo that has no effect but still is needed there.
9 Trackbacks
[…] Lost Causes in Statistics:II: Noninformative Priors – Normal Deviate […]
[…] Larry Wasserman […]
[…] sponges invade Antarctica All About HD 189733b, That Other Blue Planet Less Research Is Needed LOST CAUSES IN STATISTICS II: Noninformative Priors Were Paleolithic Cave Painters High on Psychedelic Drugs? Scientists Propose Ingenious Theory for […]
[…] How is a noninformative prior like a perpetual motion machine? It would be nice if it existed, but it doesn’t. […]
[…] esteemed Dr. Wasserman claimed “This is a general problem with noninformative priors. If is somehow noninformative […]
[…] small number of people. For instance, in the second post in his series Larry Wasserman identifies noninformative priors as a lost cause. He compares them to perpetual motion machines: “[E]veryone wants one, but they don’t […]
[…] finish by ignoring the only data available and base everything on non-informative priors which prominent authorities assure us don’t even exist. Let the debauchery […]
[…] of noninformative priors in Bayesian statistics. Reminds me of a remark of Larry Wasserman’s, comparing noninformative priors to perpetual motion machines: everyone wants one, but they don’t […]
[…] LOST CAUSES IN STATISTICS II: Noninformative Priors. […]