Statisticians and Computer Scientists have done a pretty poor job of thinking of names for procedures. Names are important. No one is going to use a method called “the Stalin-Mussolini Matrix Completion Algorithm.” But who would pass up the opportunity to use the “Schwarzenegger-Shatner Statistic.” So, I have decided to offer some suggestions for re-naming some of our procedures. I am open to further suggestions.
Bayesian Inference. Bayes did use his famous theorem to do a calculation. But it was really Laplace who systematically used Bayes’ theorem for inference.
New Name: Laplacian Inference.
Bayesian Nets. A Bayes nets is just a directed acyclic graph endowed with probability distribution. This has nothing to do with Bayesian — oops, I mean Laplacian — inference. According to Wikipedia, it was Judea Pearl who came up with the name.
New Name: Pearl Graph.
The Bayes Classification Rule. Give 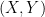



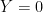

New Name: The Golden Rule.
Unbiased Estimator. Talk about a name that promises more than it delivers.
New Name: Mean Centered Estimator.
Credible Set. This is a set with a specified posterior probability content such as: here is a 95 percent credible set. Might as well make it sound more exciting.
New Name: Incredible Set.
Confidence Interval. I am tempted to suggest “Uniform Frequency Coverage Set” but that’s clumsy. However it does yield a good acronym if you permute the letter a bit.
New Name: Coverage Set.
The Bootstrap. If I remember correctly, Brad Efron considered several names and John Tukey suggested “the shotgun.” Brad, you should have listened to Tukey.
New Name: The Shotgun.
Causal Inference. For some reason, whenever I try to type “causal” I end up typing “casual.” Anyway, the mere mention of causation upsets some people. Some people call causal inference “the analysis of treatment effects” but that’s boring. I suggest we go with the opposite of casual:
New Name: Formal Inference.
The Central Limit Theorem. Boring! For historical reasons I suggest:
de Moivre’s Theorem.
The Law of Large Numbers. Another boring name. Again, to respect history I suggest:
New Name: Bernoulli’s Theorem.
Minimum Variance Unbiased Estimator. Let’s just eliminate this one.
The lasso. Nice try Rob, but most people don’t even know what it stands for. How about this:
New Name: the Taser. (Tibshirani’s Awesome Sparse Estimator for regression).
Stigler’s law of eponymy. If you don’t know what this is, check it out on Wikipedia. The you’ll understand why it name should be:
New Name: Stigler’s law of eponymy.
Neural nets. Let’s call them what they are.
(Not so) New name: Nonlinear regression.
p-values. I hope you’ll agree that this is a less than inspiring name. The best I can come up with is:
New Name: Fisher Statistic.
Support Vector Machines. This might get the award for the worst name ever. Sounds like some industrial device in a factory. Since we already like the acronym VC, I suggest:
New Name: Vapnik Classifier.
U-statistic. I think this one is obvious.
New Name: iStatistic.
Kernels. In statistics, this refers to a type of local smoothing, such as kernel density estimation and Nadaraya-Watson kernel regression. Some people use “Parzen Window” which sounds like something you buy when remodeling your house. But in Machine Learning it is used to refer to Mercer kernels with play a part in Reproducing Kernel Hilbert Spaces. We don’t really need new names we just need to clarify how we use the terms:
New Usage: Smoothing Kernels for density estimators etc. Mercer kernels for kernels that generate a RKHS.
Reproducing Kernel Hilbert Space. Saying this phrase is exhausting. The acronym RKHS is not much better. If we used history as a guide we’d say Aronszajn-Bergman space but that’s just as clumsy. How about:
New Name: Mercer Space.
0. No constant is used more than 0. Since no one else has ever names it, this is my chance for a place in history.
New Name: Wasserman’s Constant.

31 Comments
Great Ideas. And thumbs up to the notion that names do indeed matter.
There are too many things named for Laplace already — it took me a long time to figure out that when people were talking about Laplacian approximations to distribution modes, they weren’t talking about the double-exponential Laplace distribution (which was legitimately confusing, because I thought they were talking about a heavier-tailed substitution.)
I do genuinely agree with “Pearl graph”, even if it means I don’t get to do a Linda Richman with “a Bayesian Network is neither Bayesian nor a network. Discuss.”
Agree Bayesian inference shouldn’t be called that, Fisher coined the term. It was because Bayes implicitly parameterised the Bernoulli distribution using a random variable in his 18th century paper. Laplace (and contemporaries) didn’t name it when they used it because it seemed like the natural thing to do (why name simple application of the laws of probability?). Fisher tried to make it sound unusual by coining the term ‘Bayesian’. Jefferys and contemporaries called it inverse probability which sounds like a much more sensible name to me.
For Bayes Nets, fully agree, but prefer to call them probabilistic graphical models since that’s a name that’s already in use and it describes them nicely.
Surely naming the Bayes classification rule was a mistake in the first place … do we need a name for such an obvious thing?
Definitely don’t agree with renaming neural nets to regression. Regression (to the mean) is a phenomena, not an algorithm, model, or class of techniques. Indeed the entire term ‘non-linear regression’ neglects the near century-long history of researchers who pioneered those techniques and preceded Galton, for example Gauss (famously predicting Ceres orbit), Legendre and Laplace. Whether neural nets is a useful name is a separate debate though.
I’ve been using the term ‘smoothing kernels’ and ‘Mercer kernels’ for some time now when I need to disambiguate. Although in a recent review paper where we needed to disambiguate we went for ‘smoothing kernels’ and ‘reproducing kernels’ (see this preprint http://cbcl.mit.edu/publications/ps/MIT-CSAIL-TR-2011-033.pdf).
A big thumbs down to the idea we should name things after people, I think that spreads the idea that individuals, rather than communities move science forward. Individuals can be important, but the real achievement of science is getting people to work together and share ideas. Eponymy and Nobel prizes work against this. As Stigler points out the Gaussian distribution would be much more fairly called the Laplacian distribution (which would reduce A. C. Thomas’s confusion, because the result of Laplace’s approximation is a Gaussian distribution … indeed that’s how Laplace seems to have stumbled across it in the first place … as a result of doing inverse probability to determine whether a coin was biased). de Moivre also got there before Laplace (although Laplace may well have not known about de Moivre’s work, but Gauss certainly knew Laplace’s because he mentions it in his own work …).
I guess in summary eponymy doesn’t imply causality (formality?)!
I would change Bayesian to Galtonian and regression to the mean to conditioning given the arguments Stigler makes here, including suggestion that laplace and other were not doing real or at least proper Bayesian analysis.
Stigler’s paper is pointed to here http://stats.stackexchange.com/questions/44244/ap-statistics-exam/44265#44265
I don’t know what you’re talking about — Law of Large Numbers is a great name.
Actually I would change the name to Statistics itself and I would go greek on it “Dedomenalogy” (δεδομένα = data), an a statistic (singular) I would call it “sample function”
The name Statistics comes from the times when all there was in statistics was to count how many citizens and cows the State had, wow a days is just a misnomer. Not to mention in Spanish the words “statistic” and “statistician” are the same!! and that “statesperson” is very similar to “statistician” (estadista, estadístico) which leads people to believe politics has something to do with statistics!
Thanks Larry, I hadn’t laughed so hard in a while. I’ll definitely be using “Wasserman’s Constant”.
Neural nets. Let’s call them what they are.
(Not so) New name: Nonlinear regression….
I laughed so hard! How true, how true!
Great post, I think you are being too kind to neural nets though.
Has anybody collected statistics on the number of students currently wondering what a central limit is? It certainly puzzled me for a while.
If you look at the original article by Polya, he argues that this limit theorem is central to probability theory, not that there is some lind of limit of centrality.
How about ‘Fisher’s evidence index’ for the P-value? Fisher’s statistic seems a bit close the the F statistic that Snedecor named for Fisher. FEI would help to combat the erroneous interpretation of a P-value as some sort of measure of error rate.
That’s pretty good.
How about “Fisher’s surprise index”? I reckon “evidence” perhaps should be reserved for log Bayes factors.
Hi Prof. Wasserman, I hope you would not mind – I just translated your blog post to Chinese and publish it on a statistics learning website: http://cos.name/2012/12/new-names-for-statistical-terms/ Please let me know if you have any concerns.
Again, many thanks for your creative renames and efforts on clarification.
sure
Larry: Tracing back, what would be the old name for the fancier “Sure Independent Screening”?
I usually call that, marginal regression.
Yes! that’s what I thought, but cannot find a formal reference for students when they asked. I guess it is so simple that people did’t bother to coin it a fancy name until recently 🙂 Thanks for the fun collection! A new book or a dictionary in the horizon?
At the risk of seeming humorless, I have a serious comment on this entertaining post. It suggests a lot of eponymous nomenclature. This is problematic not only because of Stigler’s Law, but because even when credit is correctly assigned and unambiguous, such terms increase the impenetrability and confusion and decrease the memorability of technical language. Furthermore, it does so often with little benefit or with benefit to those who need it least (the cognoscenti who will do fine with whatever name sticks – although perhaps not, this problem was first brought to my attention by a very smart MD who remarked that he could never remember eponymous anatomical terms). I think that names are, indeed, important. But if I were to picking rules to choosing good names “Avoid eponymity” would be high on the list. Thus, I like “sandwich estimator” or “empirical standard errors” over “Huber-White errors”, for example. For similar reasons, I prefer “equivariant” to “homoskedastic”, which is all Greek to too many people.
My favorite of the suggestions here is “The shotgun”, primarily for the opportunity to accuse someone of bringing a jackknife to a shotgun fight. Though curiously, in “Sunset Salvo” Tukey himself wrote of his preference for jackknifery over bootstrappery.
In physics that Stigler law is called Arnolds rule …
Brian Ripley would be happy if you rename Gibbs sampling as “Ripley’s sampling” as he is always saying that he proposed the method and someone else named it as Gibbs.
Some seriously good suggestions in here. …even some clearly not intended to be taken seriously. Sadly I’m afraid they have as much chance of adoption as tau (==2*pi) has of replacing pi, and thereby simplifing mathematics everywhere (http://tauday.com).
Reblogged this on Stats in the Wild and commented:
My favorite:
Neural nets. Let’s call them what they are.
(Not so) New name: Nonlinear regression.
That was really funny! .. most of all: Wasserman’s constant 😀
N.D.: I’m all for some well-needed name changes, but I would like to voice (a) some gripes/drawbacks with a few of these, and (b) some glaring omissions.
I think in general it’s best not to hang a person’s name on these things, particularly if that name wasn’t already there (so I agree with another commentator). There are enough irrelevant attacks “against the man” slipping into the assessment of statistical tools. The p-value, or the “significance probability” or “significance level” will surely not benefit by being called the “Fisher statistic”, what with Fisher’s achievements being derogated, references to him as “The Wasp”, and as a man who wore rumpled clothes and smoked too much…It already appears as the main character in U-tube clips with titles like “what the p-value”, do we really need “what the #@$% Fisher statistic”?
Bayesian Inference—(N.D. suggests Laplacian Inference): why not just go back to inverse probability? I know many people who are irked that it was ever changed.
Bayesian Nets—(N.D. suggests Pearl graph): I do think a name change is very much needed. Pearl indicated to me long ago that he was intending just to refer to probability. So what’s wrong with a probabilistic net, or a DAG (as many already use), for a directed acyclic graph endowed with probability distribution?
Confidence Interval —(N.D. suggests Coverage set). I think the interval aspect, or even just the use of “bounds” or “limits” are essential. There are counterintuitive “sets” that can have reported coverage. Also, the fact that there is a “confidence concept” (Birnbaum, Fraser) and confidence distributions, might suggest retaining it. A sensible confidence interval should give corroboration bounds, in the sense of indicating well-corroborated values of a parameter. So it seems best to stick with CI bounds or corroboration bounds or the like.
Causal Inference. —(N.D. suggests formal inference): This would get confused with formal deductive inference which obviously needn’t be causal; if anything, causal inference is (strictly speaking) informal inference (in the sense often used in philosophy, i.e., inductive/qualitative).
The Central Limit Theorem and the Law of Large Numbers–N.D. thinks these are boring, but I think the LLN is extremely cool (so I agree with another commentator), and it already already has a BLLN version. The CLT is informative, where de Moivre is not.
Stigler’s law of eponymy. New Name: Stigler’s law of eponymy. I think there is something self-referentially wrong here, since Stigler did name it. That is, if Stigler is right, it should be named after non-Stigler.
Neural nets. Let’s call them what they are. (Not so) New name: Nonlinear regression.
Excellent!
Now for (b): frequentist statistics, sampling theory, and “classical statistics”—must these remain as an equivocal mess? None of these work well. “Sampling theory” does make sense since the key is the use of the sampling distribution for inference, but it doesn’t capture it. Since sampling distributions are used for error probabilities (of methods), one might try error probability statistics, or error statistics for short. That’s the best I could come up with. (I know some people find “error probabilities” overly behavioristic, but I do not.)
What about logistic regression?
any suggestions?
nice post its helpful for me thanks alot
After I originally commented I seem to have clicked the -Notify me when new comments are added- checkbox and from
now on whenever a comment is added I receive four emails with the exact same comment.
Perhaps there is a way you can remove me from that service?
Many thanks!
You’ll need to go to wordpress.com and look at preferences
I don’t have any control over this
7 Trackbacks
[…] Larry Wasserman suggests re-naming “causal inference” methods to “formal inference” methods to avoid confusion, which I fully support (though it might make the formal theorists in Political Science mad). But what I really like is his suggestion to rename “the bootstrap” to “the shotgun,” mostly because I want to teach a method called “shotgunning” in my methods classes. […]
[…] New Names For Statistical Methods – Normal Deviate […]
[…] 原文载于卡耐基梅隆大学统计学院教授Larry Wasserman的博客:Normal Deviate […]
[…] 原文载于卡耐基梅隆大学统计系教授Larry Wasserman的博客:Normal Deviate […]
[…] for fun: Normal Deviate suggests new names for common statistical methods. The best ones are for bootstrapping (let’s call it “shotgunning”!) and a […]
[…] I am comment #17 on Normal Deviant’s clever post offering “New Names For […]
[…] New Names For Statistical Methods (normaldeviate.wordpress.com) […]