Most Findings Are False
Many of you may know this paper by John Ioannidis called “Why Most Published Research Findings Are False.” Some people seem to think that the paper proves that there is something wrong with significance testing. This is not the correct conclusion to draw, as I’ll explain.
I will also mention a series of papers on a related topic by David Madigan; the papers are referenced at the end of this post. Madigan’s papers are more important than Ioannidis’ papers. Mathbabe has an excellent post about Madigan’s work.
Let’s start with Ioannidis. As the title suggests, the paper claims that many published results are false. This is not surprising to most statisticians and epidemiologists. Nevertheless, the paper has received much attention. Let’s suppose, as Ioannidis does, that “publishing a finding” is synonymous with “doing a test and finding that it is significant.” There are many reasons why published papers might have false findings. Among them are:
- From elementary probability
In fact, the left hand side can be much larger than the right hand side but it is the quantity on the right hand side that we control with hypothesis testing.
- Bias. There are many biases in studies so even if the null hypothesis is true, the p-value will not have a Uniform (0,1) distribution. This leads to extra false rejections. There are too many sources of potential bias to list but common ones include: unobserved confounding variables and the tendency to only report studies with small p-values.
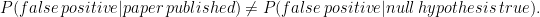
These facts are well-known, thus I was surprised that the paper received so much attention. All good epidemiologists know these things and they regard published findings with suitable caution. So, to me, this seems like much ado about nothing. Published findings are considered “suggestions of things to look into,” not “definitive final results.” Nor is this a condemnation of significance testing which is just a tool and, like all tools, should be properly understood. If a fool smashes his finger with a hammer we don’t condemn hammers. (The problem, if there is one, is not testing, but the press, who do report every study as if some definitive truth has been uncovered. But that’s a different story.)
Let me be clear about this: I am not suggesting we should treat every scientific problem as if it is a hypothesis testing problem. And if you have reason to include prior information into an analysis then by all means do so. But unless you have magic powers, simply doing a Bayesian analysis isn’t going to solve the problems above.
Let’s compute the probability of a false finding given that a paper is published. To do so, we will make numerous simplifying assumptions. Imagine we have a stream of studies. In each study, there are only two hypotheses, the null 
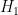



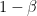

It’s clear that 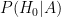
The bias problem is indeed serious. It infects any analysis you might do: tests, confidence intervals, Bayesian inference, or whatever your favorite method is. Bias transcends arguments about the choice of statistical methods.
Which brings me to Madigan. David Madigan and his co-workers have spent years doing sensitivity analyses on observational studies. This has been a huge effort involving many people and a lot of work.
They considered numerous studies and asked: what happens if we tweak the database, the study design, etc.? The results, although not surprising, are disturbing. The estimates of the effects vary wildly. And this only accounts for a small amount of the biases that can enter a study.
I do not have links to David’s papers (most are still in review) so I can’t show you all the pictures but here is one screenshot:
Each horizontal line is one study; the dots show how the estimates change as one design variable is tweaked. This picture is just the tip of the iceberg. (It would be interesting to see if the type of sensitivity analysis proposed by Paul Rosenbaum is able to reveal the sensitivity of studies but it’s not clear if that will do the job.)
To summarize: many published findings are indeed false. But don’t blame this on significance testing, frequentist inference or incompetent epidemiologists. If anything, it is bias. But really, it is simply a fact. The cure is to educate people (and especially the press) that just because a finding is published doesn’t mean it’s true. And I think that the sensitivity analysis being developed by David Madigan and his colleagues will turn out to be essential.
References
Ryan, P.B., Madigan, D., Stang, P.E., Overhage, J.M., Racoosin, J.A., Hartzema, A.G. (2012). Empirical Assessment of Analytic Methods for Risk Identification in Observational Healthcare Data: Results from the Experiments of the Observational Medical Outcomes Partnership. Statistics in Medicine, to appear.
Ryan, P., Suchard, M.A., and Madigan, D. (2012). Learning from epidemiology: Interpreting observational studies for the effects of medical products. Submitted.
Schuemie, M.J., Ryan, P., DuMouchel, W., Suchard, M.A., and Madigan, D. (2012). Significantly misleading: Why p-values in observational studies are wrong and how to correct them. Submitted.
Madigan, D., Ryan, P., Schuemie, M., Stang, P., Overhage, M., Hartzema, A., Suchard, M.A., DuMouchel, W., and Berlin, J. (2012). Evaluating the impact of database heterogeneity on observational studies.

36 Comments
Larry:
This is interesting stuff. Just a quick comment: you write, “The cure is to educate people (and especially the press) that just because a finding is published doesn’t mean it’s true.” A related idea is to be aware of this in the pre-publication stage: just because a finding is statistically significant, it doesn’t mean it should be published.
Also, I agree with you that bias is important, but it is also well known (in both frequentist and Bayesian statistics) that, even in the absence of bias, if you run low-power studies you will get a high rate of meaningless results (Type S and Type M errors, in our terminology). That’s what happened with the notorious beautiful-people-have-more-girls study, where their sample size was about 1/1000th as much as they would’ve needed to really find something. In this setting, people are publishing what is essentially pure noise.
Yes I agree.
And I would add: just because a result is not significant does not mean it should not be published.
Larry:
There are SO many reasons why published observational studies might have false findings, it is There are SO many reasons why published observational studies might have false findings, it is almost hard to imagine that they should ever be published or read by anyone, ever. Unfortunately, like aging, the alternatives are rather bleak.
What surprises me about this line of research, is that I had thought the problems of confounding, misclassification and selection would swamp out this “absence of a pre-specified analytical plan”. But, Madigan and other’s (e.g. Charlie Geyer, Jim Berger) have recently shown that it can lead to very large biases. Unfortunately, the partial remedies that took twenty plus years for randomized clinical trials (e.g. registration of trails with pre-specified analysis plans) would seem out of place here. Pre-specifying an analysis plan for an observational study flies in the face of Fisher’s advice to make them complex and good observational studies often arise serendipitously.
Now the point that Ioannidis and Madigan can get a lot of press (and research funding) out of what many others already know, is just academics 101 – right?
In one of the Madigan’s references you gave, is this a typo “how to correct them [p-values in observational studies]”. Getting the p-values to have a Uniform(0,1) distribution in observational studies given the null is true, is impossible right? Maybe, they are assuming no confounding, misclassification and selection to worry about
I think Madigan’s work is of a very different nature than
Ioannidis. Madigan’s work represents years of very careful research.
Was not being critical of either. Very different training, canvasses and audiences.
The OMOP work that Larry has described (and that Madigan is associated with) does not focus on pre-specification of analytic plans. In fact, pre-specification won’t buy you very much in the face of the dominant issue which is bias.
Getting p-values to be uniform(0,1) under the null is possible when the null distribution is derived empirically from drug-outcome pairs knows to be causally non-associated.
Have you ever notice that when fields try to publish 0% false positives they have an error rate of alpha% and those that try to publish alpha% false positives have error rates > 50%. Statisticians are so wrapped up in their world view they can’t see how bizarre is the claim that a scientists goal is to be wrong a fixed percentage of the time.
The funniest example of this I saw was in the comments in Andrew’s blog one time. I naively suggested that if a 95% CI (or Credibility interval) contained the right answer 100% of the time that was a good thing. Commenters had a strongly negative reaction to foolishness. Everyone knows that a 95% CI is ‘correct’ only if it’s wrong 5% of the time.
Incidentally with alpha=.05 and power=.95 to get a P(H0:A) greater than 50% you have to have a pi greater than 95%. Which means that 95% of the time H0 is true. Consequently you could dramatically improve science if you just accepted every H0 without doing any study at all! (i.e. if you simply published every H0 plausible enough to make a study worthwhile, then 95% of time you’d be correct, which is far better than the current >50% error rate).
P.S. if the life and social sciences take up this suggestion I hope they name it after me and Dr. Wasserman.
Conversely, as Herman Rubin has often pointed out, he needs no data at all to know that (a point null) H0 is (almost certainly) false, and (as Jim Berger has pointed out) it is almost impossible to design an experiment where inevitable biases will make {H0+experimental design} false as far as the experiment is concerned. So you could dramatically improve science by simply rejecting every H0 without doing any study at all!
Bill,
That’s an interesting case to consider. What if pi is really low, say 1%. Then what kind of power do we need to get P(H0;A)=.95 when alpha=.05%? The answer I get is Power=..000027.
Since I think Rubin is basically right about the null hypothesis, then it looks like we can use ridiculously low powered tests and our publishable results will be right 95% of the time. I wonder if they’ll change all the introductory statistics books which emphasize the importance of power?
Entosophy,
So I guess that it means that we should have the Wasserman-Entosophy-Rubin-Berger-Jefferys law, “Don’t bother to take any data, you can do whatever you want”!
Entsophy,
Sorry for misspelling your handle.
More to the point, tests of exact point null hypotheses should be banned. What should be done if this sort of thing is your game is to test hypotheses that are approximate nulls in the sense that (1) the result is important (with “importance” measured in a decision-theoretic sense) if the fuzzy null is false and (2) the experimental design (including the biases of any equipment or implementation) is not going to compromise the result in a significant way. And (3) any reported statistics should properly take (1) and (2) into account.
Bill,
It can surely be patched up along the lines that you mention, but rather than put a Band-Aid on the problem, I’d rather excise the cancer completely.
Oddly, this is similar to the coin flip problem. The frequency of heads is typically .5 so frequentists would say P(heads)=.5. But that’s a probability conditional on a low informational state. I may know nothing about physics, but I do know that if I examine the 2^n sequences of binary outcomes of length n, then a simple counting argument shows almost every sequence has roughly as many heads as tails.
On the other hand, a physicist who partially measures the initial conditions may say P(heads : measurements)=.9. Although the physicist’s probability is no longer equal to a frequency it is far more useful for predicting the next coin flip.
Similarly, here P(H0: A) is equal to a frequency but is a probability conditional on a low informational state. The far more useful yet non-frequency value is P(H0: data) which is entirely analogous to the physicists P(heads: measurements) above. But this is precisely the quantity that Frequentists refuse to consider, for no other reason than they can’t comprehend what it means.
It’s fun to take the CI type logic seriously though. If most null hypothesis are not true (pi=.05) and using alpha=.05 and Power=.99, then assuming all of Wasserman’s bias problems are cleared up you’re still looking at fewer than 1 in 350 published results will be right (P(H0:A)<.003). Which for reasons similar to the coin flip analysis above (and Bill's comments) means that important real world conclusions will be right about half the time (i.e. published results are more or less randomly connected to the relevant truth). This seems to be what is actually happening.
I really wish they'd just stop teaching hypothesis testing.
Entsophy,
I fully agree. I wasn’t proposing that hypothesis testing be patched, I agree that hypothesis testing should not be taught.
My proposal (maybe I was too elliptical in what I said above) is that, since the ostensible goal of hypothesis testing is to take some action (otherwise, what is the point), that the only sensible approach is to consider these problems from the point of view of decision theory. You can’t decide what action you’re going to take without a loss function that tells you how bad each possible action is, in addition to the probabilistic information that comes from the data and the model.
To give an extreme example, consider parapsychology experiments that claim to show that people can “influence” random number generators to produce more 1’s than 0’s. An example I discussed had a p-value of 0.0003 (two-sided), which was claimed to show that this “power” was real. The effect size was 0.00018.
This was based on over 100,000,000 Bernoulli trials.
I happen to think that it is almost certainly not the case that such a power exists, and that any experiment that purports to test this is likely to have defects that are probably orders of magnitude greater than any such effect, if it really exists.
So I ask, “so what?” Even if there were a power to influence a random number generator to such a trivial amount, what difference does it make? Is there any practical application of such a trivial power? The loss for discounting such a trivial power, given that it actually exists, must be very, very small (very small compared to the cost of conducting these tests over a period of at least a decade, with someone else’s money footing the bill). And, how do we know that there were NO experimental defects in the way the experiment was conducted that could explain the results in a mundane way? We do not. Was this study worth publishing? The p-value was <<0.05. But I don't think it was worth publishing.
I think that hypothesis testing should not be taught and should not be used. If a problem is being studied, it is being studied for a reason, and that means that someone is going to take an action based on the outcome of the research. That means that implicitly there is a loss function somewhere. That loss function needs to be elicited, and the research conducted in the light of that information as well as the information obtained from the data and statistical model.
“I think that hypothesis testing should not be taught and should not be used.”
Seriously??
Isn’t that a bit extreme?
I do teach it but I give lots of caveats
about uses ad mis-uses of testing.
In fact, I do that for everything I teach.
Anyway, happy new year
–LW
Seriously. Suppose you do a hypothesis test and get a result. What are you supposed to do with it?
Seriously, what?
well, at the very least, you can invert the test and get a confidence interval
Yes, but I thought you were interested in the truth of the hypothesis. A confidence interval assumes the hypothesis to be true and tells you where data is expected to lie. How is this helpful?
IOW, I am asking how hypothesis testing gives information that is useful to answer the sort of questions that people who use hypothesis testing (as opposed to constructing confidence intervals) want.
Well if you press me on it, I’ll agree that
precise testing problems are rare.
But rare is not the same as non-existent.
In terms of pedagogy, if I don’t teach it to them
they’ll come across it anyway and will then be much
more likely to abuse it.
Fair enough. I can countenance teaching about how such tests can be and are routinely abused. I do this myself.
But as I say, if the goal of doing this sort of thing is to make a decision (approve a drug, say, or any of a large number of things that these tests are used for in practice), they are the wrong tool. If a decision is to be made, use decision theory.
Normaldeviate,
I take it your point is that Bayesianism-in-the-wild will generate similar amounts of nonsense as Frequentism-in-the-wild and that the amount of nonsense is likely unrelated to how the best Bayesians and best Frequentists perform. As far as it goes, this is probably right. Any Bayesian cheer-leading today should be cautioned by that fact that almost everyone from 1950 would be surprised by the publication problems that heavily statistics dependent fields are having today.
Where we would disagree is that you think Frequentist ideas are fundamentally ok and that if everyone stopped making mistakes (such as using low powered tests) then everything would be fine. This is were I disagree strongly. Obviously though, I’m not going to convince anybody here of that, but just out curiosity what great evil do you think will befall the scientific community if instead of teaching students “H0: mu =0 vs H1: mu !=0” they were instead taught to look at the high probability manifold of P(mu : data) to think about mu?
In fact I teach them to use confidence intervals instead of doing tests
I’m not sure if epidemiologists know that ‘most findings are false’. Perhaps it would be more accurate to claim that ‘epidemiologists know that most findings are false, except for theirs’.
Yes, and if you show an epidemiologist two analyses that reach opposite conclusions (e.g. the flap last year over bisphosphonates and esophageal cancer) they will tell you that had they done the analysis theu would have gotten the right answer!
Quick comment on the Ioannidis paper: These criticisms point up the need for better and more genuinely controlled studies, and “better powered evidence”, while implicating flexible designs, inadequate power, multiple testing with selective reporting,data-dependent searching, and a slew of other ways in which statistical and non-statistical assumptions fail: inadequate designs, wishful thinking, financial incentives, people’s beliefs, funding and publication biases and pressures, peer review biases, financial interests, fraud and finagling and whatnot. It speaks to finding ways to successfully apply the “well-conducted, adequately powered randomized controlled trials” underlying legitimate significance tests and statistical modeling, and to a careful scrutiny of assumptions. But these cannot succeed, according to this critique, without more astute use of statistical method (and a variety of checks like registering studies), and perhaps without changing the institutional arrangements that promote/permit invalid statistical analysis.
I’m not sure about his idea of pre-assessing R to advance probative studies (didn’t have time to study it). It’s hard to see how not teaching about error probabilities, power and size, can promote better evidence-based medicine and better powered evidence. A correct scrutiny even of the results of low powered tests avoids alleged non-informative assessments, and other fallacies of acceptance.
Aside: Fisher always lambasted the idea of supposing an experimental effect was shown on the basis of a few significant results (you had to know how to generate results that would rarely fail to be very significant, before you had knowledge of an experimental effect). Of course power is central to N-P tests.
Interesting piece, but I think that you are too dismissive of Ioannidis’s work.
“All good epidemiologists know these things and they regard published findings with suitable caution”. Really?
i don’t agree. We all have suspected that there is a lack of reproducibility, but I for one didn’t realize the magnitude of the problem.
Maybe the problem is worse in genomics than in classical epidemiology.
See for example “Repeatability of published microarray gene expression analyses” , Ioannidis et al Nature Genetics 2010
It’s surprising how few “findings” are reproduced years after their publication. And how people continue to cite papers that have been discredited
or shown to be completely wrong.
We have a big problem!
We I didn’t say “all epidemiologists know this: I said
“all GOOD epidemiologists”
Hopefully this is not the empty set!
Rob, I agree we have a very big problem and I was surprised at the magnitude of the variation in results given arguably sensible variations in analysis methods.
I for one did actually realize the magnitude of the problem for selective publishing and reporting of RCTs (given the flak I initially encountered early in my work on meta-analysis methods for RCTs) and I have been continually disappointed at the slow pace of the adoption of any remedies for RCTs (e.g. trial registration).
I have been tracking this for some time http://andrewgelman.com/2012/02/meta-analysis-game-theory-and-incentives-to-do-replicable-research/
The only effective use of evidence for health care that I am aware of is in regulatory agencies where published studies are strictly interpreted as supportive (i.e. hear say) and only pre-agreed upon studies are taken seriously and sometimes even audited.
Unfortunately, remedies for observational studies are not so clear (as they are much harder to design/anticipate).
Just as a shift of perspective, I want to note (a) the fact is, we do manage to learn about effects that (eventually) do not go away, and build up genuine understanding that is cumulative (while partial), and (b) I suggest it might be constructive to look at how much failure to replicate is behind the majority of success stories. I was rereading one of my very first posts on kuru and advances in understanding prion disease (http://errorstatistics.com/2011/09/09/kuru/). It took Prusiner something like 10 years just to purify a prion cocktail sufficiently to show (statistically) the transmission in animals (while other scientists vilified him for entertaining the heretical idea of infection through protein folding rather than nucleic acid). Another decade or more was needed to learn other and much better ways to bring about results. Starting from success stories, however small, we might ascertain how sporadic and failed replication may be learned from, and how to speed up the process of discerning improved designs and/or dead ends.
People need to make strong statements to sell their work and themselves, and people want to read strong statements because they want to be assured and they’re happy if they can shift responsibility to some scientific authority when making decisions. Therefore people want to milk their results as much as they can and overinterpretations are rather the rule than the exception. That’s a general problem in science, not specifically with hypothesis tests.
I think that the basic idea of hypothesis tests is clear and intuitive, and in fact it’s very old (compared with pretty much all the other things we do in statistics). Can we distinguish what happened from a model for “nothing remarkable is going on, just random variation” by the data at hand? If not, it should be clear that this doesn’t mean that *really* nothing is going on (I think the basic problem with this is that many people can’t handle double negations), but it *does* mean that the data won’t back up making more of them than random variation, and if significance is found, it should be as clear, that “something is probably going on” alone is not very strong a statement and one should be interested in effect sizes and replicability. It really doesn’t look very obscure to me, were it not for the more political and psychological reasons given above.
Yes Laplace used these kinds of ideas to detect signals in noise and applied them to Astronomy several hundred years ago. Oddly his published astronomical discoveries seemed to suffer nothing like the 50% error rate that we see today.
Just out of curiosity does anyone know how much time Laplace spent controlling the power of his tests and ensuring that he used powerful tests? Surely at the early date using a clearly bogus philosophy of statistics (Essai philosophique sur les probabilités 1814) he must have been tripped up by this all the time unless he spent a great deal of trouble avoiding that pitfall.
Laplace didn’t have to deal with measurements
on 50,000 genes or 1,000,000,000 galaxies
as in the Sloan survey.
Are you saying that lots of measurements are a problem for statistics and liable to trip statisticians up?
no I am just saying that statistics is much harder than in Laplace’s day
I don’t think that’s it. If you’re combing measurements from different observatories with different instruments, weird things can happen which don’t show up in the usual text book “equal variance” case. The easiest way to see this is to consider one measurement which is far more accurate than the others (small variance). C.I.’s will become complete nonsense, while the naive Bayes answer will do exactly the right thing and automatically base the answer on the accurate data point. (incidentally, this is a real world example of that xkcd cartoon you railed against: one extremely accurate measurement effectively makes the others about as relevant as the two dice, but CI’s will nevertheless be dominated by them)
In a less extreme case this may not be so obvious and the only way Frequentist would detect the error is if they did a power calculation. Laplace avoided all this completely with a simple Bayesian calculation that never needs any special notice of the power. That’s why he wasn’t tripped up.
Things are much more complicated today. A while back Christian Robert posted a lecture about using Bayesian models for weather prediction. These models are extraordinarily complicated and combine staggering amounts of measurements and physics. It’s hard to imagine applying the arsenal of Frequentists methods to do something similar, but suppose for the sake of argument that there was an equivalent Frequentist model.
If you had a Frequentist version of this massive weather model, you’d have to do an impossible number of power calculations to ensure you weren’t falling into a more complication version of the trap described above! So I don’t see how using methods that would have already tripped up Laplace’s simple examples would help in any way whatsoever.
The Cox example of two measurements does not make CI’s nonsense.
And people (like me for example) do frequentist analyses
of massively complicated problems all the time.
But you and I will never agree on this so I suggest
we just agree to disagree.
Best wishes for a New year
3 Trackbacks
[…] seen a talk recently by John Ioannidis on how medical research is (often) bunk, this finer corrective by Larry Wasserman was nice to […]
[…] be false even if they are published in a top notch peer reviewed journal (see for example here or here). (I do recall the incident a couple of years ago when the Chen-Zhang q-factor papers became […]
[…] few months ago I posted about John Ioannidis’ article called “Why Most Published Research Findings Are […]