FLAT PRIORS IN FLATLAND: STONE’S PARADOX
Mervyn Stone is Emeritus Professor at University College London. He is famous for his work on Bayesian inference as well as pioneering work on cross-validation, coordinate-free multivariate analysis, as well as many other topics.
Today I want to discuss a famous example of his, described in Stone (1970, 1976, 1982). In technical jargon, he shows that “a finitely additive measure on the free group with two generators is nonconglomerable.” In English: even for a simple problem with a discrete parameters space, flat priors can lead to surprises. Fortunately, you don’t need to know anything about free groups to understand this example.
1. Hunting For a Treasure In Flatland
I wonder randomly in a two dimensional grid-world. I drag an elastic string with me. The string is taut: if I back up, the string leaves no slack. I can only move in four directions: North, South, West, East.
I wander around for a while then I stop and bury a treasure. Call the path 

Now I take one more random step. Each direction has equal probability. Call the final path 

Two people, Bob (a Bayesian) and Carla (a classical statistician) want to find the treasure. There are only four possible paths that could have yielded

Let us call these four paths N, S, W, E. The likelihood is the same for each of these. That is, 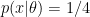
Let 


Now Carla is very confident and selects a confidence set with only one path, namely, the path that shortens 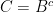
Notice the following strange thing: no matter what 


Here is quote from Stone (1976): (except that I changed his B and C to Bob and Carla):
“ … it is clear that when Bob and Carla repeatedly engage in this treasure hunt, Bob will find that his posterior probability assignment becomes increasingly discrepant with his proportion of wins and that Carla is, somehow, doing better than [s]he ought. However, there is no message … that will allow Bob to escape from his Promethean situation; he cannot learn from his experience because each hunt is independent of the other.”
2. More Trouble For Bob
Let 


On the other hand, Bob notes that 

Bob has just proved that 
3. The Source of The Problem
The apparent contradiction stems from the fact that the prior is improper. Technically this is an example of the non-conglomerability of finitely additive measures. For a rigorous explanation of why this happens you should read Stone’s papers. Here is an abbreviated explanation, from Kass and Wasserman (1996, Section 4.2.1).
Let 
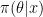
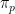


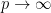
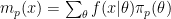
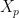





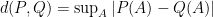

While 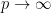
This problem disappears if you use a proper prior.
4. The Four Sided Die
Here is another description of the problem. Consider a four sided die whose sides are labeled with the symbols 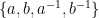

Now we apply an annihilation rule. If 
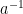


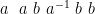
Let us denote the resulting string of symbols, after removing annihilations, by
You get to see
Having observed 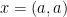

The likelihood function is constant over these four values.
Suppose we use a flat prior on 

Thus 
However, the frequentist coverage of
5. Likelihood
Another consequence of Stone’s example is that, in my opinion, it shows that the Likelihood Principle is bogus. According to the likelihood principle, the observed likelihood function contains all the useful information in the data. In this example, the likelihood does not distinguish the four possible parameter values.
But the direction of the string from the current position — which does not affect the likelihood — clearly has lots of information.
6. Proper Priors
If you want to have some fun, try coming up with proper priors on the set of paths. Then simulate the example, find the posterior and try to find the treasure.
Better yet, have a friend simulate the a path. Then you choose a prior, compute the posterior and guess where the treaure is. Repeat the game many times. Your friend generates a different path every time. If you try this, I’d be interested to hear about the simulation results.
Another question this example raises is: should we ever use improper priors? Flat priors that do not have mass can be interpreted as finitely additive priors. The father of Bayesian inference, Bruno DeFinetti, was adamant in rejecting the axiom of countable additivity. He thought flat priors like Bob’s were fine.
It seems to me that in modern Bayesian inference, there is not universal agreement on whether flat priors are evil or not. In some cases they work fine in others they don’t. For example, poorly chosen improper priors in random effects models can lead to improper (non-integrable) posteriors. But other improper priors don’t cause this problem.
In Stone’s example I think that most statisticians would reject Bob’s flat prior-based Bayesian inference.
7. Conclusion
I have always found this example to be interesting because it seems very simple and, at least at first, one doesn’t expect there to be a problem with using a flat prior. Technically the problems arise because there is group structure and the group is not amenable. Hidden beneath this seemingly simple example is some rather deep group theory.
Many of Stone’s papers are gems. They are not easy reading (with the exception of the 1976 paper) but they are worth the effort.
8. References
Stone, M. (1970). Necessary and sufficient condition for convergence in probability to invariant posterior distributions. The Annals of Mathematical Statistics, 41, 1349-1353,
Stone, M. (1976). Strong inconsistency from uniform priors. Journal of the American Statistical Association, 71, 114-116.
Stone, M. (1982). Review and analysis of some inconsistencies related to improper priors and finite additivity. Studies in Logic and the Foundations of Mathematics, 104, 413-426.
Kass, R.E. and Wasserman, L. (1996). The selection of prior distributions by formal rules. Journal of the American Statistical Association, 91, 1343-1370.

33 Comments
Thanks for presenting this!
You’re welcome
I hope you like the pictures
Great paradox. Can you clarify what you exactly observe in Stone’s paradox? Only x or the whole path? Your two-by-two picture is actually confusing… Ps-Do you know that Costas shared Stone’s office when he was at UCL?!
You observe the whole path.
In other words, x = the whole path
I did not know that about Costas.
Then why is the last step missing in your “South (S)” picture?
The four paths show the 4 possible positions
of the string where I left the treasure
just BEFORE I took one more step.
The green dot is the observed position you see me in.
Having completed my Bachelor’s degree in Statistics in a setting where Bayesian methods are (almost) exclusively used, I have had a fair amount of exposure to Bayesian methods. Indeed, I came to the observation towards the end of my Bachelor’s degree that there is *no* universal agreement on whether flat priors are evil or not – this is an issue I was *always* confused about throughout my undergraduate studies in Statistics and Machine Learning courses! What implications does this paradox have for ones who are learning about Bayesian methods? Is it now a responsibility for us students to learn advanced graph theory before we can *really* understand when we can use flat priors?
No need to learn group theory.
Read Stone’s (1976) paper.
It is very readable.
If I remember it correctly, de Finetti has argued against using flat “information-less” priors; he wanted priors to be informative and stated that there is always some kind of information that can be used to avoid things like the uniform “distribution” over the real line.
Also, if you want to set up this prior in such a way that there is no mass and finite additivity holds, it seems to me that Bob’s inference breaks down because P(N,S,W,E)=0 a priori, and everything that happens later is multiplied by zero. Wouldn’t a Bayesian who wants to use an improper flat prior use a prior that puts positive mass on {N,S,W,E}, but isn’t a probability measure because P(\Omega)=\infty? (I haven’t worked much with improper priors so correct me if I’m wrong.)
The baseline is that the example and the posting are fine and I like them but if you want to bash any Bayesian personally with this, it shouldn’t be de Finetti.
Nicole Jinn: Apart from the computational issues, it is hard to give improper priors a meaning from a philosophical point of view. “Don’t use improper priors at all” doesn’t seem to be the worst advice in my opinion (the problem is not with “flatness” but with “being improper”). But then I’m not a devoted Bayesian.
I have to admit that I was going by my memory butI’ll have to dig out the DeFinetti books.
However, I don’t think your calculation is correct.
In finitely additive land, things with 0 prior probability
can have non-zero conditional probability if I recall correctly.
But again, I need to check on this.
>> There are only four possible paths that could have yielded x … The likelihood is the same for each of these.
I don’t understand this one. At each point retracing a previous step has only prob = 1/4 and therefore the paths with a retracing lst step are less likely.
If the Bayesian uses this information then everything is fine imho, but if Bob does not, well then an important piece of information is not available to him and it is no wonder that her results are worse than Carla’s who seem to know about it.
retracing 1st step … should have been retracing last step
No this is not correct.
Imagine you are standing at any of the four possible paths.
Ask your self: if I take a randome step (equal prob in each direction)
what is the prob of hitting the green spot.
It is 1/4.
The length of the string does not affect how likely you are to move in any direction.
If my description is not clear I urge you to look at Stone’s paper!
>> The length of the string does not affect how likely you are to move in any direction
But that is not the point.
There are two different types of paths: Those with the last step being a retracement step (call them type R) and those with the last step in a new direction (call them type N).
In a random sample of paths the ratio of type R to type N is 1:3
But in the sample of 4 paths Bob considers the ratio is 3:1
There is no “random sample of paths”
The path is fixed.
I urge you to read Stone’s paper.
Larry
The treasure problem looks interesting. I am not sure I quite understand it yet. If I am just confident in a short path shouldn’t Carla have equal confidence in south and west? But I suppose the point is that we observe the taut string?
But in this case we know that we where you are and that you either came from the south or another direction. From the south you have a likelihood of 1/4 that is clear. But if you come from the west shouldn’t the likelihood not only include the probability of going east but also the likelihood of ending up with that observed string?
In this case this should include the probability of having a backtracked path from the observed location starting by going to the west and ending by coming back also from the west. The going and ending is already 1/16 together. Perhaps I should also look at the original paper, but an explanation of what is going wrong in that context here would also help.
The likelihood is just p(x|theta) as a function of there.
For each theta, the probability of x, i.e.
the prob you went to the green dot, is 1/4.
This is a great post! It makes an inaccessible subject much easier to follow – and the figures are great too!
Just a couple of comments… the likelihood/prior decomposition here seems a bit awkward. I don’t think X is i.i.d conditional on theta…
… given this I would prefer to directly specify P(X,theta) a very important aspect seems to be (as you note) the path length p. It seems Carla could be viewed to having a prior with a peak at zero and tapering off where Bob has a strange and unreasonable improper prior here. I would guess that if the prior had a mode in the middle depending on the observed length either a Carla or a Bob like strategy would be preferred.
I am a little confused how it is possible to evaluate repeated performance without specifying the distribution on p (but will re-read)…
I would again speculate that a hierachichal model would allow information about p to be shared between repeats… and could address the concerns in the Stone quote… of course this is avoiding the problem by using proper priors….
There is only one X. No need for iid.
For fixed theta, X is theta + Z where Z
is the last step and Z is in {N,S,W,E}
and each has equal prob.
Over repeated performance the Carla’s confidence interval
has coverage over any sequence
theta1, theta2, …
No need for theta to be random.
This holds for any sequence random or not.
In other words for ANY theta, P(Carla gets treasure | theta) = 3/4
How about only allowing flat priors when they are the uniform limit of proper priors and everything is continuous? I think that’s Jayne’s approach.
That fails in general.
Stone has lots of continuous examples as well.
The problem here is not lack of continuity.
This is surprising, intuitively, if the convergence is uniform and the probability estimate is a continuous function of the prior, I’d expect that the limit of the probability estimates would be meaningful.
Can you point me to an example?
As I see it, the problem here is that the “flat” prior used isn’t the limit of a series of uniformly converging proper priors. hidden observer gives an example below which works, because the flat prior used is exactly that.
I think Stone’s papers may be the best place to look for such examples.
But also, my colleagues Mark Schervish, Teddy Seidenfeld and Jay Kadane
have a paper, if I recall correctly, that every finite additive distribution displays
non-congolmerability in some partition.
It MIGHT be this paper:
Schervish, M.J. and Seidenfeld, T. and Kadane, J.B. (1984)
The extent of non-conglomerability of finitely additive probabilities
Probability Theory and Related Fields
205–226
But I haven’t looked at this in a long time.
A very interesting problem. It definitely proves to me that improper priors are fine…until they’re not. Here is a trick to reproduce the frequentist result (in a limiting sense) with a Bayes prior:
Use the prior p(theta) = p_n = c*(t/3)^n,
where n = length of path theta and c is the normalizing constant (depends on n). This is a proper prior for 0 <= t 0. Using Larry’s notation, the posterior probability for event C under this prior is
p(theta in C | x ) = p_(n-1) / ( p_(n-1) + 3p_(n+1) ) = 1 / ( 1 + t/3 )
It reproduces the frequentist probability of 3/4 in the limit t -> 1. Note that t=1 is a flat (improper) prior, but it’s flat with respect to path length. Since the number of possible paths grows with length, it’s not flat with respect to individual paths.
Typo: it should read “This is a proper prior for 0 <= t < 1"
Very nice to see Mervyn’s important old work given new prominence! Thanks Larry.
But I must take serious issue with your statement:
“…it shows that the Likelihood Principle is bogus. According to the likelihood principle, the observed likelihood function contains all the useful information in the data. In this example, the likelihood does not distinguish the four possible parameter values.”
The second sentence here is correct – if correctly interpreted. It says that if two experimental outcomes (of the same or different experiments) lead to proportional likelihood functions, you should make the same inference from either outcome. But your final sentence has no relationship whatsoever with this! It is a travesty of LP to regard it as requiring indifference between equally likely parameter values.
Philip
Hi Phil!
Glad to have your comments on the blog.
That’s a fair point. The second sentence is really what I meant.
larry
How do you get the result P(A|x) = 3/4 in “Let A be the event that the final step reduces the length of the string. Using his posterior distribution, Bob finds that P(A|x) = 3/4 for each x.”? What is the prior and what is the likelihood over which you computed this posterior?
The prior is the uniform prior over all finite paths.
The likelihood is give as follows: at each you, you
walk in each of the for directions with equal prob.
In symbols theta = x + z
where z is the last step and
P(z=N) = P(z=S)=P(z=W)=P(z=E) = 1/4
as a non statistician, i don’t really follow any of this, except that the buried treasure example seems totally counterintuitive…
can someone explain it to me, without using notation ?
the only thing i can see is that Carlas path requires fewer steps; all the other paths require a go and retrun, whereas the shorter path is one less step
The problem with the Bayesian’s approach in Section 1 is simply that he’s used the wrong likelihood, rather than anything to do with priors.
As is clear from the difference in results between the two strategies, the answer depends in some way on the path. But the likelihood he uses depends only on $\theta$, so it shouldn’t be too surprising his answer turns out to be wrong – he’s assuming the rest of the path makes no difference.
However, if we calculate a likelihood that takes into account which way the last step in the path to $x$ is pointing, the posterior turns out to give a chance of $1/2$ of the treasure being in the direction that shortens the path, and $1/6$ of it being in each of the other directions, thus agreeing with the classical analysis.
This is straightforward to work out if you take a posterior of $\theta$, the two last directions on the path towards it, and the direction taken from $\theta$ to $x$, given the position $x$ and the last direction on the path towards it. Then you sum over all the cases to get the posterior of $\theta$ given $x$ and the last direction on the path towards $x$.
Note that the likelihood Bob took here would be correct, if we could only observe the position $x$ and not the path leading to it.
Posterior gives chance $3/4$ of shortening the path, $1/12$ for the each of the others. That’ll teach me for referencing old, incorrect versions of my working.
My apologies for the late reply, but I stumbled over this post only when I started going through the archive.
I also admire Stone’s article; not just the flatland example, but his very first example of strong inconsistencies as well. Both are very simple, and it is very hard to see where the flaw is in the argument. The blame for these problems (not just strong inconsistencies but marginalization paradoxes as well) is usually assigned to the use of improper priors, but I think that that is misleading. The real problem lies with the formal posterior, which is constructed as if the improper prior were a proper one and whose validity is proven, at best, by analogy with the proper case. If we want to solve the problem of the strong inconsistencies (and of the marginalization paradoxes) we should first find a way to properly define posteriors associated with improper priors; merely writing down the formal prior (because it looks right ?) won’t do. That will only give rise to problems, as Stone and others have shown. I suggest the following construction.
If Bob really wants to use a flat prior (probably a bad choice in the first place, but not an inconsistent one) he should do so by constructing a limit, in some sense, of proper priors. I will refer to this limit as an infinitesimal prior The proper priors can be constructed using a nested sequence of truncations of the improper prior. The value at any given path of this limit is of course 0, so the infinitesimal prior is meaningful only in an integral; that is, Bob should consider the limit of the expectations with respect to the proper priors of, say, bounded functions on the domain of the priors. This limit may not exist for all bounded functions, so a subset L of the set of bounded functions is required. The proper priors give rise to proper posteriors and Bob can define a posterior corresponding to the infinitesimal prior by likewise considering the sequence of expectations with respect to the proper posteriors of, say, bounded functions on the domain of the priors. The following questions then arise: 1) for what bounded functions is the latter limit defined and 2) what is the relation between this limit and the expectation with respect to the formal prior. It turns out that, for fixed data (fixed final path in the example) and if the formal posterior is proper and non-zero for all data (all final paths), the latter limit is defined for all functions in L and using the formal posterior gives the same result as that obtained by taking the limit. That is, the formal posterior can be used, for fixed data, without having to worry about strong inconsistencies (or marginalization paradoxes) if it is proper and non-zero.
To get back to the flatland example, P(A|x) = 3/4 and P(A|theta) = 1/4 are correct, but we cannot integrate over x in the first equality without first going back to the construction of the posterior and see if, when integrating, the formal posterior can still be used in lieu of taking the limit. In the case of the flatland example, the answer is no, and the statement that P(A|x) = 3/4 implies P(A) = 3/4 is false (and Bob did not prove that 3/4 = 1/4). This may seem strange, but it is really the same as the statement that P(theta) = 0 for the infinitesimal prior does not imply that, when integrating this prior, we will always find 0. After all, the integral over the full domain equals 1.
4 Trackbacks
[…] BEST AND WORST. Favorite post: flatland. I still think this is one of the coolest and deepest paradoxes in […]
[…] arises is Stone’s (1976) “Flatland” example. The gist of the example is as follows (see this blog post by Larry Wasserman and Stone’s paper for more details). A sailor takes a number of steps along […]
[…] The first “noninformative prior” was of course the flat prior. The major flaw with this prior is lack of invariance: if it is flat in one parameterization it will not be flat in most other parameterizations. Flat prior have lots of other problems too. See my earlier post here. […]
[…] The first “noninformative prior” was of course the flat prior. The major flaw with this prior is lack of invariance: if it is flat in one parameterization it will not be flat in most other parameterizations. Flat prior have lots of other problems too. See my earlier post here. […]